 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Task-Invariant Properties via Dreamer: Enabling Efficient Policy Transfer for Quadruped Robots
Apr 03, 2026Achieving quadruped robot locomotion across diverse and dynamic terrains presents significant challenges, primarily due to the discrepancies between simulation environments and real-world conditions. Traditional sim-to-real transfer methods often rely on manual feature design or costly real-world fine-tuning. To address these limitations, this paper proposes the DreamTIP framework, which incorporates Task-Invariant Properties learning within the Dreamer world model architecture to enhance sim-to-real transfer capabilities. Guided by large language models, DreamTIP identifies and leverages Task-Invariant Properties, such as contact stability and terrain clearance, which exhibit robustness to dynamic variations and strong transferability across tasks. These properties are integrated into the world model as auxiliary prediction targets, enabling the policy to learn representations that are insensitive to underlying dynamic changes. Furthermore, an efficient adaptation strategy is designed, employing a mixed replay buffer and regularization constraints to rapidly calibrate to real-world dynamics while effectively mitigating representation collapse and catastrophic forgetting. Extensive experiments on complex terrains, including Stair, Climb, Tilt, and Crawl, demonstrate that DreamTIP significantly outperforms state-of-the-art baselines in both simulated and real-world environments. Our method achieves an average performance improvement of 28.1% across eight distinct simulated transfer tasks. In the real-world Climb task, the baseline method achieved only a 10\ success rate, whereas our method attained a 100% success rate. These results indicate that incorporating Task-Invariant Properties into Dreamer learning offers a novel solution for achieving robust and transferable robot locomotion.
Revisiting Cross-Architecture Distillation: Adaptive Dual-Teacher Transfer for Lightweight Video Models
Nov 12, 2025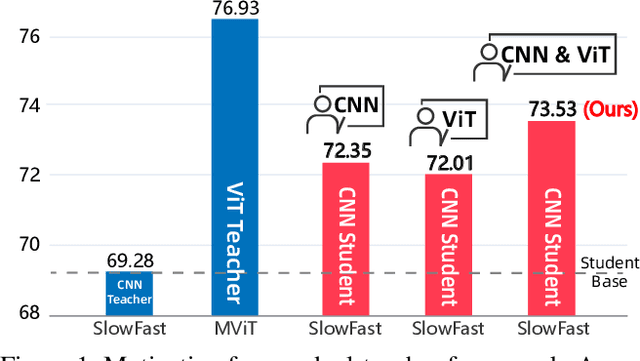

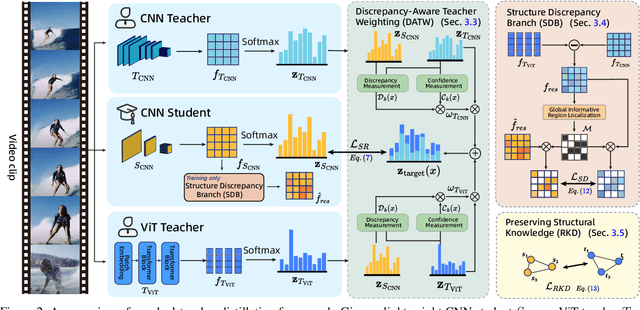

Vision Transformers (ViTs) have achieved strong performance in video action recognition, but their high computational cost limits their practicality. Lightweight CNNs are more efficient but suffer from accuracy gaps. Cross-Architecture Knowledge Distillation (CAKD) addresses this by transferring knowledge from ViTs to CNNs, yet existing methods often struggle with architectural mismatch and overlook the value of stronger homogeneous CNN teachers. To tackle these challenges, we propose a Dual-Teacher Knowledge Distillation framework that leverages both a heterogeneous ViT teacher and a homogeneous CNN teacher to collaboratively guide a lightweight CNN student. We introduce two key components: (1) Discrepancy-Aware Teacher Weighting, which dynamically fuses the predictions from ViT and CNN teachers by assigning adaptive weights based on teacher confidence and prediction discrepancy with the student, enabling more informative and effective supervision; and (2) a Structure Discrepancy-Aware Distillation strategy, where the student learns the residual features between ViT and CNN teachers via a lightweight auxiliary branch, focusing on transferable architectural differences without mimicking all of ViT's high-dimensional patterns. Extensive experiments on benchmarks including HMDB51, EPIC-KITCHENS-100, and Kinetics-400 demonstrate that our method consistently outperforms state-of-the-art distillation approaches, achieving notable performance improvements with a maximum accuracy gain of 5.95% on HMDB51.
Whole-Body Coordination for Dynamic Object Grasping with Legged Manipulators
Aug 10, 2025Quadrupedal robots with manipulators offer strong mobility and adaptability for grasping in unstructured, dynamic environments through coordinated whole-body control. However, existing research has predominantly focused on static-object grasping, neglecting the challenges posed by dynamic targets and thus limiting applicability in dynamic scenarios such as logistics sorting and human-robot collaboration. To address this, we introduce DQ-Bench, a new benchmark that systematically evaluates dynamic grasping across varying object motions, velocities, heights, object types, and terrain complexities, along with comprehensive evaluation metrics. Building upon this benchmark, we propose DQ-Net, a compact teacher-student framework designed to infer grasp configurations from limited perceptual cues. During training, the teacher network leverages privileged information to holistically model both the static geometric properties and dynamic motion characteristics of the target, and integrates a grasp fusion module to deliver robust guidance for motion planning. Concurrently, we design a lightweight student network that performs dual-viewpoint temporal modeling using only the target mask, depth map, and proprioceptive state, enabling closed-loop action outputs without reliance on privileged data. Extensive experiments on DQ-Bench demonstrate that DQ-Net achieves robust dynamic objects grasping across multiple task settings, substantially outperforming baseline methods in both success rate and responsiveness.
Automated Hybrid Reward Scheduling via Large Language Models for Robotic Skill Learning
May 05, 2025



Enabling a high-degree-of-freedom robot to learn specific skills is a challenging task due to the complexity of robotic dynamics. Reinforcement learning (RL) has emerged as a promising solution; however, addressing such problems requires the design of multiple reward functions to account for various constraints in robotic motion. Existing approaches typically sum all reward components indiscriminately to optimize the RL value function and policy. We argue that this uniform inclusion of all reward components in policy optimization is inefficient and limits the robot's learning performance. To address this, we propose an Automated Hybrid Reward Scheduling (AHRS) framework based on Large Language Models (LLMs). This paradigm dynamically adjusts the learning intensity of each reward component throughout the policy optimization process, enabling robots to acquire skills in a gradual and structured manner. Specifically, we design a multi-branch value network, where each branch corresponds to a distinct reward component. During policy optimization, each branch is assigned a weight that reflects its importance, and these weights are automatically computed based on rules designed by LLMs. The LLM generates a rule set in advance, derived from the task description, and during training, it selects a weight calculation rule from the library based on language prompts that evaluate the performance of each branch. Experimental results demonstrate that the AHRS method achieves an average 6.48% performance improvement across multiple high-degree-of-freedom robotic tasks.
Efficient Language-instructed Skill Acquisition via Reward-Policy Co-Evolution
Dec 18, 2024



The ability to autonomously explore and resolve tasks with minimal human guidance is crucial for the self-development of embodied intelligence. Although reinforcement learning methods can largely ease human effort, it's challenging to design reward functions for real-world tasks, especially for high-dimensional robotic control, due to complex relationships among joints and tasks. Recent advancements large language models (LLMs) enable automatic reward function design. However, approaches evaluate reward functions by re-training policies from scratch placing an undue burden on the reward function, expecting it to be effective throughout the whole policy improvement process. We argue for a more practical strategy in robotic autonomy, focusing on refining existing policies with policy-dependent reward functions rather than a universal one. To this end, we propose a novel reward-policy co-evolution framework where the reward function and the learned policy benefit from each other's progressive on-the-fly improvements, resulting in more efficient and higher-performing skill acquisition. Specifically, the reward evolution process translates the robot's previous best reward function, descriptions of tasks and environment into text inputs. These inputs are used to query LLMs to generate a dynamic amount of reward function candidates, ensuring continuous improvement at each round of evolution. For policy evolution, our method generates new policy populations by hybridizing historically optimal and random policies. Through an improved Bayesian optimization, our approach efficiently and robustly identifies the most capable and plastic reward-policy combination, which then proceeds to the next round of co-evolution. Despite using less data, our approach demonstrates an average normalized improvement of 95.3% across various high-dimensional robotic skill learning tasks.
Video2Reward: Generating Reward Function from Videos for Legged Robot Behavior Learning
Dec 07, 2024Learning behavior in legged robots presents a significant challenge due to its inherent instability and complex constraints. Recent research has proposed the use of a large language model (LLM) to generate reward functions in reinforcement learning, thereby replacing the need for manually designed rewards by experts. However, this approach, which relies on textual descriptions to define learning objectives, fails to achieve controllable and precise behavior learning with clear directionality. In this paper, we introduce a new video2reward method, which directly generates reward functions from videos depicting the behaviors to be mimicked and learned. Specifically, we first process videos containing the target behaviors, converting the motion information of individuals in the videos into keypoint trajectories represented as coordinates through a video2text transforming module. These trajectories are then fed into an LLM to generate the reward function, which in turn is used to train the policy. To enhance the quality of the reward function, we develop a video-assisted iterative reward refinement scheme that visually assesses the learned behaviors and provides textual feedback to the LLM. This feedback guides the LLM to continually refine the reward function, ultimately facilitating more efficient behavior learning. Experimental results on tasks involving bipedal and quadrupedal robot motion control demonstrate that our method surpasses the performance of state-of-the-art LLM-based reward generation methods by over 37.6% in terms of human normalized score. More importantly, by switching video inputs, we find our method can rapidly learn diverse motion behaviors such as walking and running.
* 8 pages, 6 figures, ECAI2024
Hybrid and dynamic policy gradient optimization for bipedal robot locomotion
Jul 05, 2021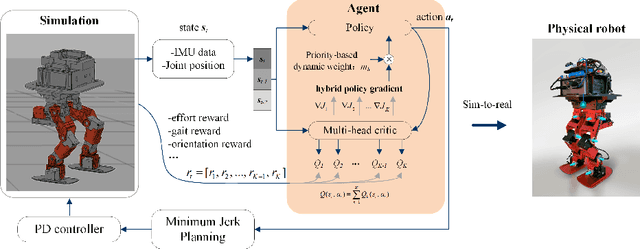
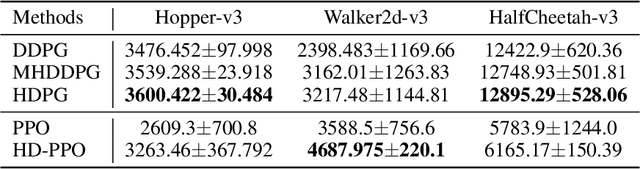
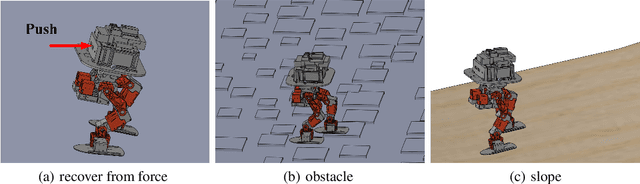
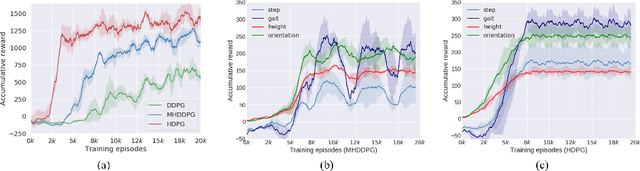
Controlling a non-statically bipedal robot is challenging due to the complex dynamics and multi-criterion optimization involved. Recent works have demonstrated the effectiveness of deep reinforcement learning (DRL) for simulation and physically implemented bipeds. In these methods, the rewards from different criteria are normally summed to learn a single value function. However, this may cause the loss of dependency information between hybrid rewards and lead to a sub-optimal policy. In this work, we propose a novel policy gradient reinforcement learning for biped locomotion, allowing the control policy to be simultaneously optimized by multiple criteria using a dynamic mechanism. Our proposed method applies a multi-head critic to learn a separate value function for each component reward function. This also leads to hybrid policy gradients. We further propose dynamic weight for hybrid policy gradients to optimize the policy with different priorities. This hybrid and dynamic policy gradient (HDPG) design makes the agent learn more efficiently. We showed that the proposed method outperforms summed-up-reward approaches and is able to transfer to physical robots. The MuJoCo results further demonstrate the effectiveness and generalization of our HDPG.