 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOBELiX: A Curated Dataset of Crystal Structures and Experimentally Measured Ionic Conductivities for Lithium Solid-State Electrolytes
Feb 20, 2025



Solid-state electrolyte batteries are expected to replace liquid electrolyte lithium-ion batteries in the near future thanks to their higher theoretical energy density and improved safety. However, their adoption is currently hindered by their lower effective ionic conductivity, a quantity that governs charge and discharge rates. Identifying highly ion-conductive materials using conventional theoretical calculations and experimental validation is both time-consuming and resource-intensive. While machine learning holds the promise to expedite this process, relevant ionic conductivity and structural data is scarce. Here, we present OBELiX, a domain-expert-curated database of $\sim$600 synthesized solid electrolyte materials and their experimentally measured room temperature ionic conductivities gathered from literature. Each material is described by their measured composition, space group and lattice parameters. A full-crystal description in the form of a crystallographic information file (CIF) is provided for ~320 structures for which atomic positions were available. We discuss various statistics and features of the dataset and provide training and testing splits that avoid data leakage. Finally, we benchmark seven existing ML models on the task of predicting ionic conductivity and discuss their performance. The goal of this work is to facilitate the use of machine learning for solid-state electrolyte materials discovery.
Hybrid and dynamic policy gradient optimization for bipedal robot locomotion
Jul 05, 2021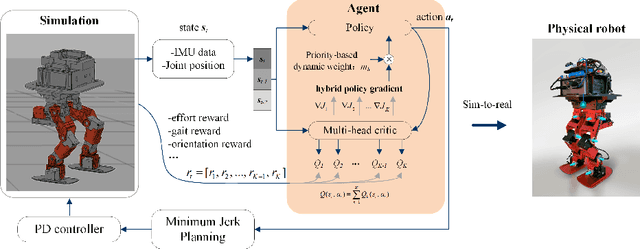
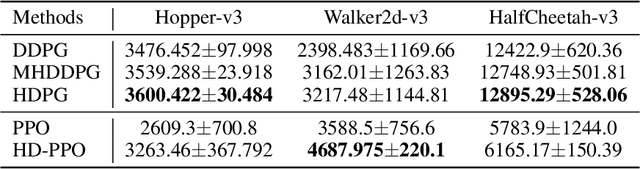
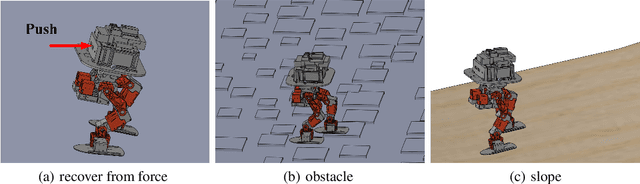
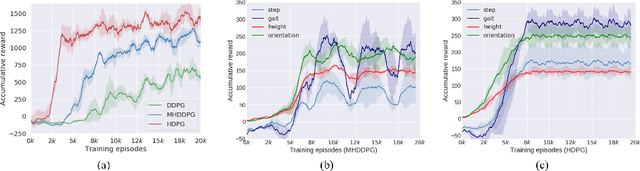
Controlling a non-statically bipedal robot is challenging due to the complex dynamics and multi-criterion optimization involved. Recent works have demonstrated the effectiveness of deep reinforcement learning (DRL) for simulation and physically implemented bipeds. In these methods, the rewards from different criteria are normally summed to learn a single value function. However, this may cause the loss of dependency information between hybrid rewards and lead to a sub-optimal policy. In this work, we propose a novel policy gradient reinforcement learning for biped locomotion, allowing the control policy to be simultaneously optimized by multiple criteria using a dynamic mechanism. Our proposed method applies a multi-head critic to learn a separate value function for each component reward function. This also leads to hybrid policy gradients. We further propose dynamic weight for hybrid policy gradients to optimize the policy with different priorities. This hybrid and dynamic policy gradient (HDPG) design makes the agent learn more efficiently. We showed that the proposed method outperforms summed-up-reward approaches and is able to transfer to physical robots. The MuJoCo results further demonstrate the effectiveness and generalization of our HDPG.
EagleEye: Fast Sub-net Evaluation for Efficient Neural Network Pruning
Jul 06, 2020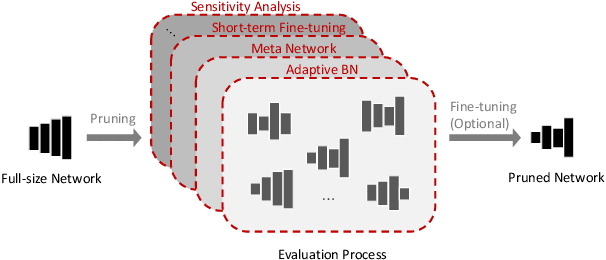
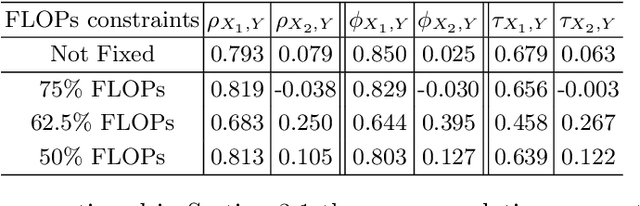
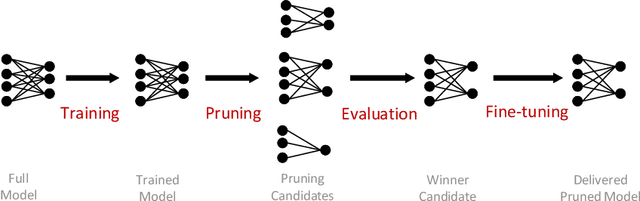
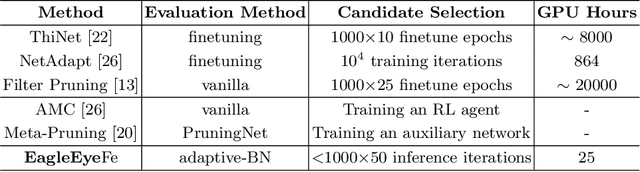
Finding out the computational redundant part of a trained Deep Neural Network (DNN) is the key question that pruning algorithms target on. Many algorithms try to predict model performance of the pruned sub-nets by introducing various evaluation methods. But they are either inaccurate or very complicated for general application. In this work, we present a pruning method called EagleEye, in which a simple yet efficient evaluation component based on adaptive batch normalization is applied to unveil a strong correlation between different pruned DNN structures and their final settled accuracy. This strong correlation allows us to fast spot the pruned candidates with highest potential accuracy without actually fine-tuning them. This module is also general to plug-in and improve some existing pruning algorithms. EagleEye achieves better pruning performance than all of the studied pruning algorithms in our experiments. Concretely, to prune MobileNet V1 and ResNet-50, EagleEye outperforms all compared methods by up to 3.8%. Even in the more challenging experiments of pruning the compact model of MobileNet V1, EagleEye achieves the highest accuracy of 70.9% with an overall 50% operations (FLOPs) pruned. All accuracy results are Top-1 ImageNet classification accuracy. Source code and models are accessible to open-source community https://github.com/anonymous47823493/EagleEye .
Accuracy to Throughput Trade-offs for Reduced Precision Neural Networks on Reconfigurable Logic
Jul 17, 2018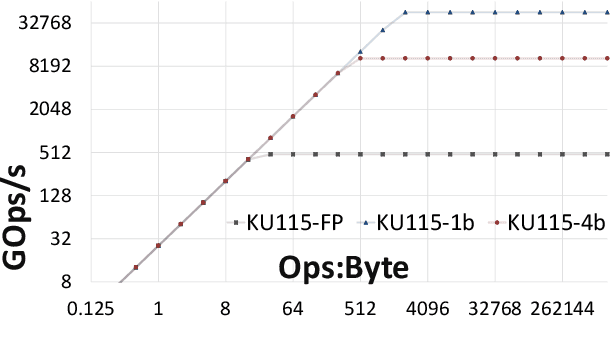
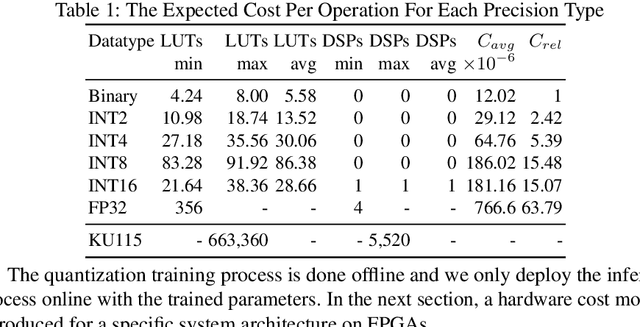
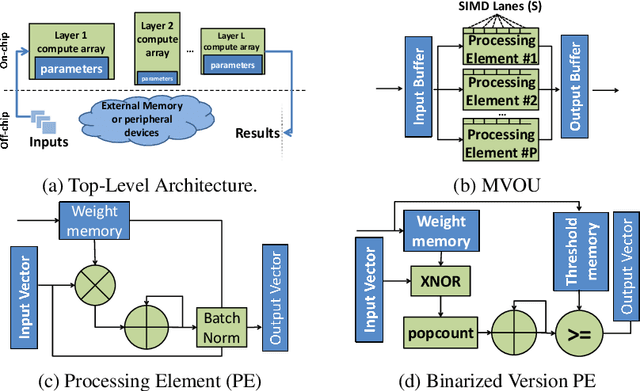

Modern CNN are typically based on floating point linear algebra based implementations. Recently, reduced precision NN have been gaining popularity as they require significantly less memory and computational resources compared to floating point. This is particularly important in power constrained compute environments. However, in many cases a reduction in precision comes at a small cost to the accuracy of the resultant network. In this work, we investigate the accuracy-throughput trade-off for various parameter precision applied to different types of NN models. We firstly propose a quantization training strategy that allows reduced precision NN inference with a lower memory footprint and competitive model accuracy. Then, we quantitatively formulate the relationship between data representation and hardware efficiency. Our experiments finally provide insightful observation. For example, one of our tests show 32-bit floating point is more hardware efficient than 1-bit parameters to achieve 99% MNIST accuracy. In general, 2-bit and 4-bit fixed point parameters show better hardware trade-off on small-scale datasets like MNIST and CIFAR-10 while 4-bit provide the best trade-off in large-scale tasks like AlexNet on ImageNet dataset within our tested problem domain.
End-to-End Multi-View Networks for Text Classification
Apr 19, 2017


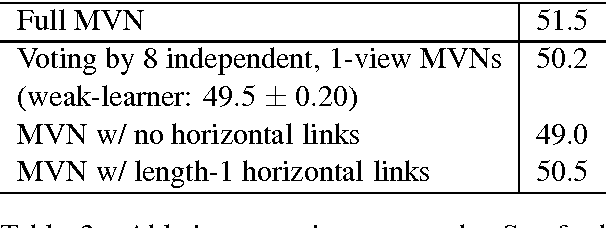
We propose a multi-view network for text classification. Our method automatically creates various views of its input text, each taking the form of soft attention weights that distribute the classifier's focus among a set of base features. For a bag-of-words representation, each view focuses on a different subset of the text's words. Aggregating many such views results in a more discriminative and robust representation. Through a novel architecture that both stacks and concatenates views, we produce a network that emphasizes both depth and width, allowing training to converge quickly. Using our multi-view architecture, we establish new state-of-the-art accuracies on two benchmark tasks.