 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMO-Bench: Large Language Models Still Struggle in High School Math Competitions
Oct 30, 2025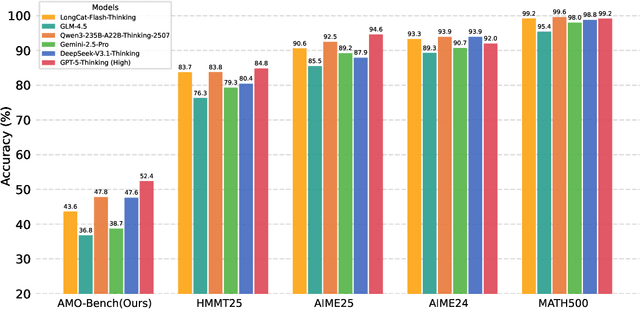
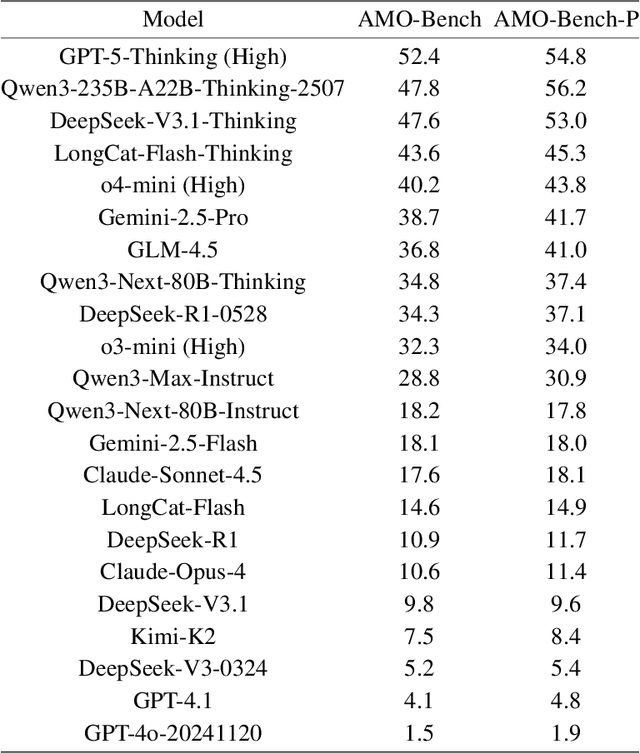
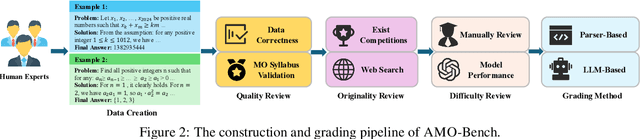
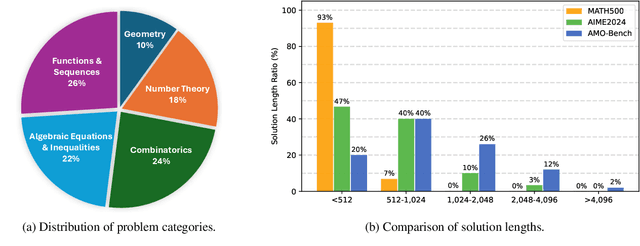
We present AMO-Bench, an Advanced Mathematical reasoning benchmark with Olympiad level or even higher difficulty, comprising 50 human-crafted problems. Existing benchmarks have widely leveraged high school math competitions for evaluating mathematical reasoning capabilities of large language models (LLMs). However, many existing math competitions are becoming less effective for assessing top-tier LLMs due to performance saturation (e.g., AIME24/25). To address this, AMO-Bench introduces more rigorous challenges by ensuring all 50 problems are (1) cross-validated by experts to meet at least the International Mathematical Olympiad (IMO) difficulty standards, and (2) entirely original problems to prevent potential performance leakages from data memorization. Moreover, each problem in AMO-Bench requires only a final answer rather than a proof, enabling automatic and robust grading for evaluation. Experimental results across 26 LLMs on AMO-Bench show that even the best-performing model achieves only 52.4% accuracy on AMO-Bench, with most LLMs scoring below 40%. Beyond these poor performances, our further analysis reveals a promising scaling trend with increasing test-time compute on AMO-Bench. These results highlight the significant room for improving the mathematical reasoning in current LLMs. We release AMO-Bench to facilitate further research into advancing the reasoning abilities of language models. https://amo-bench.github.io/
Energy-Efficient Index and Code Index Modulations for Spread CPM Signals in Internet of Things
Aug 14, 2025
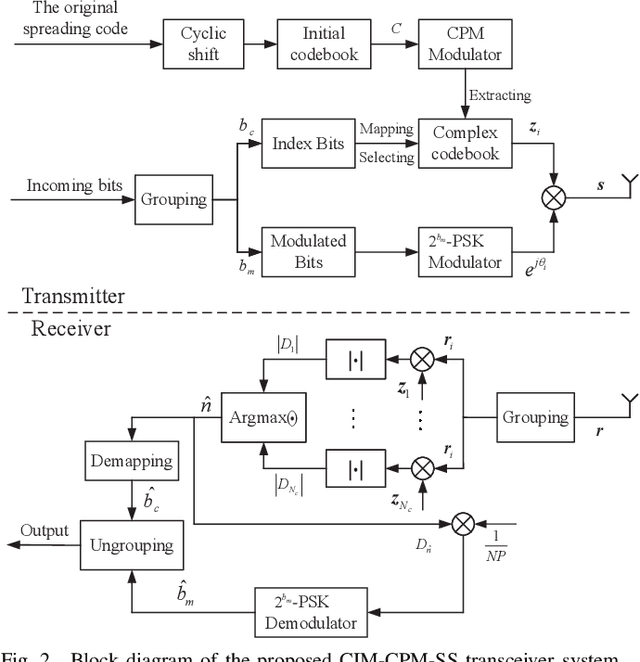


The evolution of Internet of Things technologies is driven by four key demands: ultra-low power consumption, high spectral efficiency, reduced implementation cost, and support for massive connectivity. To address these challenges, this paper proposes two novel modulation schemes that integrate continuous phase modulation (CPM) with spread spectrum (SS) techniques. We begin by establishing the quasi-orthogonality properties of CPM-SS sequences. The first scheme, termed IM-CPM-SS, employs index modulation (IM) to select spreading sequences from the CPM-SS set, thereby improving spectral efficiency while maintaining the constant-envelope property. The second scheme, referred to as CIM-CPM-SS, introduces code index modulation (CIM), which partitions the input bits such that one subset is mapped to phase-shift keying symbols and the other to CPM-SS sequence indices. Both schemes are applied to downlink non-orthogonal multiple access (NOMA) systems. We analyze their performance in terms of bit error rate (BER), spectral and energy efficiency, computational complexity, and peak-to-average power ratio characteristics under nonlinear amplifier conditions. Simulation results demonstrate that both schemes outperform conventional approaches in BER while preserving the benefits of constant-envelope, continuous-phase signaling. Furthermore, they achieve higher spectral and energy efficiency and exhibit strong resilience to nonlinear distortions in downlink NOMA scenarios.
A Neuro-inspired Interpretation of Unlearning in Large Language Models through Sample-level Unlearning Difficulty
Apr 09, 2025Driven by privacy protection laws and regulations, unlearning in Large Language Models (LLMs) is gaining increasing attention. However, current research often neglects the interpretability of the unlearning process, particularly concerning sample-level unlearning difficulty. Existing studies typically assume a uniform unlearning difficulty across samples. This simplification risks attributing the performance of unlearning algorithms to sample selection rather than the algorithm's design, potentially steering the development of LLM unlearning in the wrong direction. Thus, we investigate the relationship between LLM unlearning and sample characteristics, with a focus on unlearning difficulty. Drawing inspiration from neuroscience, we propose a Memory Removal Difficulty ($\mathrm{MRD}$) metric to quantify sample-level unlearning difficulty. Using $\mathrm{MRD}$, we analyze the characteristics of hard-to-unlearn versus easy-to-unlearn samples. Furthermore, we propose an $\mathrm{MRD}$-based weighted sampling method to optimize existing unlearning algorithms, which prioritizes easily forgettable samples, thereby improving unlearning efficiency and effectiveness. We validate the proposed metric and method using public benchmarks and datasets, with results confirming its effectiveness.
ContextModule: Improving Code Completion via Repository-level Contextual Information
Dec 11, 2024Large Language Models (LLMs) have demonstrated impressive capabilities in code completion tasks, where they assist developers by predicting and generating new code in real-time. However, existing LLM-based code completion systems primarily rely on the immediate context of the file being edited, often missing valuable repository-level information, user behaviour and edit history that could improve suggestion accuracy. Additionally, challenges such as efficiently retrieving relevant code snippets from large repositories, incorporating user behavior, and balancing accuracy with low-latency requirements in production environments remain unresolved. In this paper, we propose ContextModule, a framework designed to enhance LLM-based code completion by retrieving and integrating three types of contextual information from the repository: user behavior-based code, similar code snippets, and critical symbol definitions. By capturing user interactions across files and leveraging repository-wide static analysis, ContextModule improves the relevance and precision of generated code. We implement performance optimizations, such as index caching, to ensure the system meets the latency constraints of real-world coding environments. Experimental results and industrial practise demonstrate that ContextModule significantly improves code completion accuracy and user acceptance rates.
Video2Reward: Generating Reward Function from Videos for Legged Robot Behavior Learning
Dec 07, 2024Learning behavior in legged robots presents a significant challenge due to its inherent instability and complex constraints. Recent research has proposed the use of a large language model (LLM) to generate reward functions in reinforcement learning, thereby replacing the need for manually designed rewards by experts. However, this approach, which relies on textual descriptions to define learning objectives, fails to achieve controllable and precise behavior learning with clear directionality. In this paper, we introduce a new video2reward method, which directly generates reward functions from videos depicting the behaviors to be mimicked and learned. Specifically, we first process videos containing the target behaviors, converting the motion information of individuals in the videos into keypoint trajectories represented as coordinates through a video2text transforming module. These trajectories are then fed into an LLM to generate the reward function, which in turn is used to train the policy. To enhance the quality of the reward function, we develop a video-assisted iterative reward refinement scheme that visually assesses the learned behaviors and provides textual feedback to the LLM. This feedback guides the LLM to continually refine the reward function, ultimately facilitating more efficient behavior learning. Experimental results on tasks involving bipedal and quadrupedal robot motion control demonstrate that our method surpasses the performance of state-of-the-art LLM-based reward generation methods by over 37.6% in terms of human normalized score. More importantly, by switching video inputs, we find our method can rapidly learn diverse motion behaviors such as walking and running.
* 8 pages, 6 figures, ECAI2024
Boosting the Transferability of Adversarial Examples via Local Mixup and Adaptive Step Size
Jan 24, 2024Adversarial examples are one critical security threat to various visual applications, where injected human-imperceptible perturbations can confuse the output.Generating transferable adversarial examples in the black-box setting is crucial but challenging in practice. Existing input-diversity-based methods adopt different image transformations, but may be inefficient due to insufficient input diversity and an identical perturbation step size. Motivated by the fact that different image regions have distinctive weights in classification, this paper proposes a black-box adversarial generative framework by jointly designing enhanced input diversity and adaptive step sizes. We design local mixup to randomly mix a group of transformed adversarial images, strengthening the input diversity. For precise adversarial generation, we project the perturbation into the $tanh$ space to relax the boundary constraint. Moreover, the step sizes of different regions can be dynamically adjusted by integrating a second-order momentum.Extensive experiments on ImageNet validate that our framework can achieve superior transferability compared to state-of-the-art baselines.
Making Recommender Systems Forget: Learning and Unlearning for Erasable Recommendation
Mar 22, 2022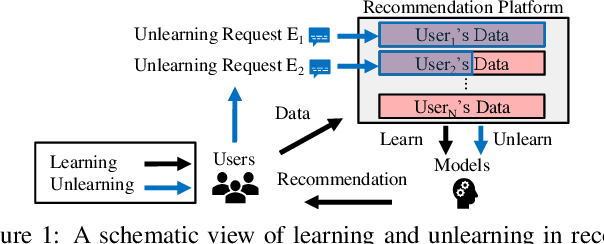

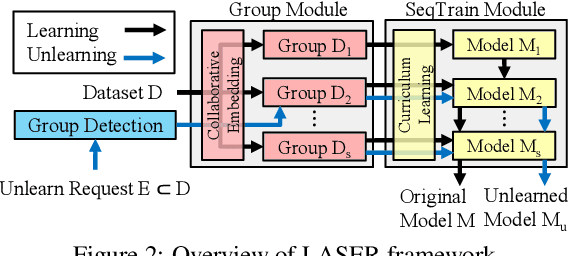
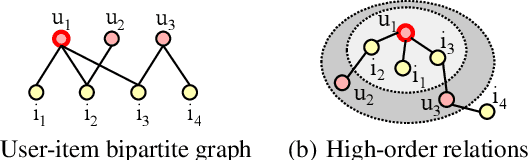
Privacy laws and regulations enforce data-driven systems, e.g., recommender systems, to erase the data that concern individuals. As machine learning models potentially memorize the training data, data erasure should also unlearn the data lineage in models, which raises increasing interest in the problem of Machine Unlearning (MU). However, existing MU methods cannot be directly applied into recommendation. The basic idea of most recommender systems is collaborative filtering, but existing MU methods ignore the collaborative information across users and items. In this paper, we propose a general erasable recommendation framework, namely LASER, which consists of Group module and SeqTrain module. Firstly, Group module partitions users into balanced groups based on their similarity of collaborative embedding learned via hypergraph. Then SeqTrain module trains the model sequentially on all groups with curriculum learning. Both theoretical analysis and experiments on two real-world datasets demonstrate that LASER can not only achieve efficient unlearning, but also outperform the state-of-the-art unlearning framework in terms of model utility.
Clustering Label Inference Attack against Practical Split Learning
Mar 10, 2022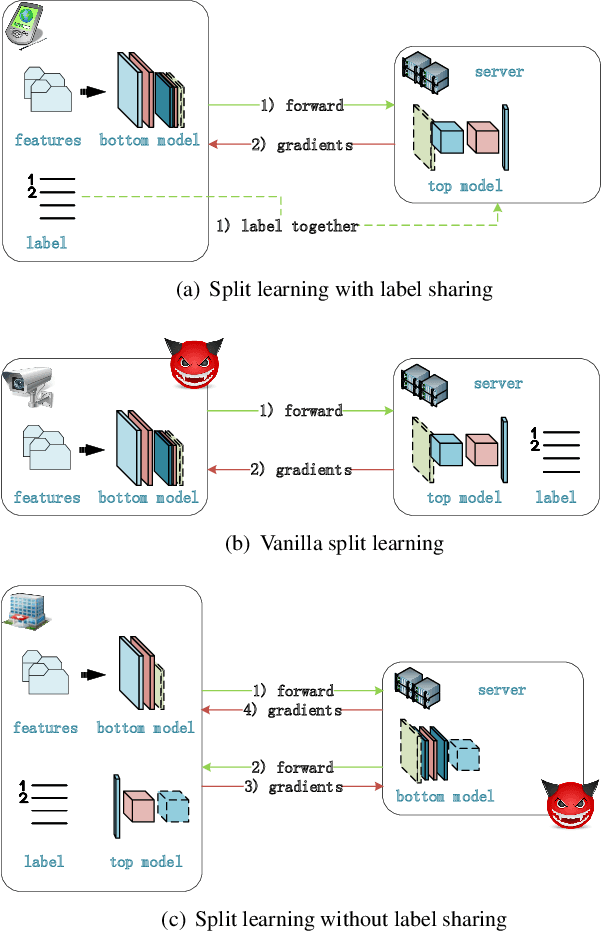

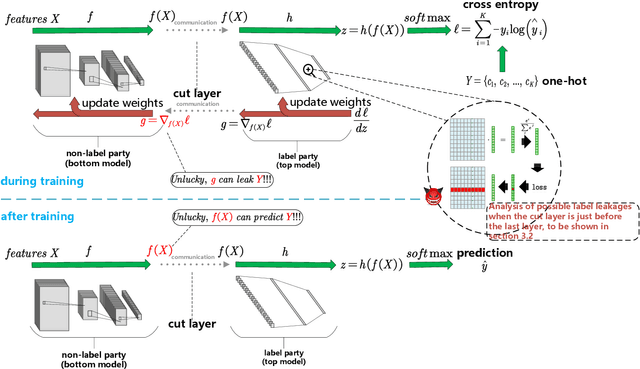
Split learning is deemed as a promising paradigm for privacy-preserving distributed learning, where the learning model can be cut into multiple portions to be trained at the participants collaboratively. The participants only exchange the intermediate learning results at the cut layer, including smashed data via forward-pass (i.e., features extracted from the raw data) and gradients during backward-propagation.Understanding the security performance of split learning is critical for various privacy-sensitive applications.With the emphasis on private labels, this paper proposes a passive clustering label inference attack for practical split learning. The adversary (either clients or servers) can accurately retrieve the private labels by collecting the exchanged gradients and smashed data.We mathematically analyse potential label leakages in split learning and propose the cosine and Euclidean similarity measurements for clustering attack. Experimental results validate that the proposed approach is scalable and robust under different settings (e.g., cut layer positions, epochs, and batch sizes) for practical split learning.The adversary can still achieve accurate predictions, even when differential privacy and gradient compression are adopted for label protections.
Energon: Towards Efficient Acceleration of Transformers Using Dynamic Sparse Attention
Oct 18, 2021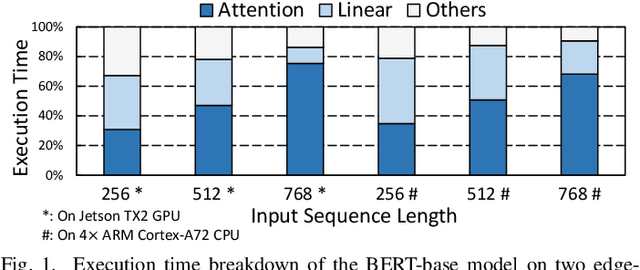



In recent years, transformer models have revolutionized Natural Language Processing (NLP) and also show promising performance on Computer Vision (CV) tasks. Despite their effectiveness, transformers' attention operations are hard to accelerate due to complicated data movement and quadratic computational complexity, prohibiting the real-time inference on resource-constrained edge-computing platforms. To tackle this challenge, we propose Energon, an algorithm-architecture co-design approach that accelerates various transformers using dynamic sparse attention. With the observation that attention results only depend on a few important query-key pairs, we propose a multi-round filtering algorithm to dynamically identify such pairs at runtime. We adopt low bitwidth in each filtering round and only use high-precision tensors in the attention stage to reduce overall complexity. By this means, we significantly mitigate the computational cost with negligible accuracy loss. To enable such an algorithm with lower latency and better energy-efficiency, we also propose an Energon co-processor architecture. Elaborated pipelines and specialized optimizations jointly boost the performance and reduce power consumption. Extensive experiments on both NLP and CV benchmarks demonstrate that Energon achieves $161\times$ and $8.4\times$ geo-mean speedup and up to $10^4\times$ and $10^3\times$ energy reduction compared with Intel Xeon 5220 CPU and NVIDIA V100 GPU. Compared to state-of-the-art attention accelerators SpAtten and $A^3$, Energon also achieves $1.7\times, 1.25\times$ speedup and $1.6 \times, 1.5\times $ higher energy efficiency.