 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizable Multimodal Large Language Model Editing via Invariant Trajectory Learning
Jan 30, 2026Knowledge editing emerges as a crucial technique for efficiently correcting incorrect or outdated knowledge in large language models (LLM). Existing editing methods rely on a rigid mapping from parameter or module modifications to output, which causes the generalization limitation in Multimodal LLM (MLLM). In this paper, we reformulate MLLM editing as an out-of-distribution (OOD) generalization problem, where the goal is to discern semantic shift with factual shift and thus achieve robust editing among diverse cross-modal prompting. The key challenge of this OOD problem lies in identifying invariant causal trajectories that generalize accurately while suppressing spurious correlations. To address it, we propose ODEdit, a plug-and-play invariant learning based framework that optimizes the tripartite OOD risk objective to simultaneously enhance editing reliability, locality, and generality.We further introduce an edit trajectory invariant learning method, which integrates a total variation penalty into the risk minimization objective to stabilize edit trajectories against environmental variations. Theoretical analysis and extensive experiments demonstrate the effectiveness of ODEdit.
PhysRVG: Physics-Aware Unified Reinforcement Learning for Video Generative Models
Jan 16, 2026Physical principles are fundamental to realistic visual simulation, but remain a significant oversight in transformer-based video generation. This gap highlights a critical limitation in rendering rigid body motion, a core tenet of classical mechanics. While computer graphics and physics-based simulators can easily model such collisions using Newton formulas, modern pretrain-finetune paradigms discard the concept of object rigidity during pixel-level global denoising. Even perfectly correct mathematical constraints are treated as suboptimal solutions (i.e., conditions) during model optimization in post-training, fundamentally limiting the physical realism of generated videos. Motivated by these considerations, we introduce, for the first time, a physics-aware reinforcement learning paradigm for video generation models that enforces physical collision rules directly in high-dimensional spaces, ensuring the physics knowledge is strictly applied rather than treated as conditions. Subsequently, we extend this paradigm to a unified framework, termed Mimicry-Discovery Cycle (MDcycle), which allows substantial fine-tuning while fully preserving the model's ability to leverage physics-grounded feedback. To validate our approach, we construct new benchmark PhysRVGBench and perform extensive qualitative and quantitative experiments to thoroughly assess its effectiveness.
Bridging the Copyright Gap: Do Large Vision-Language Models Recognize and Respect Copyrighted Content?
Dec 26, 2025Large vision-language models (LVLMs) have achieved remarkable advancements in multimodal reasoning tasks. However, their widespread accessibility raises critical concerns about potential copyright infringement. Will LVLMs accurately recognize and comply with copyright regulations when encountering copyrighted content (i.e., user input, retrieved documents) in the context? Failure to comply with copyright regulations may lead to serious legal and ethical consequences, particularly when LVLMs generate responses based on copyrighted materials (e.g., retrieved book experts, news reports). In this paper, we present a comprehensive evaluation of various LVLMs, examining how they handle copyrighted content -- such as book excerpts, news articles, music lyrics, and code documentation when they are presented as visual inputs. To systematically measure copyright compliance, we introduce a large-scale benchmark dataset comprising 50,000 multimodal query-content pairs designed to evaluate how effectively LVLMs handle queries that could lead to copyright infringement. Given that real-world copyrighted content may or may not include a copyright notice, the dataset includes query-content pairs in two distinct scenarios: with and without a copyright notice. For the former, we extensively cover four types of copyright notices to account for different cases. Our evaluation reveals that even state-of-the-art closed-source LVLMs exhibit significant deficiencies in recognizing and respecting the copyrighted content, even when presented with the copyright notice. To solve this limitation, we introduce a novel tool-augmented defense framework for copyright compliance, which reduces infringement risks in all scenarios. Our findings underscore the importance of developing copyright-aware LVLMs to ensure the responsible and lawful use of copyrighted content.
FedFACT: A Provable Framework for Controllable Group-Fairness Calibration in Federated Learning
Jun 04, 2025



With emerging application of Federated Learning (FL) in decision-making scenarios, it is imperative to regulate model fairness to prevent disparities across sensitive groups (e.g., female, male). Current research predominantly focuses on two concepts of group fairness within FL: Global Fairness (overall model disparity across all clients) and Local Fairness (the disparity within each client). However, the non-decomposable, non-differentiable nature of fairness criteria pose two fundamental, unresolved challenges for fair FL: (i) Harmonizing global and local fairness in multi-class classification; (ii) Enabling a controllable, optimal accuracy-fairness trade-off. To tackle the aforementioned challenges, we propose a novel controllable federated group-fairness calibration framework, named FedFACT. FedFACT identifies the Bayes-optimal classifiers under both global and local fairness constraints in multi-class case, yielding models with minimal performance decline while guaranteeing fairness. To effectively realize an adjustable, optimal accuracy-fairness balance, we derive specific characterizations of the Bayes-optimal fair classifiers for reformulating fair FL as personalized cost-sensitive learning problem for in-processing, and bi-level optimization for post-processing. Theoretically, we provide convergence and generalization guarantees for FedFACT to approach the near-optimal accuracy under given fairness levels. Extensive experiments on multiple datasets across various data heterogeneity demonstrate that FedFACT consistently outperforms baselines in balancing accuracy and global-local fairness.
RAID: An In-Training Defense against Attribute Inference Attacks in Recommender Systems
Apr 15, 2025In various networks and mobile applications, users are highly susceptible to attribute inference attacks, with particularly prevalent occurrences in recommender systems. Attackers exploit partially exposed user profiles in recommendation models, such as user embeddings, to infer private attributes of target users, such as gender and political views. The goal of defenders is to mitigate the effectiveness of these attacks while maintaining recommendation performance. Most existing defense methods, such as differential privacy and attribute unlearning, focus on post-training settings, which limits their capability of utilizing training data to preserve recommendation performance. Although adversarial training extends defenses to in-training settings, it often struggles with convergence due to unstable training processes. In this paper, we propose RAID, an in-training defense method against attribute inference attacks in recommender systems. In addition to the recommendation objective, we define a defensive objective to ensure that the distribution of protected attributes becomes independent of class labels, making users indistinguishable from attribute inference attacks. Specifically, this defensive objective aims to solve a constrained Wasserstein barycenter problem to identify the centroid distribution that makes the attribute indistinguishable while complying with recommendation performance constraints. To optimize our proposed objective, we use optimal transport to align users with the centroid distribution. We conduct extensive experiments on four real-world datasets to evaluate RAID. The experimental results validate the effectiveness of RAID and demonstrate its significant superiority over existing methods in multiple aspects.
A Neuro-inspired Interpretation of Unlearning in Large Language Models through Sample-level Unlearning Difficulty
Apr 09, 2025Driven by privacy protection laws and regulations, unlearning in Large Language Models (LLMs) is gaining increasing attention. However, current research often neglects the interpretability of the unlearning process, particularly concerning sample-level unlearning difficulty. Existing studies typically assume a uniform unlearning difficulty across samples. This simplification risks attributing the performance of unlearning algorithms to sample selection rather than the algorithm's design, potentially steering the development of LLM unlearning in the wrong direction. Thus, we investigate the relationship between LLM unlearning and sample characteristics, with a focus on unlearning difficulty. Drawing inspiration from neuroscience, we propose a Memory Removal Difficulty ($\mathrm{MRD}$) metric to quantify sample-level unlearning difficulty. Using $\mathrm{MRD}$, we analyze the characteristics of hard-to-unlearn versus easy-to-unlearn samples. Furthermore, we propose an $\mathrm{MRD}$-based weighted sampling method to optimize existing unlearning algorithms, which prioritizes easily forgettable samples, thereby improving unlearning efficiency and effectiveness. We validate the proposed metric and method using public benchmarks and datasets, with results confirming its effectiveness.
Bridging the Gap Between Preference Alignment and Machine Unlearning
Apr 09, 2025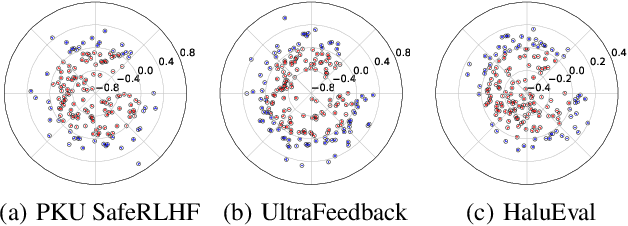
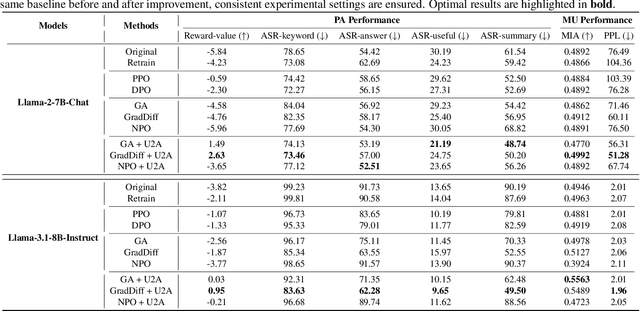
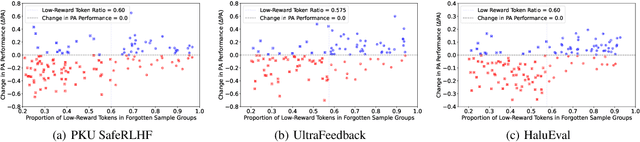

Despite advances in Preference Alignment (PA) for Large Language Models (LLMs), mainstream methods like Reinforcement Learning with Human Feedback (RLHF) face notable challenges. These approaches require high-quality datasets of positive preference examples, which are costly to obtain and computationally intensive due to training instability, limiting their use in low-resource scenarios. LLM unlearning technique presents a promising alternative, by directly removing the influence of negative examples. However, current research has primarily focused on empirical validation, lacking systematic quantitative analysis. To bridge this gap, we propose a framework to explore the relationship between PA and LLM unlearning. Specifically, we introduce a bi-level optimization-based method to quantify the impact of unlearning specific negative examples on PA performance. Our analysis reveals that not all negative examples contribute equally to alignment improvement when unlearned, and the effect varies significantly across examples. Building on this insight, we pose a crucial question: how can we optimally select and weight negative examples for unlearning to maximize PA performance? To answer this, we propose a framework called Unlearning to Align (U2A), which leverages bi-level optimization to efficiently select and unlearn examples for optimal PA performance. We validate the proposed method through extensive experiments, with results confirming its effectiveness.
Reproducibility Companion Paper: Making Users Indistinguishable: Attribute-wise Unlearning in Recommender Systems
Mar 29, 2025In this paper, we reproduce the experimental results presented in our previous work titled "Making Users Indistinguishable: Attribute-wise Unlearning in Recommender Systems," which was published in the proceedings of the 31st ACM International Conference on Multimedia. This paper aims to validate the effectiveness of our proposed method and help others reproduce our experimental results. We provide detailed descriptions of our preprocessed datasets, source code structure, configuration file settings, experimental environment, and reproduced experimental results.
Reproducibility Companion Paper:In-processing User Constrained Dominant Sets for User-Oriented Fairness in Recommender Systems
Mar 29, 2025In this paper, we reproduce experimental results presented in our earlier work titled "In-processing User Constrained Dominant Sets for User-Oriented Fairness in Recommender Systems" that was presented in the proceeding of the 31st ACM International Conference on Multimedia.This work aims to verify the effectiveness of our previously proposed method and provide guidance for reproducibility. We present detailed descriptions of our preprocessed datasets, the structure of our source code, configuration file settings, experimental environment, and the reproduced experimental results.
A Survey on Recommendation Unlearning: Fundamentals, Taxonomy, Evaluation, and Open Questions
Dec 17, 2024



Recommender systems have become increasingly influential in shaping user behavior and decision-making, highlighting their growing impact in various domains. Meanwhile, the widespread adoption of machine learning models in recommender systems has raised significant concerns regarding user privacy and security. As compliance with privacy regulations becomes more critical, there is a pressing need to address the issue of recommendation unlearning, i.e., eliminating the memory of specific training data from the learned recommendation models. Despite its importance, traditional machine unlearning methods are ill-suited for recommendation unlearning due to the unique challenges posed by collaborative interactions and model parameters. This survey offers a comprehensive review of the latest advancements in recommendation unlearning, exploring the design principles, challenges, and methodologies associated with this emerging field. We provide a unified taxonomy that categorizes different recommendation unlearning approaches, followed by a summary of widely used benchmarks and metrics for evaluation. By reviewing the current state of research, this survey aims to guide the development of more efficient, scalable, and robust recommendation unlearning techniques. Furthermore, we identify open research questions in this field, which could pave the way for future innovations not only in recommendation unlearning but also in a broader range of unlearning tasks across different machine learning applications.