 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemystifying the Optimal Fair Classifier in Multi-Class Classification
May 30, 2026Ensuring fair and equitable treatment across diverse groups, particularly in multi-class classification tasks, poses a significant challenge due to the persistent biases inherent in machine learning models. Most existing bias mitigation techniques are tailored to binary settings, and the presence of multi-dimensional outputs and complex fairness mechanisms makes their extension to multi-class scenarios neither straightforward nor effective. In this paper, we investigate two fundamental, unresolved challenges in fair classification: (i) characterizing the optimal accuracy-fairness frontier in multi-class settings, and (ii) designing practical algorithms that attain this optimum in different training phases. To tackle these challenges, we first specify an analytically tractable probabilistic formulation of the optimal classifier under fairness constraints. Building upon this, we propose two attribute-blind algorithms to enforce fairness requirements in practice: an in-processing approach for fairness intervention during training via the reduction approach, and a post-processing approach for fine-tuning output probabilities with plug-in estimation. Theoretical analysis reveals that both methods converge to the optimal accuracy-fairness Pareto frontier. Experiments conducted on multiple datasets demonstrate the superior performance of our methods in balancing accuracy and fairness.
COMPASS: Cognitive MCTS-Guided Process Alignment for Safe Search Agents
May 29, 2026LLM-powered search agents enable multi-step reasoning and tool use. However, these capabilities introduce retrieval-induced safety degradation, as harmful intents may decompose into seemingly innocuous sub-queries that lead to unsafe outcomes. Existing alignment methods struggle to capture sparse safety signals and fail to supervise diverse violations across multi-step interactions. We propose COMPASS, a Cognitive MCTS-Guided Process Alignment framework designed to achieve robust safety alignment throughout the agent workflow while preserving general utility. COMPASS integrates cognitive tree exploration (CTE) to efficiently synthesize stealthy attack trajectories, and introspective step-wise alignment (ISA) to isolate risky intermediate actions for fine-grained process supervision. Empirical results show that COMPASS achieves a favorable safety-utility trade-off while requiring substantially less training data.
Beyond Binary Edits Robust Multimodal Knowledge Editing with Adversarial Subspace Alignment
May 22, 2026Multimodal large language models (MLLMs) need efficient mechanisms to update knowledge without degrading existing capabilities. While intrinsic multimodal knowledge editing achieves strong reliability and locality, it often exhibits limited generality, failing to propagate edits across semantically equivalent visual and linguistic variations. This issue arises from the lack of explicit semantic supervision, rigid editing scopes, and biased anchoring to individual samples in high-dimensional multimodal spaces. We address robust intrinsic multimodal knowledge editing by explicitly targeting generalization. We formalize robustness through knowledge units that group semantically equivalent multimodal inputs and define generality as consistent predictions within each unit. To expose fragile semantic regions, we introduce Latent Adversarial Robustification (LAR), which generates adversarial yet semantically coherent variants in the joint latent space. We further propose Rank-Constrained Subspace Learning (RCSL), enforcing low-rank alignment of adversarial representations at the edit layer via a singular value-based objective. Extensive analysis demonstrates the effectiveness of ASAM empirically.
Taming the Long Tail: Efficient Item-wise Sharpness-Aware Minimization for LLM-based Recommender Systems
Mar 13, 2026Large Language Model-based Recommender Systems (LRSs) have recently emerged as a new paradigm in sequential recommendation by directly adopting LLMs as backbones. While LRSs demonstrate strong knowledge utilization and instruction-following abilities, they have not been systematically studied under the long-standing long-tail problem. In this paper, we conduct an empirical study and reveal that LRSs face two distinct types of long-tail: i) prior long-tail, inherited implicitly from pretraining corpora, and ii) data long-tail, originating from skewed recommendation datasets. Our analysis shows that both contribute to the performance disparity between head and tail items, with the intersection of the two heads exhibiting an even stronger head effect. Nevertheless, the overall performance distribution in LRSs, especially on the tail, remains dominated by the data long-tail. To address this challenge, we propose Efficient Item-wise Sharpness-Aware Minimization (EISAM), a novel optimization framework that improves tail-item performance by adaptively regularizing the loss landscape at the item level. EISAM introduces an efficient penalty design that captures fine-grained item-specific sharpness while maintaining computational scalability for LLMs. In addition, we derive a generalization bound for EISAM. Our theoretical analysis shows that the bound decreases at a faster rate under our item-wise regularization, offering theoretical support for its effectiveness. Extensive experiments on three real-world datasets demonstrate that EISAM significantly boosts tail-item recommendation performance while preserving overall quality, establishing the first systematic solution to the long-tail problem in LRSs.
Sharpness-Aware Minimization for Generalized Embedding Learning in Federated Recommendation
Mar 12, 2026Federated recommender systems enable collaborative model training while keeping user interaction data local and sharing only essential model parameters, thereby mitigating privacy risks. However, existing methods overlook a critical issue, i.e., the stable learning of a generalized item embedding throughout the federated recommender system training process. Item embedding plays a central role in facilitating knowledge sharing across clients. Yet, under the cross-device setting, local data distributions exhibit significant heterogeneity and sparsity, exacerbating the difficulty of learning generalized embeddings. These factors make the stable learning of generalized item embeddings both indispensable for effective federated recommendation and inherently difficult to achieve. To fill this gap, we propose a new federated recommendation framework, named Federated Recommendation with Generalized Embedding Learning (FedRecGEL). We reformulate the federated recommendation problem from an item-centered perspective and cast it as a multi-task learning problem, aiming to learn generalized embeddings throughout the training procedure. Based on theoretical analysis, we employ sharpness-aware minimization to address the generalization problem, thereby stabilizing the training process and enhancing recommendation performance. Extensive experiments on four datasets demonstrate the effectiveness of FedRecGEL in significantly improving federated recommendation performance. Our code is available at https://github.com/anonymifish/FedRecGEL.
Generalizable Multimodal Large Language Model Editing via Invariant Trajectory Learning
Jan 30, 2026Knowledge editing emerges as a crucial technique for efficiently correcting incorrect or outdated knowledge in large language models (LLM). Existing editing methods rely on a rigid mapping from parameter or module modifications to output, which causes the generalization limitation in Multimodal LLM (MLLM). In this paper, we reformulate MLLM editing as an out-of-distribution (OOD) generalization problem, where the goal is to discern semantic shift with factual shift and thus achieve robust editing among diverse cross-modal prompting. The key challenge of this OOD problem lies in identifying invariant causal trajectories that generalize accurately while suppressing spurious correlations. To address it, we propose ODEdit, a plug-and-play invariant learning based framework that optimizes the tripartite OOD risk objective to simultaneously enhance editing reliability, locality, and generality.We further introduce an edit trajectory invariant learning method, which integrates a total variation penalty into the risk minimization objective to stabilize edit trajectories against environmental variations. Theoretical analysis and extensive experiments demonstrate the effectiveness of ODEdit.
PADER: Paillier-based Secure Decentralized Social Recommendation
Jan 15, 2026The prevalence of recommendation systems also brings privacy concerns to both the users and the sellers, as centralized platforms collect as much data as possible from them. To keep the data private, we propose PADER: a Paillier-based secure decentralized social recommendation system. In this system, the users and the sellers are nodes in a decentralized network. The training and inference of the recommendation model are carried out securely in a decentralized manner, without the involvement of a centralized platform. To this end, we apply the Paillier cryptosystem to the SoReg (Social Regularization) model, which exploits both user's ratings and social relations. We view the SoReg model as a two-party secure polynomial evaluation problem and observe that the simple bipartite computation may result in poor efficiency. To improve efficiency, we design secure addition and multiplication protocols to support secure computation on any arithmetic circuit, along with an optimal data packing scheme that is suitable for the polynomial computations of real values. Experiment results show that our method only takes about one second to iterate through one user with hundreds of ratings, and training with ~500K ratings for one epoch only takes <3 hours, which shows that the method is practical in real applications. The code is available at https://github.com/GarminQ/PADER.
Potent but Stealthy: Rethink Profile Pollution against Sequential Recommendation via Bi-level Constrained Reinforcement Paradigm
Nov 14, 2025Sequential Recommenders, which exploit dynamic user intents through interaction sequences, is vulnerable to adversarial attacks. While existing attacks primarily rely on data poisoning, they require large-scale user access or fake profiles thus lacking practicality. In this paper, we focus on the Profile Pollution Attack that subtly contaminates partial user interactions to induce targeted mispredictions. Previous PPA methods suffer from two limitations, i.e., i) over-reliance on sequence horizon impact restricts fine-grained perturbations on item transitions, and ii) holistic modifications cause detectable distribution shifts. To address these challenges, we propose a constrained reinforcement driven attack CREAT that synergizes a bi-level optimization framework with multi-reward reinforcement learning to balance adversarial efficacy and stealthiness. We first develop a Pattern Balanced Rewarding Policy, which integrates pattern inversion rewards to invert critical patterns and distribution consistency rewards to minimize detectable shifts via unbalanced co-optimal transport. Then we employ a Constrained Group Relative Reinforcement Learning paradigm, enabling step-wise perturbations through dynamic barrier constraints and group-shared experience replay, achieving targeted pollution with minimal detectability. Extensive experiments demonstrate the effectiveness of CREAT.
A Remarkably Efficient Paradigm to Multimodal Large Language Models for Sequential Recommendation
Nov 11, 2025
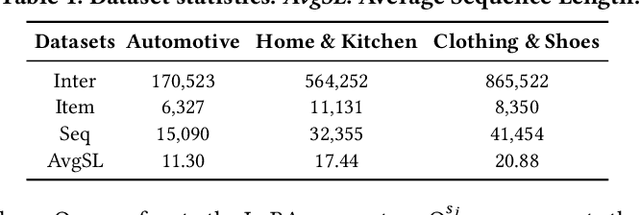
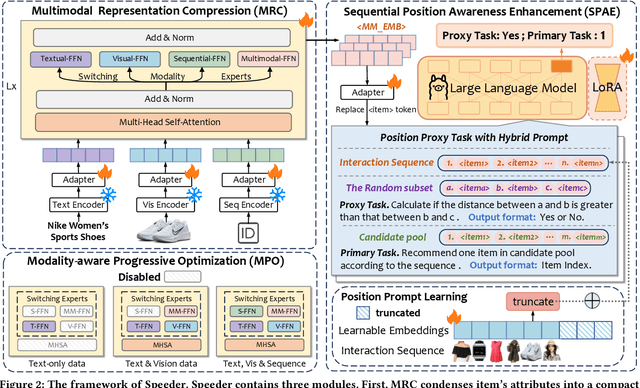
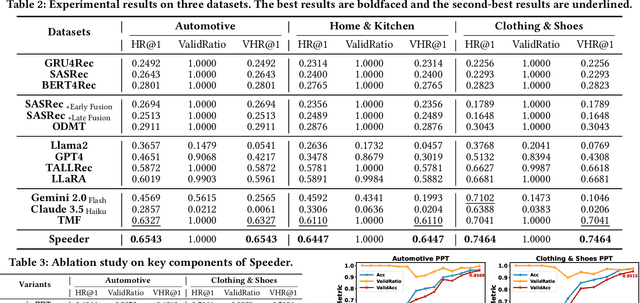
Sequential recommendations (SR) predict users' future interactions based on their historical behavior. The rise of Large Language Models (LLMs) has brought powerful generative and reasoning capabilities, significantly enhancing SR performance, while Multimodal LLMs (MLLMs) further extend this by introducing data like images and interactive relationships. However, critical issues remain, i.e., (a) Suboptimal item representations caused by lengthy and redundant descriptions, leading to inefficiencies in both training and inference; (b) Modality-related cognitive bias, as LLMs are predominantly pretrained on textual data, limiting their ability to effectively integrate and utilize non-textual modalities; (c) Weakening sequential perception in long interaction sequences, where attention mechanisms struggle to capture earlier interactions, hindering the modeling of long-range dependencies. To address these issues, we propose Speeder, an efficient MLLM-based paradigm for SR featuring three key innovations: 1) Multimodal Representation Compression (MRC), which condenses item attributes into concise yet informative tokens, reducing redundancy and computational cost; 2) Modality-aware Progressive Optimization (MPO), enabling gradual learning of multimodal representations; 3) Sequential Position Awareness Enhancement (SPAE), improving the LLM's capability to capture both relative and absolute sequential dependencies in long interaction sequences. Extensive experiments on real-world datasets demonstrate the effectiveness and efficiency of Speeder. Speeder increases training speed to 250% of the original while reducing inference time to 25% on the Amazon dataset.
UW-3DGS: Underwater 3D Reconstruction with Physics-Aware Gaussian Splatting
Aug 08, 2025Underwater 3D scene reconstruction faces severe challenges from light absorption, scattering, and turbidity, which degrade geometry and color fidelity in traditional methods like Neural Radiance Fields (NeRF). While NeRF extensions such as SeaThru-NeRF incorporate physics-based models, their MLP reliance limits efficiency and spatial resolution in hazy environments. We introduce UW-3DGS, a novel framework adapting 3D Gaussian Splatting (3DGS) for robust underwater reconstruction. Key innovations include: (1) a plug-and-play learnable underwater image formation module using voxel-based regression for spatially varying attenuation and backscatter; and (2) a Physics-Aware Uncertainty Pruning (PAUP) branch that adaptively removes noisy floating Gaussians via uncertainty scoring, ensuring artifact-free geometry. The pipeline operates in training and rendering stages. During training, noisy Gaussians are optimized end-to-end with underwater parameters, guided by PAUP pruning and scattering modeling. In rendering, refined Gaussians produce clean Unattenuated Radiance Images (URIs) free from media effects, while learned physics enable realistic Underwater Images (UWIs) with accurate light transport. Experiments on SeaThru-NeRF and UWBundle datasets show superior performance, achieving PSNR of 27.604, SSIM of 0.868, and LPIPS of 0.104 on SeaThru-NeRF, with ~65% reduction in floating artifacts.