 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixQuant: Pushing the Limits of Block Rotations in Post-Training Quantization
Jan 29, 2026Recent post-training quantization (PTQ) methods have adopted block rotations to diffuse outliers prior to rounding. While this reduces the overhead of full-vector rotations, the effect of block structure on outlier suppression remains poorly understood. To fill this gap, we present the first systematic, non-asymptotic analysis of outlier suppression for block Hadamard rotations. Our analysis reveals that outlier suppression is fundamentally limited by the geometry of the input vector. In particular, post-rotation outliers are deterministically minimized when the pre-rotation $\ell_1$ norm mass is evenly distributed across blocks. Guided by these insights, we introduce MixQuant, a block rotation-aware PTQ framework that redistributes activation mass via permutations prior to rotation. We propose a greedy mass diffusion algorithm to calibrate permutations by equalizing the expected blockwise $\ell_1$ norms. To avoid adding inference overhead, we identify permutation-equivariant regions in transformer architectures to merge the resulting permutations into model weights before deployment. Experiments show that MixQuant consistently improves accuracy across all block sizes, recovering up to 90% of the full-vector rotation perplexity when quantizing Llama3 1B to INT4 with block size 16, compared to 46% without permutations.
Ps and Qs: Quantization-aware pruning for efficient low latency neural network inference
Feb 22, 2021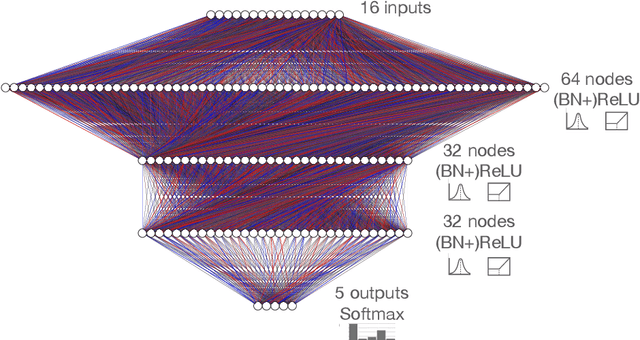

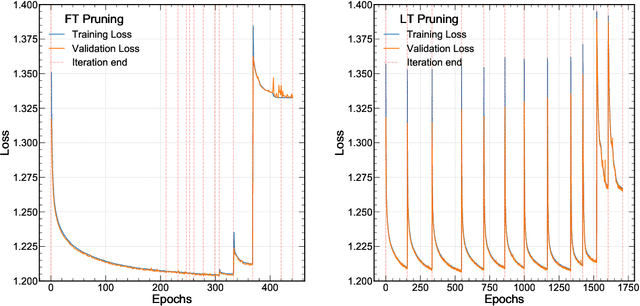
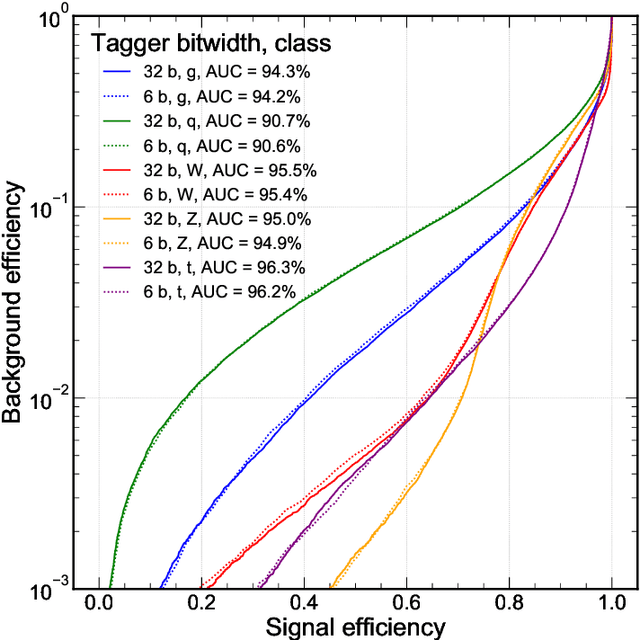
Efficient machine learning implementations optimized for inference in hardware have wide-ranging benefits depending on the application from lower inference latencies to higher data throughputs to more efficient energy consumption. Two popular techniques for reducing computation in neural networks are pruning, removing insignificant synapses, and quantization, reducing the precision of the calculations. In this work, we explore the interplay between pruning and quantization during the training of neural networks for ultra low latency applications targeting high energy physics use cases. However, techniques developed for this study have potential application across many other domains. We study various configurations of pruning during quantization-aware training, which we term \emph{quantization-aware pruning} and the effect of techniques like regularization, batch normalization, and different pruning schemes on multiple computational or neural efficiency metrics. We find that quantization-aware pruning yields more computationally efficient models than either pruning or quantization alone for our task. Further, quantization-aware pruning typically performs similar to or better in terms of computational efficiency compared to standard neural architecture optimization techniques. While the accuracy for the benchmark application may be similar, the information content of the network can vary significantly based on the training configuration.
FAT: Training Neural Networks for Reliable Inference Under Hardware Faults
Nov 11, 2020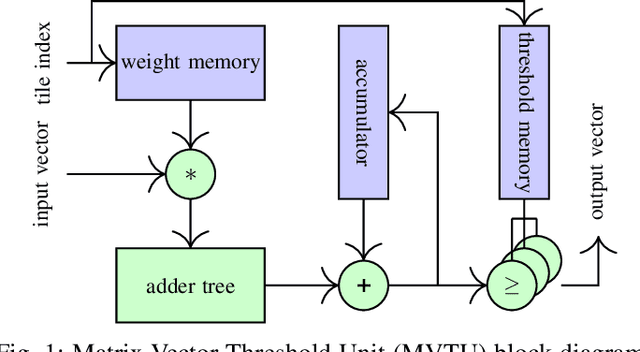
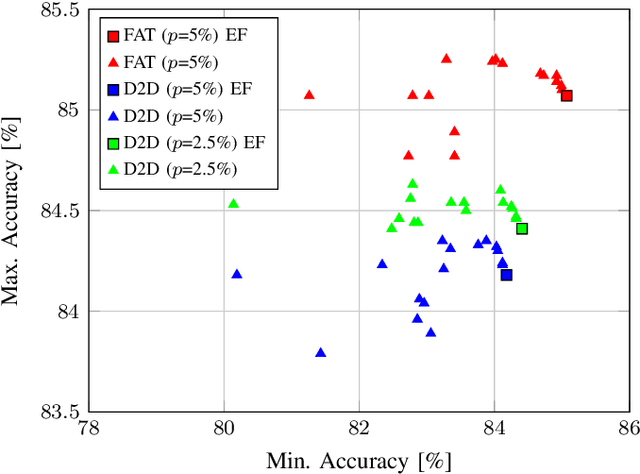
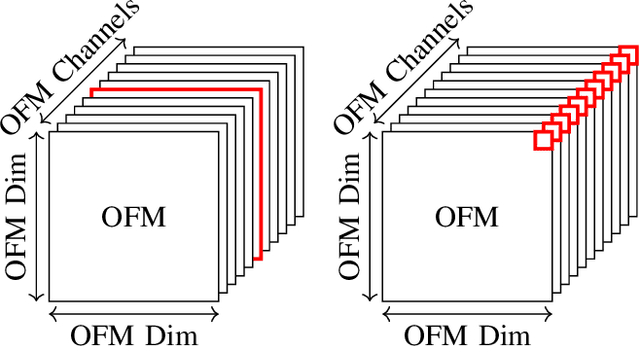
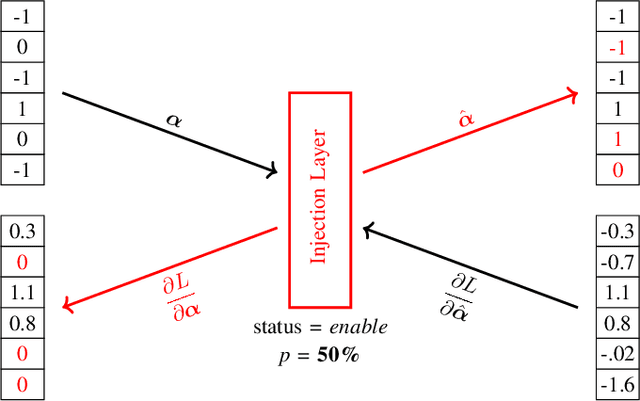
Deep neural networks (DNNs) are state-of-the-art algorithms for multiple applications, spanning from image classification to speech recognition. While providing excellent accuracy, they often have enormous compute and memory requirements. As a result of this, quantized neural networks (QNNs) are increasingly being adopted and deployed especially on embedded devices, thanks to their high accuracy, but also since they have significantly lower compute and memory requirements compared to their floating point equivalents. QNN deployment is also being evaluated for safety-critical applications, such as automotive, avionics, medical or industrial. These systems require functional safety, guaranteeing failure-free behaviour even in the presence of hardware faults. In general fault tolerance can be achieved by adding redundancy to the system, which further exacerbates the overall computational demands and makes it difficult to meet the power and performance requirements. In order to decrease the hardware cost for achieving functional safety, it is vital to explore domain-specific solutions which can exploit the inherent features of DNNs. In this work we present a novel methodology called fault-aware training (FAT), which includes error modeling during neural network (NN) training, to make QNNs resilient to specific fault models on the device. Our experiments show that by injecting faults in the convolutional layers during training, highly accurate convolutional neural networks (CNNs) can be trained which exhibits much better error tolerance compared to the original. Furthermore, we show that redundant systems which are built from QNNs trained with FAT achieve higher worse-case accuracy at lower hardware cost. This has been validated for numerous classification tasks including CIFAR10, GTSRB, SVHN and ImageNet.
LogicNets: Co-Designed Neural Networks and Circuits for Extreme-Throughput Applications
Apr 06, 2020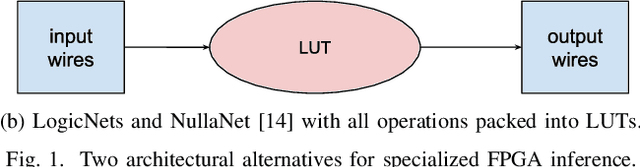

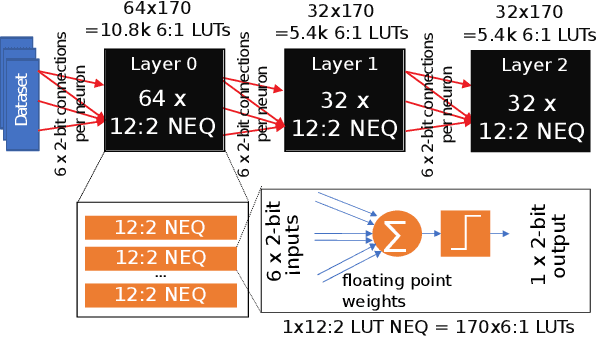
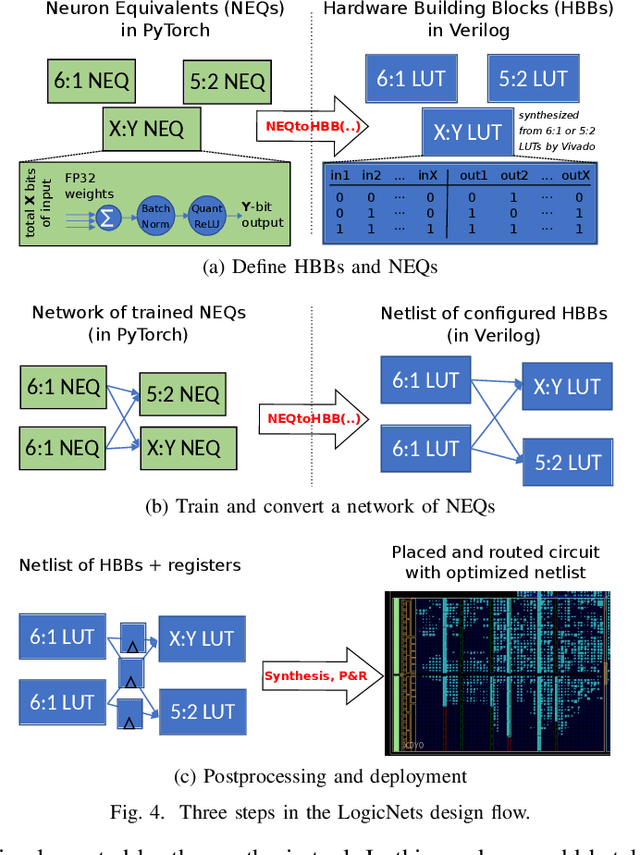
Deployment of deep neural networks for applications that require very high throughput or extremely low latency is a severe computational challenge, further exacerbated by inefficiencies in mapping the computation to hardware. We present a novel method for designing neural network topologies that directly map to a highly efficient FPGA implementation. By exploiting the equivalence of artificial neurons with quantized inputs/outputs and truth tables, we can train quantized neural networks that can be directly converted to a netlist of truth tables, and subsequently deployed as a highly pipelinable, massively parallel FPGA circuit. However, the neural network topology requires careful consideration since the hardware cost of truth tables grows exponentially with neuron fan-in. To obtain smaller networks where the whole netlist can be placed-and-routed onto a single FPGA, we derive a fan-in driven hardware cost model to guide topology design, and combine high sparsity with low-bit activation quantization to limit the neuron fan-in. We evaluate our approach on two tasks with very high intrinsic throughput requirements in high-energy physics and network intrusion detection. We show that the combination of sparsity and low-bit activation quantization results in high-speed circuits with small logic depth and low LUT cost, demonstrating competitive accuracy with less than 15 ns of inference latency and throughput in the hundreds of millions of inferences per second.
Accuracy to Throughput Trade-offs for Reduced Precision Neural Networks on Reconfigurable Logic
Jul 17, 2018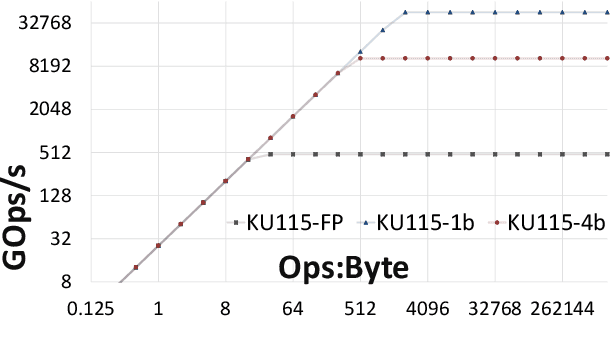
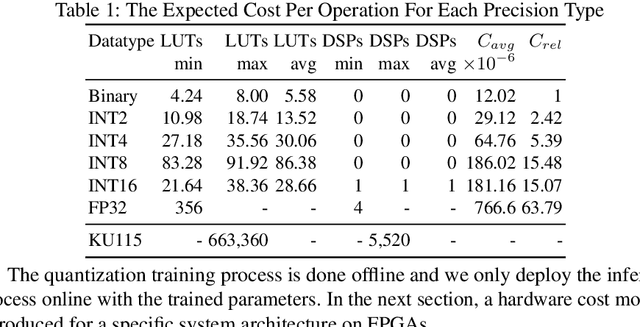

Modern CNN are typically based on floating point linear algebra based implementations. Recently, reduced precision NN have been gaining popularity as they require significantly less memory and computational resources compared to floating point. This is particularly important in power constrained compute environments. However, in many cases a reduction in precision comes at a small cost to the accuracy of the resultant network. In this work, we investigate the accuracy-throughput trade-off for various parameter precision applied to different types of NN models. We firstly propose a quantization training strategy that allows reduced precision NN inference with a lower memory footprint and competitive model accuracy. Then, we quantitatively formulate the relationship between data representation and hardware efficiency. Our experiments finally provide insightful observation. For example, one of our tests show 32-bit floating point is more hardware efficient than 1-bit parameters to achieve 99% MNIST accuracy. In general, 2-bit and 4-bit fixed point parameters show better hardware trade-off on small-scale datasets like MNIST and CIFAR-10 while 4-bit provide the best trade-off in large-scale tasks like AlexNet on ImageNet dataset within our tested problem domain.
Scaling Binarized Neural Networks on Reconfigurable Logic
Jan 27, 2017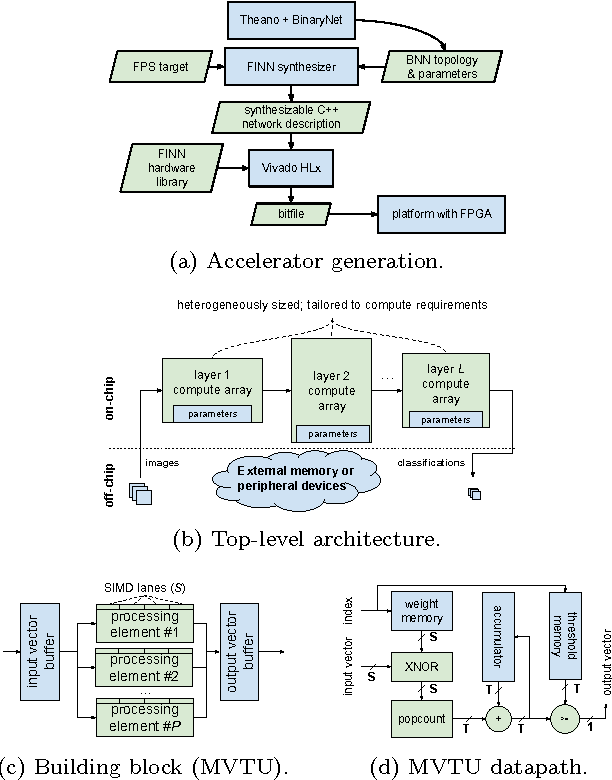

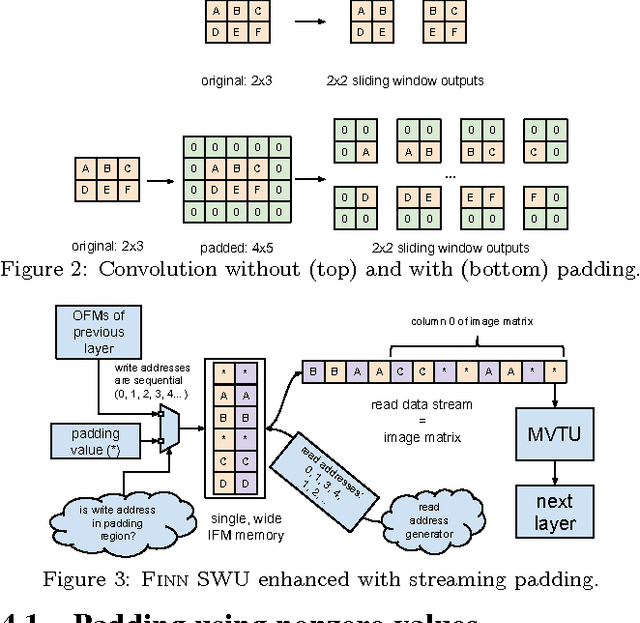
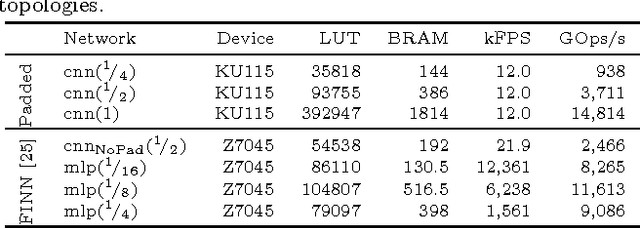
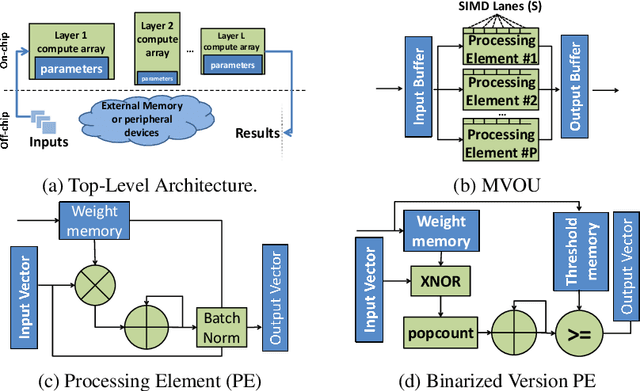
Binarized neural networks (BNNs) are gaining interest in the deep learning community due to their significantly lower computational and memory cost. They are particularly well suited to reconfigurable logic devices, which contain an abundance of fine-grained compute resources and can result in smaller, lower power implementations, or conversely in higher classification rates. Towards this end, the Finn framework was recently proposed for building fast and flexible field programmable gate array (FPGA) accelerators for BNNs. Finn utilized a novel set of optimizations that enable efficient mapping of BNNs to hardware and implemented fully connected, non-padded convolutional and pooling layers, with per-layer compute resources being tailored to user-provided throughput requirements. However, FINN was not evaluated on larger topologies due to the size of the chosen FPGA, and exhibited decreased accuracy due to lack of padding. In this paper, we improve upon Finn to show how padding can be employed on BNNs while still maintaining a 1-bit datapath and high accuracy. Based on this technique, we demonstrate numerous experiments to illustrate flexibility and scalability of the approach. In particular, we show that a large BNN requiring 1.2 billion operations per frame running on an ADM-PCIE-8K5 platform can classify images at 12 kFPS with 671 us latency while drawing less than 41 W board power and classifying CIFAR-10 images at 88.7% accuracy. Our implementation of this network achieves 14.8 trillion operations per second. We believe this is the fastest classification rate reported to date on this benchmark at this level of accuracy.
FINN: A Framework for Fast, Scalable Binarized Neural Network Inference
Dec 01, 2016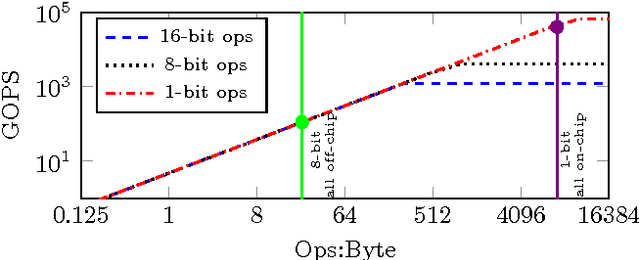

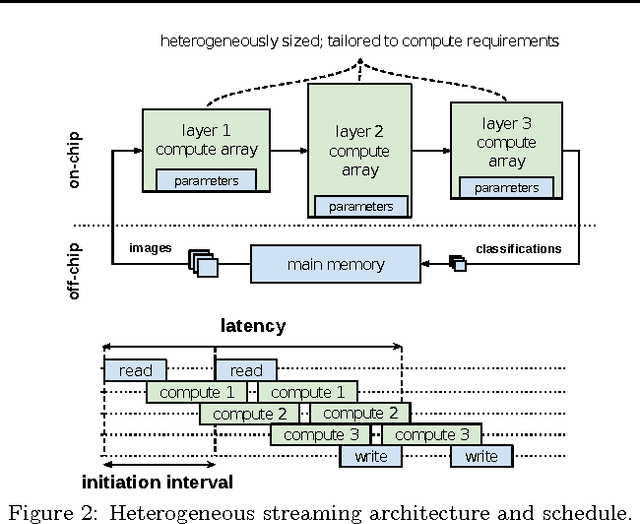
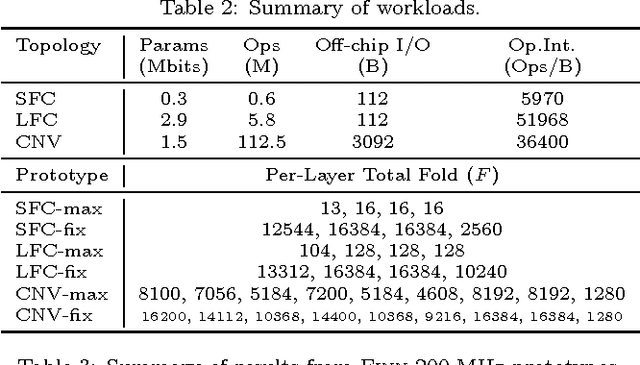
Research has shown that convolutional neural networks contain significant redundancy, and high classification accuracy can be obtained even when weights and activations are reduced from floating point to binary values. In this paper, we present FINN, a framework for building fast and flexible FPGA accelerators using a flexible heterogeneous streaming architecture. By utilizing a novel set of optimizations that enable efficient mapping of binarized neural networks to hardware, we implement fully connected, convolutional and pooling layers, with per-layer compute resources being tailored to user-provided throughput requirements. On a ZC706 embedded FPGA platform drawing less than 25 W total system power, we demonstrate up to 12.3 million image classifications per second with 0.31 {\mu}s latency on the MNIST dataset with 95.8% accuracy, and 21906 image classifications per second with 283 {\mu}s latency on the CIFAR-10 and SVHN datasets with respectively 80.1% and 94.9% accuracy. To the best of our knowledge, ours are the fastest classification rates reported to date on these benchmarks.