 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePADER: Paillier-based Secure Decentralized Social Recommendation
Jan 15, 2026The prevalence of recommendation systems also brings privacy concerns to both the users and the sellers, as centralized platforms collect as much data as possible from them. To keep the data private, we propose PADER: a Paillier-based secure decentralized social recommendation system. In this system, the users and the sellers are nodes in a decentralized network. The training and inference of the recommendation model are carried out securely in a decentralized manner, without the involvement of a centralized platform. To this end, we apply the Paillier cryptosystem to the SoReg (Social Regularization) model, which exploits both user's ratings and social relations. We view the SoReg model as a two-party secure polynomial evaluation problem and observe that the simple bipartite computation may result in poor efficiency. To improve efficiency, we design secure addition and multiplication protocols to support secure computation on any arithmetic circuit, along with an optimal data packing scheme that is suitable for the polynomial computations of real values. Experiment results show that our method only takes about one second to iterate through one user with hundreds of ratings, and training with ~500K ratings for one epoch only takes <3 hours, which shows that the method is practical in real applications. The code is available at https://github.com/GarminQ/PADER.
Searth Transformer: A Transformer Architecture Incorporating Earth's Geospheric Physical Priors for Global Mid-Range Weather Forecasting
Jan 14, 2026Accurate global medium-range weather forecasting is fundamental to Earth system science. Most existing Transformer-based forecasting models adopt vision-centric architectures that neglect the Earth's spherical geometry and zonal periodicity. In addition, conventional autoregressive training is computationally expensive and limits forecast horizons due to error accumulation. To address these challenges, we propose the Shifted Earth Transformer (Searth Transformer), a physics-informed architecture that incorporates zonal periodicity and meridional boundaries into window-based self-attention for physically consistent global information exchange. We further introduce a Relay Autoregressive (RAR) fine-tuning strategy that enables learning long-range atmospheric evolution under constrained memory and computational budgets. Based on these methods, we develop YanTian, a global medium-range weather forecasting model. YanTian achieves higher accuracy than the high-resolution forecast of the European Centre for Medium-Range Weather Forecasts and performs competitively with state-of-the-art AI models at one-degree resolution, while requiring roughly 200 times lower computational cost than standard autoregressive fine-tuning. Furthermore, YanTian attains a longer skillful forecast lead time for Z500 (10.3 days) than HRES (9 days). Beyond weather forecasting, this work establishes a robust algorithmic foundation for predictive modeling of complex global-scale geophysical circulation systems, offering new pathways for Earth system science.
Copula-based mixture model identification for subgroup clustering with imaging applications
Feb 12, 2025
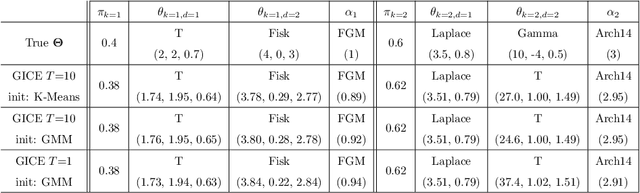
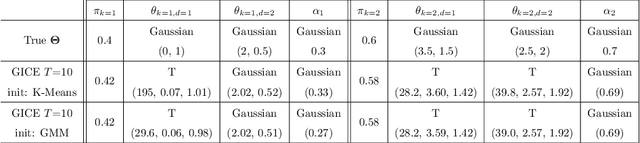

Model-based clustering techniques have been widely applied to various application areas, while most studies focus on canonical mixtures with unique component distribution form. However, this strict assumption is often hard to satisfy. In this paper, we consider the more flexible Copula-Based Mixture Models (CBMMs) for clustering, which allow heterogeneous component distributions composed by flexible choices of marginal and copula forms. More specifically, we propose an adaptation of the Generalized Iterative Conditional Estimation (GICE) algorithm to identify the CBMMs in an unsupervised manner, where the marginal and copula forms and their parameters are estimated iteratively. GICE is adapted from its original version developed for switching Markov model identification with the choice of realization time. Our CBMM-GICE clustering method is then tested on synthetic two-cluster data (N=2000 samples) with discussion of the factors impacting its convergence. Finally, it is compared to the Expectation Maximization identified mixture models with unique component form on the entire MNIST database (N=70000), and on real cardiac magnetic resonance data (N=276) to illustrate its value for imaging applications.
WassFFed: Wasserstein Fair Federated Learning
Nov 11, 2024



Federated Learning (FL) employs a training approach to address scenarios where users' data cannot be shared across clients. Achieving fairness in FL is imperative since training data in FL is inherently geographically distributed among diverse user groups. Existing research on fairness predominantly assumes access to the entire training data, making direct transfer to FL challenging. However, the limited existing research on fairness in FL does not effectively address two key challenges, i.e., (CH1) Current methods fail to deal with the inconsistency between fair optimization results obtained with surrogate functions and fair classification results. (CH2) Directly aggregating local fair models does not always yield a globally fair model due to non Identical and Independent data Distributions (non-IID) among clients. To address these challenges, we propose a Wasserstein Fair Federated Learning framework, namely WassFFed. To tackle CH1, we ensure that the outputs of local models, rather than the loss calculated with surrogate functions or classification results with a threshold, remain independent of various user groups. To resolve CH2, we employ a Wasserstein barycenter calculation of all local models' outputs for each user group, bringing local model outputs closer to the global output distribution to ensure consistency between the global model and local models. We conduct extensive experiments on three real-world datasets, demonstrating that WassFFed outperforms existing approaches in striking a balance between accuracy and fairness.
Input Reconstruction Attack against Vertical Federated Large Language Models
Nov 07, 2023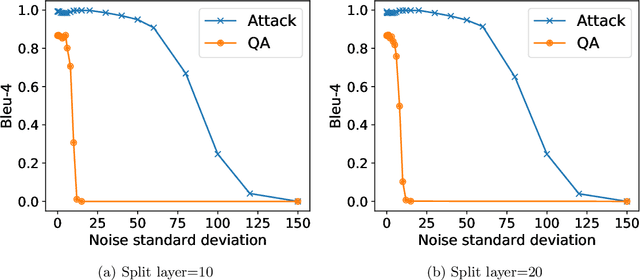
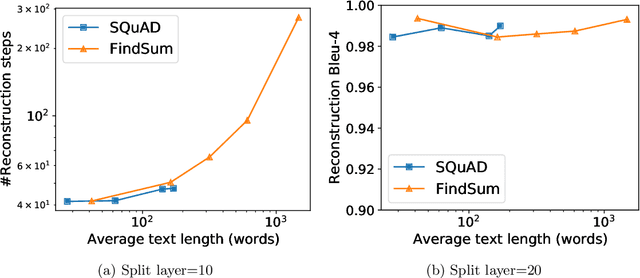
Recently, large language models (LLMs) have drawn extensive attention from academia and the public, due to the advent of the ChatGPT. While LLMs show their astonishing ability in text generation for various tasks, privacy concerns limit their usage in real-life businesses. More specifically, either the user's inputs (the user sends the query to the model-hosting server) or the model (the user downloads the complete model) itself will be revealed during the usage. Vertical federated learning (VFL) is a promising solution to this kind of problem. It protects both the user's input and the knowledge of the model by splitting the model into a bottom part and a top part, which is maintained by the user and the model provider, respectively. However, in this paper, we demonstrate that in LLMs, VFL fails to protect the user input since it is simple and cheap to reconstruct the input from the intermediate embeddings. Experiments show that even with a commercial GPU, the input sentence can be reconstructed in only one second. We also discuss several possible solutions to enhance the privacy of vertical federated LLMs.
Toward ground-truth optical coherence tomography via three-dimensional unsupervised deep learning processing and data
Nov 07, 2023



Optical coherence tomography (OCT) can perform non-invasive high-resolution three-dimensional (3D) imaging and has been widely used in biomedical fields, while it is inevitably affected by coherence speckle noise which degrades OCT imaging performance and restricts its applications. Here we present a novel speckle-free OCT imaging strategy, named toward-ground-truth OCT (tGT-OCT), that utilizes unsupervised 3D deep-learning processing and leverages OCT 3D imaging features to achieve speckle-free OCT imaging. Specifically, our proposed tGT-OCT utilizes an unsupervised 3D-convolution deep-learning network trained using random 3D volumetric data to distinguish and separate speckle from real structures in 3D imaging volumetric space; moreover, tGT-OCT effectively further reduces speckle noise and reveals structures that would otherwise be obscured by speckle noise while preserving spatial resolution. Results derived from different samples demonstrated the high-quality speckle-free 3D imaging performance of tGT-OCT and its advancement beyond the previous state-of-the-art.
Defending Label Inference Attacks in Split Learning under Regression Setting
Aug 18, 2023



As a privacy-preserving method for implementing Vertical Federated Learning, Split Learning has been extensively researched. However, numerous studies have indicated that the privacy-preserving capability of Split Learning is insufficient. In this paper, we primarily focus on label inference attacks in Split Learning under regression setting, which are mainly implemented through the gradient inversion method. To defend against label inference attacks, we propose Random Label Extension (RLE), where labels are extended to obfuscate the label information contained in the gradients, thereby preventing the attacker from utilizing gradients to train an attack model that can infer the original labels. To further minimize the impact on the original task, we propose Model-based adaptive Label Extension (MLE), where original labels are preserved in the extended labels and dominate the training process. The experimental results show that compared to the basic defense methods, our proposed defense methods can significantly reduce the attack model's performance while preserving the original task's performance.
Federated Learning on Non-iid Data via Local and Global Distillation
Jun 26, 2023



Most existing federated learning algorithms are based on the vanilla FedAvg scheme. However, with the increase of data complexity and the number of model parameters, the amount of communication traffic and the number of iteration rounds for training such algorithms increases significantly, especially in non-independently and homogeneously distributed scenarios, where they do not achieve satisfactory performance. In this work, we propose FedND: federated learning with noise distillation. The main idea is to use knowledge distillation to optimize the model training process. In the client, we propose a self-distillation method to train the local model. In the server, we generate noisy samples for each client and use them to distill other clients. Finally, the global model is obtained by the aggregation of local models. Experimental results show that the algorithm achieves the best performance and is more communication-efficient than state-of-the-art methods.
Reducing Communication for Split Learning by Randomized Top-k Sparsification
May 29, 2023

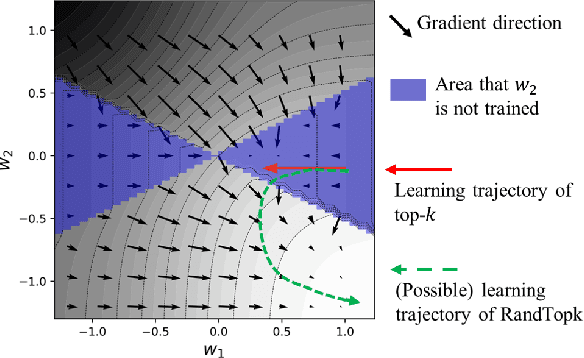
Split learning is a simple solution for Vertical Federated Learning (VFL), which has drawn substantial attention in both research and application due to its simplicity and efficiency. However, communication efficiency is still a crucial issue for split learning. In this paper, we investigate multiple communication reduction methods for split learning, including cut layer size reduction, top-k sparsification, quantization, and L1 regularization. Through analysis of the cut layer size reduction and top-k sparsification, we further propose randomized top-k sparsification, to make the model generalize and converge better. This is done by selecting top-k elements with a large probability while also having a small probability to select non-top-k elements. Empirical results show that compared with other communication-reduction methods, our proposed randomized top-k sparsification achieves a better model performance under the same compression level.
Making Split Learning Resilient to Label Leakage by Potential Energy Loss
Oct 18, 2022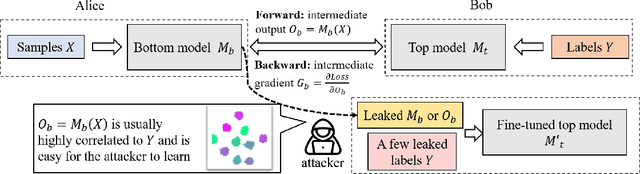
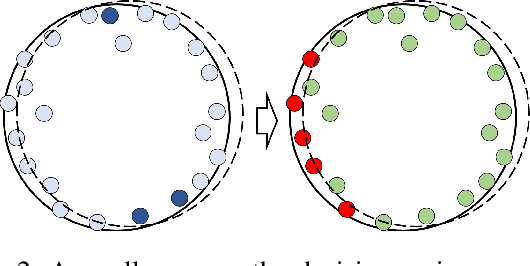
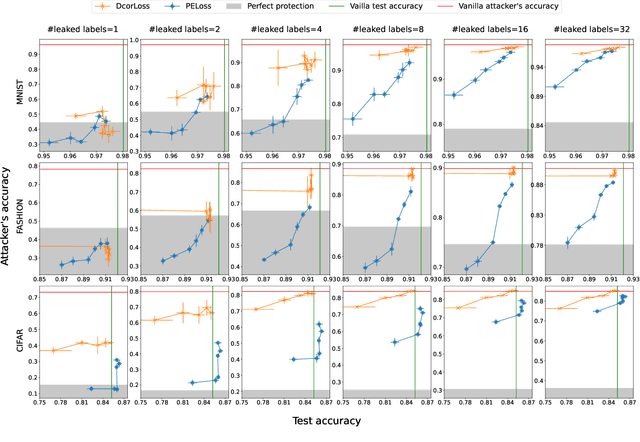
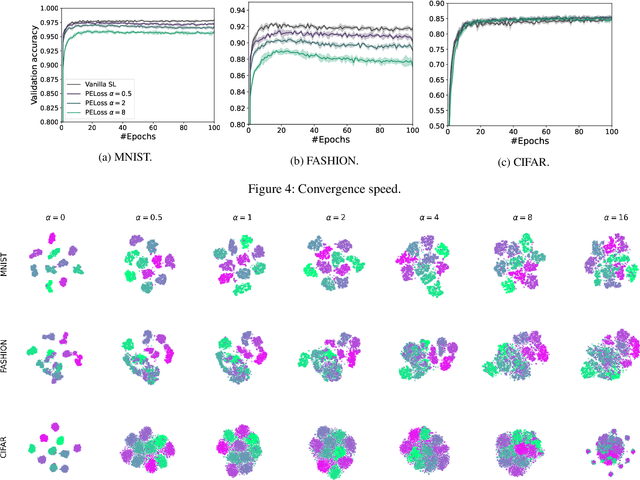
As a practical privacy-preserving learning method, split learning has drawn much attention in academia and industry. However, its security is constantly being questioned since the intermediate results are shared during training and inference. In this paper, we focus on the privacy leakage problem caused by the trained split model, i.e., the attacker can use a few labeled samples to fine-tune the bottom model, and gets quite good performance. To prevent such kind of privacy leakage, we propose the potential energy loss to make the output of the bottom model become a more `complicated' distribution, by pushing outputs of the same class towards the decision boundary. Therefore, the adversary suffers a large generalization error when fine-tuning the bottom model with only a few leaked labeled samples. Experiment results show that our method significantly lowers the attacker's fine-tuning accuracy, making the split model more resilient to label leakage.