 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRISM: Personalized Recommendation via Information Synergy Module
Jan 16, 2026Multimodal sequential recommendation (MSR) leverages diverse item modalities to improve recommendation accuracy, while achieving effective and adaptive fusion remains challenging. Existing MSR models often overlook synergistic information that emerges only through modality combinations. Moreover, they typically assume a fixed importance for different modality interactions across users. To address these limitations, we propose \textbf{P}ersonalized \textbf{R}ecommend-ation via \textbf{I}nformation \textbf{S}ynergy \textbf{M}odule (PRISM), a plug-and-play framework for sequential recommendation (SR). PRISM explicitly decomposes multimodal information into unique, redundant, and synergistic components through an Interaction Expert Layer and dynamically weights them via an Adaptive Fusion Layer guided by user preferences. This information-theoretic design enables fine-grained disentanglement and personalized fusion of multimodal signals. Extensive experiments on four datasets and three SR backbones demonstrate its effectiveness and versatility. The code is available at https://github.com/YutongLi2024/PRISM.
OxygenREC: An Instruction-Following Generative Framework for E-commerce Recommendation
Dec 31, 2025Traditional recommendation systems suffer from inconsistency in multi-stage optimization objectives. Generative Recommendation (GR) mitigates them through an end-to-end framework; however, existing methods still rely on matching mechanisms based on inductive patterns. Although responsive, they lack the ability to uncover complex user intents that require deductive reasoning based on world knowledge. Meanwhile, LLMs show strong deep reasoning capabilities, but their latency and computational costs remain challenging for industrial applications. More critically, there are performance bottlenecks in multi-scenario scalability: as shown in Figure 1, existing solutions require independent training and deployment for each scenario, leading to low resource utilization and high maintenance costs-a challenge unaddressed in GR literature. To address these, we present OxygenREC, an industrial recommendation system that leverages Fast-Slow Thinking to deliver deep reasoning with strict latency and multi-scenario requirements of real-world environments. First, we adopt a Fast-Slow Thinking architecture. Slow thinking uses a near-line LLM pipeline to synthesize Contextual Reasoning Instructions, while fast thinking employs a high-efficiency encoder-decoder backbone for real-time generation. Second, to ensure reasoning instructions effectively enhance recommendation generation, we introduce a semantic alignment mechanism with Instruction-Guided Retrieval (IGR) to filter intent-relevant historical behaviors and use a Query-to-Item (Q2I) loss for instruction-item consistency. Finally, to resolve multi-scenario scalability, we transform scenario information into controllable instructions, using unified reward mapping and Soft Adaptive Group Clip Policy Optimization (SA-GCPO) to align policies with diverse business objectives, realizing a train-once-deploy-everywhere paradigm.
FedFACT: A Provable Framework for Controllable Group-Fairness Calibration in Federated Learning
Jun 04, 2025



With emerging application of Federated Learning (FL) in decision-making scenarios, it is imperative to regulate model fairness to prevent disparities across sensitive groups (e.g., female, male). Current research predominantly focuses on two concepts of group fairness within FL: Global Fairness (overall model disparity across all clients) and Local Fairness (the disparity within each client). However, the non-decomposable, non-differentiable nature of fairness criteria pose two fundamental, unresolved challenges for fair FL: (i) Harmonizing global and local fairness in multi-class classification; (ii) Enabling a controllable, optimal accuracy-fairness trade-off. To tackle the aforementioned challenges, we propose a novel controllable federated group-fairness calibration framework, named FedFACT. FedFACT identifies the Bayes-optimal classifiers under both global and local fairness constraints in multi-class case, yielding models with minimal performance decline while guaranteeing fairness. To effectively realize an adjustable, optimal accuracy-fairness balance, we derive specific characterizations of the Bayes-optimal fair classifiers for reformulating fair FL as personalized cost-sensitive learning problem for in-processing, and bi-level optimization for post-processing. Theoretically, we provide convergence and generalization guarantees for FedFACT to approach the near-optimal accuracy under given fairness levels. Extensive experiments on multiple datasets across various data heterogeneity demonstrate that FedFACT consistently outperforms baselines in balancing accuracy and global-local fairness.
Reproducibility Companion Paper:In-processing User Constrained Dominant Sets for User-Oriented Fairness in Recommender Systems
Mar 29, 2025In this paper, we reproduce experimental results presented in our earlier work titled "In-processing User Constrained Dominant Sets for User-Oriented Fairness in Recommender Systems" that was presented in the proceeding of the 31st ACM International Conference on Multimedia.This work aims to verify the effectiveness of our previously proposed method and provide guidance for reproducibility. We present detailed descriptions of our preprocessed datasets, the structure of our source code, configuration file settings, experimental environment, and the reproduced experimental results.
Reproducibility Companion Paper: Making Users Indistinguishable: Attribute-wise Unlearning in Recommender Systems
Mar 29, 2025In this paper, we reproduce the experimental results presented in our previous work titled "Making Users Indistinguishable: Attribute-wise Unlearning in Recommender Systems," which was published in the proceedings of the 31st ACM International Conference on Multimedia. This paper aims to validate the effectiveness of our proposed method and help others reproduce our experimental results. We provide detailed descriptions of our preprocessed datasets, source code structure, configuration file settings, experimental environment, and reproduced experimental results.
LoGoFair: Post-Processing for Local and Global Fairness in Federated Learning
Mar 21, 2025Federated learning (FL) has garnered considerable interest for its capability to learn from decentralized data sources. Given the increasing application of FL in decision-making scenarios, addressing fairness issues across different sensitive groups (e.g., female, male) in FL is crucial. Current research often focuses on facilitating fairness at each client's data (local fairness) or within the entire dataset across all clients (global fairness). However, existing approaches that focus exclusively on either local or global fairness fail to address two key challenges: (\textbf{CH1}) Under statistical heterogeneity, global fairness does not imply local fairness, and vice versa. (\textbf{CH2}) Achieving fairness under model-agnostic setting. To tackle the aforementioned challenges, this paper proposes a novel post-processing framework for achieving both Local and Global Fairness in the FL context, namely LoGoFair. To address CH1, LoGoFair endeavors to seek the Bayes optimal classifier under local and global fairness constraints, which strikes the optimal accuracy-fairness balance in the probabilistic sense. To address CH2, LoGoFair employs a model-agnostic federated post-processing procedure that enables clients to collaboratively optimize global fairness while ensuring local fairness, thereby achieving the optimal fair classifier within FL. Experimental results on three real-world datasets further illustrate the effectiveness of the proposed LoGoFair framework.
WassFFed: Wasserstein Fair Federated Learning
Nov 11, 2024



Federated Learning (FL) employs a training approach to address scenarios where users' data cannot be shared across clients. Achieving fairness in FL is imperative since training data in FL is inherently geographically distributed among diverse user groups. Existing research on fairness predominantly assumes access to the entire training data, making direct transfer to FL challenging. However, the limited existing research on fairness in FL does not effectively address two key challenges, i.e., (CH1) Current methods fail to deal with the inconsistency between fair optimization results obtained with surrogate functions and fair classification results. (CH2) Directly aggregating local fair models does not always yield a globally fair model due to non Identical and Independent data Distributions (non-IID) among clients. To address these challenges, we propose a Wasserstein Fair Federated Learning framework, namely WassFFed. To tackle CH1, we ensure that the outputs of local models, rather than the loss calculated with surrogate functions or classification results with a threshold, remain independent of various user groups. To resolve CH2, we employ a Wasserstein barycenter calculation of all local models' outputs for each user group, bringing local model outputs closer to the global output distribution to ensure consistency between the global model and local models. We conduct extensive experiments on three real-world datasets, demonstrating that WassFFed outperforms existing approaches in striking a balance between accuracy and fairness.
Making Users Indistinguishable: Attribute-wise Unlearning in Recommender Systems
Oct 06, 2023
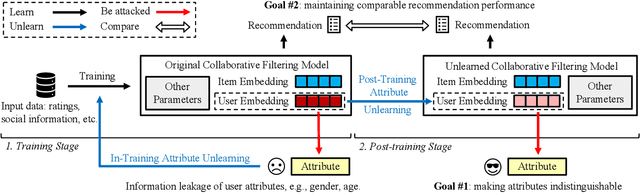
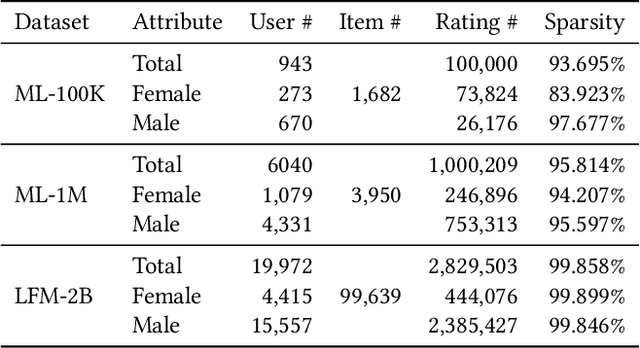
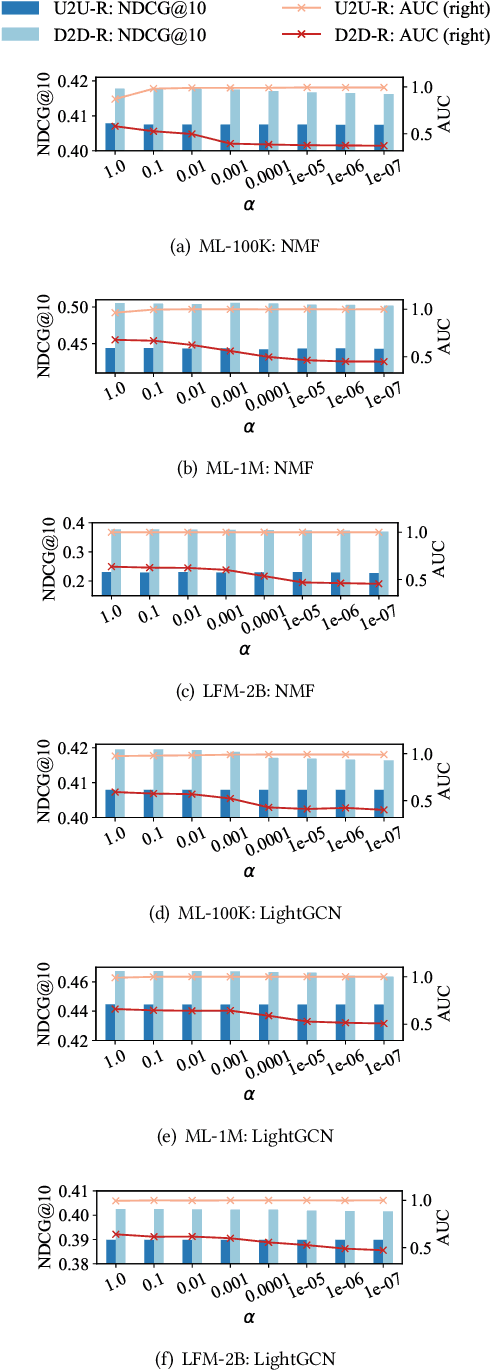
With the growing privacy concerns in recommender systems, recommendation unlearning, i.e., forgetting the impact of specific learned targets, is getting increasing attention. Existing studies predominantly use training data, i.e., model inputs, as the unlearning target. However, we find that attackers can extract private information, i.e., gender, race, and age, from a trained model even if it has not been explicitly encountered during training. We name this unseen information as attribute and treat it as the unlearning target. To protect the sensitive attribute of users, Attribute Unlearning (AU) aims to degrade attacking performance and make target attributes indistinguishable. In this paper, we focus on a strict but practical setting of AU, namely Post-Training Attribute Unlearning (PoT-AU), where unlearning can only be performed after the training of the recommendation model is completed. To address the PoT-AU problem in recommender systems, we design a two-component loss function that consists of i) distinguishability loss: making attribute labels indistinguishable from attackers, and ii) regularization loss: preventing drastic changes in the model that result in a negative impact on recommendation performance. Specifically, we investigate two types of distinguishability measurements, i.e., user-to-user and distribution-to-distribution. We use the stochastic gradient descent algorithm to optimize our proposed loss. Extensive experiments on three real-world datasets demonstrate the effectiveness of our proposed methods.
In-processing User Constrained Dominant Sets for User-Oriented Fairness in Recommender Systems
Sep 04, 2023



Recommender systems are typically biased toward a small group of users, leading to severe unfairness in recommendation performance, i.e., User-Oriented Fairness (UOF) issue. The existing research on UOF is limited and fails to deal with the root cause of the UOF issue: the learning process between advantaged and disadvantaged users is unfair. To tackle this issue, we propose an In-processing User Constrained Dominant Sets (In-UCDS) framework, which is a general framework that can be applied to any backbone recommendation model to achieve user-oriented fairness. We split In-UCDS into two stages, i.e., the UCDS modeling stage and the in-processing training stage. In the UCDS modeling stage, for each disadvantaged user, we extract a constrained dominant set (a user cluster) containing some advantaged users that are similar to it. In the in-processing training stage, we move the representations of disadvantaged users closer to their corresponding cluster by calculating a fairness loss. By combining the fairness loss with the original backbone model loss, we address the UOF issue and maintain the overall recommendation performance simultaneously. Comprehensive experiments on three real-world datasets demonstrate that In-UCDS outperforms the state-of-the-art methods, leading to a fairer model with better overall recommendation performance.
Heterogeneous Information Crossing on Graphs for Session-based Recommender Systems
Oct 24, 2022

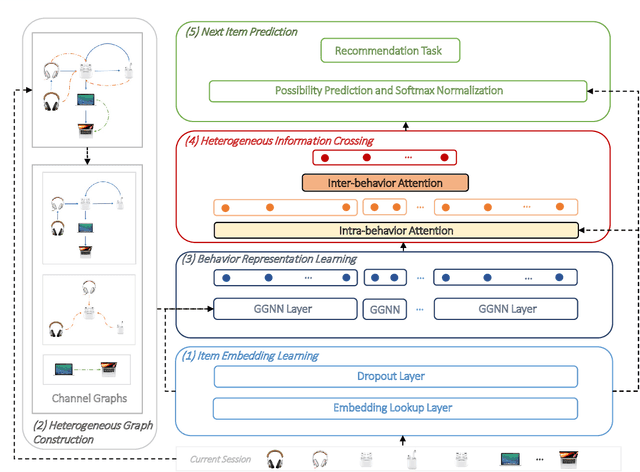

Recommender systems are fundamental information filtering techniques to recommend content or items that meet users' personalities and potential needs. As a crucial solution to address the difficulty of user identification and unavailability of historical information, session-based recommender systems provide recommendation services that only rely on users' behaviors in the current session. However, most existing studies are not well-designed for modeling heterogeneous user behaviors and capturing the relationships between them in practical scenarios. To fill this gap, in this paper, we propose a novel graph-based method, namely Heterogeneous Information Crossing on Graphs (HICG). HICG utilizes multiple types of user behaviors in the sessions to construct heterogeneous graphs, and captures users' current interests with their long-term preferences by effectively crossing the heterogeneous information on the graphs. In addition, we also propose an enhanced version, named HICG-CL, which incorporates contrastive learning (CL) technique to enhance item representation ability. By utilizing the item co-occurrence relationships across different sessions, HICG-CL improves the recommendation performance of HICG. We conduct extensive experiments on three real-world recommendation datasets, and the results verify that (i) HICG achieves the state-of-the-art performance by utilizing multiple types of behaviors on the heterogeneous graph. (ii) HICG-CL further significantly improves the recommendation performance of HICG by the proposed contrastive learning module.