 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid and dynamic policy gradient optimization for bipedal robot locomotion
Paper and Code
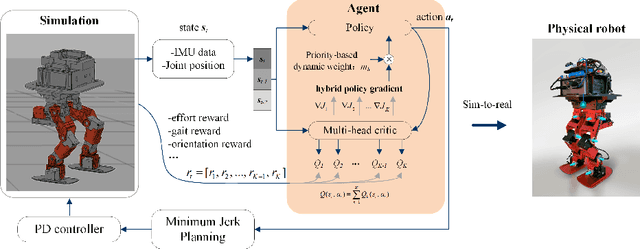
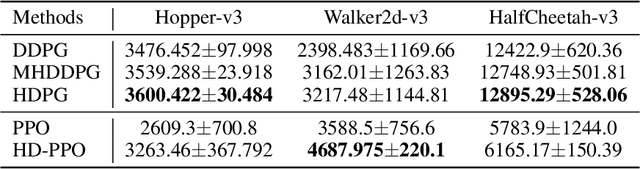
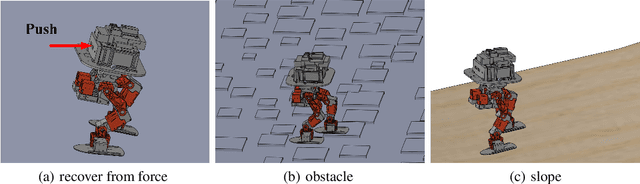
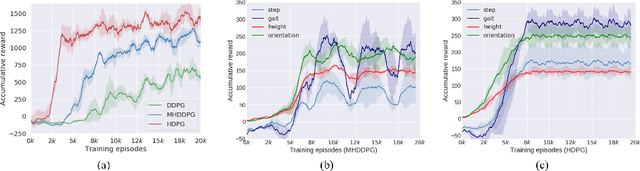
Controlling a non-statically bipedal robot is challenging due to the complex dynamics and multi-criterion optimization involved. Recent works have demonstrated the effectiveness of deep reinforcement learning (DRL) for simulation and physically implemented bipeds. In these methods, the rewards from different criteria are normally summed to learn a single value function. However, this may cause the loss of dependency information between hybrid rewards and lead to a sub-optimal policy. In this work, we propose a novel policy gradient reinforcement learning for biped locomotion, allowing the control policy to be simultaneously optimized by multiple criteria using a dynamic mechanism. Our proposed method applies a multi-head critic to learn a separate value function for each component reward function. This also leads to hybrid policy gradients. We further propose dynamic weight for hybrid policy gradients to optimize the policy with different priorities. This hybrid and dynamic policy gradient (HDPG) design makes the agent learn more efficiently. We showed that the proposed method outperforms summed-up-reward approaches and is able to transfer to physical robots. The MuJoCo results further demonstrate the effectiveness and generalization of our HDPG.