 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Self-Driving Trigger at the LHC: Adaptive Response in Real Time
Jan 13, 2026Real-time data filtering and selection -- or trigger -- systems at high-throughput scientific facilities such as the experiments at the Large Hadron Collider (LHC) must process extremely high-rate data streams under stringent bandwidth, latency, and storage constraints. Yet these systems are typically designed as static, hand-tuned menus of selection criteria grounded in prior knowledge and simulation. In this work, we further explore the concept of a self-driving trigger, an autonomous data-filtering framework that reallocates resources and adjusts thresholds dynamically in real-time to optimize signal efficiency, rate stability, and computational cost as instrumentation and environmental conditions evolve. We introduce a benchmark ecosystem to emulate realistic collider scenarios and demonstrate real-time optimization of a menu including canonical energy sum triggers as well as modern anomaly-detection algorithms that target non-standard event topologies using machine learning. Using simulated data streams and publicly available collision data from the Compact Muon Solenoid (CMS) experiment, we demonstrate the capability to dynamically and automatically optimize trigger performance under specific cost objectives without manual retuning. Our adaptive strategy shifts trigger design from static menus with heuristic tuning to intelligent, automated, data-driven control, unlocking greater flexibility and discovery potential in future high-energy physics analyses.
Surrogate Neural Architecture Codesign Package (SNAC-Pack)
Dec 17, 2025
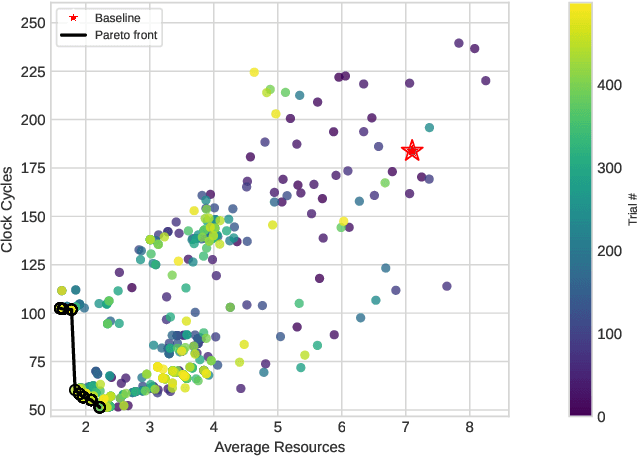

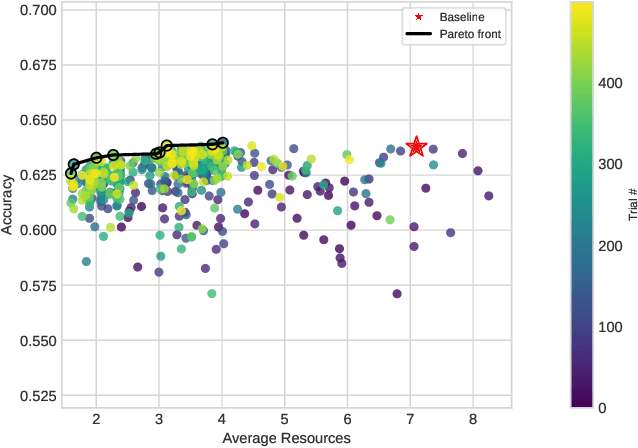
Neural Architecture Search is a powerful approach for automating model design, but existing methods struggle to accurately optimize for real hardware performance, often relying on proxy metrics such as bit operations. We present Surrogate Neural Architecture Codesign Package (SNAC-Pack), an integrated framework that automates the discovery and optimization of neural networks focusing on FPGA deployment. SNAC-Pack combines Neural Architecture Codesign's multi-stage search capabilities with the Resource Utilization and Latency Estimator, enabling multi-objective optimization across accuracy, FPGA resource utilization, and latency without requiring time-intensive synthesis for each candidate model. We demonstrate SNAC-Pack on a high energy physics jet classification task, achieving 63.84% accuracy with resource estimation. When synthesized on a Xilinx Virtex UltraScale+ VU13P FPGA, the SNAC-Pack model matches baseline accuracy while maintaining comparable resource utilization to models optimized using traditional BOPs metrics. This work demonstrates the potential of hardware-aware neural architecture search for resource-constrained deployments and provides an open-source framework for automating the design of efficient FPGA-accelerated models.
AI Benchmark Democratization and Carpentry
Dec 12, 2025Benchmarks are a cornerstone of modern machine learning, enabling reproducibility, comparison, and scientific progress. However, AI benchmarks are increasingly complex, requiring dynamic, AI-focused workflows. Rapid evolution in model architectures, scale, datasets, and deployment contexts makes evaluation a moving target. Large language models often memorize static benchmarks, causing a gap between benchmark results and real-world performance. Beyond traditional static benchmarks, continuous adaptive benchmarking frameworks are needed to align scientific assessment with deployment risks. This calls for skills and education in AI Benchmark Carpentry. From our experience with MLCommons, educational initiatives, and programs like the DOE's Trillion Parameter Consortium, key barriers include high resource demands, limited access to specialized hardware, lack of benchmark design expertise, and uncertainty in relating results to application domains. Current benchmarks often emphasize peak performance on top-tier hardware, offering limited guidance for diverse, real-world scenarios. Benchmarking must become dynamic, incorporating evolving models, updated data, and heterogeneous platforms while maintaining transparency, reproducibility, and interpretability. Democratization requires both technical innovation and systematic education across levels, building sustained expertise in benchmark design and use. Benchmarks should support application-relevant comparisons, enabling informed, context-sensitive decisions. Dynamic, inclusive benchmarking will ensure evaluation keeps pace with AI evolution and supports responsible, reproducible, and accessible AI deployment. Community efforts can provide a foundation for AI Benchmark Carpentry.
wa-hls4ml: A Benchmark and Surrogate Models for hls4ml Resource and Latency Estimation
Nov 06, 2025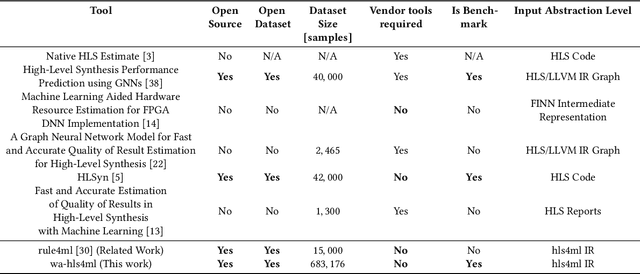
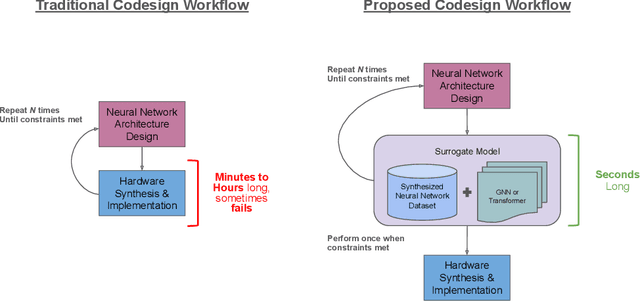

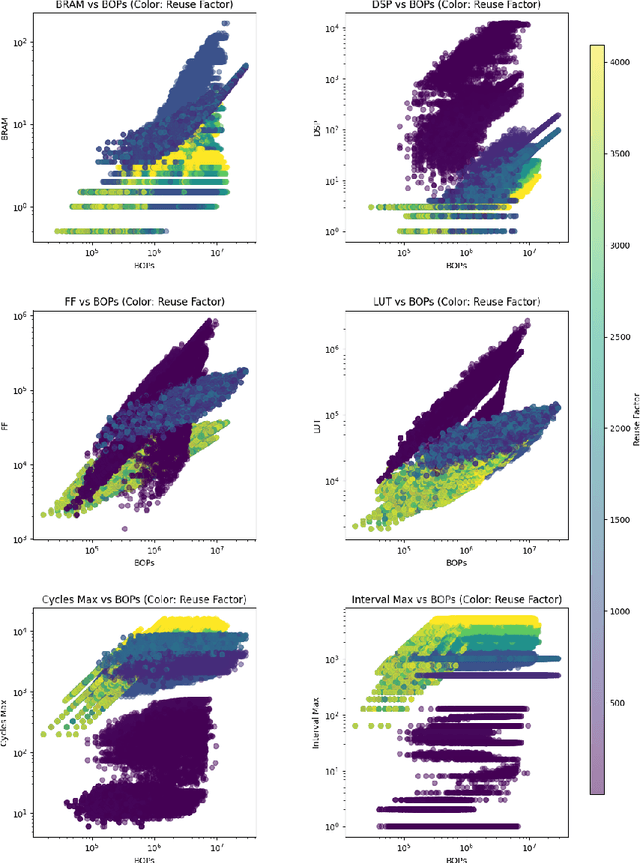
As machine learning (ML) is increasingly implemented in hardware to address real-time challenges in scientific applications, the development of advanced toolchains has significantly reduced the time required to iterate on various designs. These advancements have solved major obstacles, but also exposed new challenges. For example, processes that were not previously considered bottlenecks, such as hardware synthesis, are becoming limiting factors in the rapid iteration of designs. To mitigate these emerging constraints, multiple efforts have been undertaken to develop an ML-based surrogate model that estimates resource usage of ML accelerator architectures. We introduce wa-hls4ml, a benchmark for ML accelerator resource and latency estimation, and its corresponding initial dataset of over 680,000 fully connected and convolutional neural networks, all synthesized using hls4ml and targeting Xilinx FPGAs. The benchmark evaluates the performance of resource and latency predictors against several common ML model architectures, primarily originating from scientific domains, as exemplar models, and the average performance across a subset of the dataset. Additionally, we introduce GNN- and transformer-based surrogate models that predict latency and resources for ML accelerators. We present the architecture and performance of the models and find that the models generally predict latency and resources for the 75% percentile within several percent of the synthesized resources on the synthetic test dataset.
An MLCommons Scientific Benchmarks Ontology
Nov 06, 2025



Scientific machine learning research spans diverse domains and data modalities, yet existing benchmark efforts remain siloed and lack standardization. This makes novel and transformative applications of machine learning to critical scientific use-cases more fragmented and less clear in pathways to impact. This paper introduces an ontology for scientific benchmarking developed through a unified, community-driven effort that extends the MLCommons ecosystem to cover physics, chemistry, materials science, biology, climate science, and more. Building on prior initiatives such as XAI-BENCH, FastML Science Benchmarks, PDEBench, and the SciMLBench framework, our effort consolidates a large set of disparate benchmarks and frameworks into a single taxonomy of scientific, application, and system-level benchmarks. New benchmarks can be added through an open submission workflow coordinated by the MLCommons Science Working Group and evaluated against a six-category rating rubric that promotes and identifies high-quality benchmarks, enabling stakeholders to select benchmarks that meet their specific needs. The architecture is extensible, supporting future scientific and AI/ML motifs, and we discuss methods for identifying emerging computing patterns for unique scientific workloads. The MLCommons Science Benchmarks Ontology provides a standardized, scalable foundation for reproducible, cross-domain benchmarking in scientific machine learning. A companion webpage for this work has also been developed as the effort evolves: https://mlcommons-science.github.io/benchmark/
Real-Time Cell Sorting with Scalable In Situ FPGA-Accelerated Deep Learning
Mar 16, 2025Precise cell classification is essential in biomedical diagnostics and therapeutic monitoring, particularly for identifying diverse cell types involved in various diseases. Traditional cell classification methods such as flow cytometry depend on molecular labeling which is often costly, time-intensive, and can alter cell integrity. To overcome these limitations, we present a label-free machine learning framework for cell classification, designed for real-time sorting applications using bright-field microscopy images. This approach leverages a teacher-student model architecture enhanced by knowledge distillation, achieving high efficiency and scalability across different cell types. Demonstrated through a use case of classifying lymphocyte subsets, our framework accurately classifies T4, T8, and B cell types with a dataset of 80,000 preprocessed images, accessible via an open-source Python package for easy adaptation. Our teacher model attained 98\% accuracy in differentiating T4 cells from B cells and 93\% accuracy in zero-shot classification between T8 and B cells. Remarkably, our student model operates with only 0.02\% of the teacher model's parameters, enabling field-programmable gate array (FPGA) deployment. Our FPGA-accelerated student model achieves an ultra-low inference latency of just 14.5~$\mu$s and a complete cell detection-to-sorting trigger time of 24.7~$\mu$s, delivering 12x and 40x improvements over the previous state-of-the-art real-time cell analysis algorithm in inference and total latency, respectively, while preserving accuracy comparable to the teacher model. This framework provides a scalable, cost-effective solution for lymphocyte classification, as well as a new SOTA real-time cell sorting implementation for rapid identification of subsets using in situ deep learning on off-the-shelf computing hardware.
Loss Landscape Analysis for Reliable Quantized ML Models for Scientific Sensing
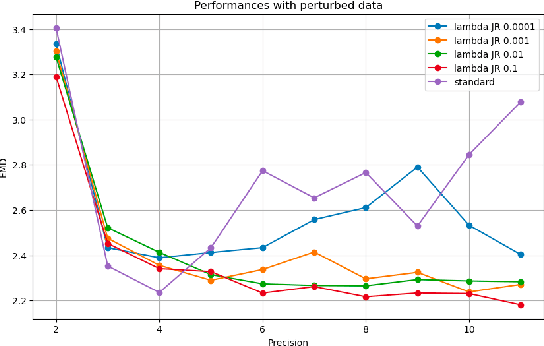
Feb 12, 2025In this paper, we propose a method to perform empirical analysis of the loss landscape of machine learning (ML) models. The method is applied to two ML models for scientific sensing, which necessitates quantization to be deployed and are subject to noise and perturbations due to experimental conditions. Our method allows assessing the robustness of ML models to such effects as a function of quantization precision and under different regularization techniques -- two crucial concerns that remained underexplored so far. By investigating the interplay between performance, efficiency, and robustness by means of loss landscape analysis, we both established a strong correlation between gently-shaped landscapes and robustness to input and weight perturbations and observed other intriguing and non-obvious phenomena. Our method allows a systematic exploration of such trade-offs a priori, i.e., without training and testing multiple models, leading to more efficient development workflows. This work also highlights the importance of incorporating robustness into the Pareto optimization of ML models, enabling more reliable and adaptive scientific sensing systems.
End-to-end workflow for machine learning-based qubit readout with QICK and hls4ml
Jan 24, 2025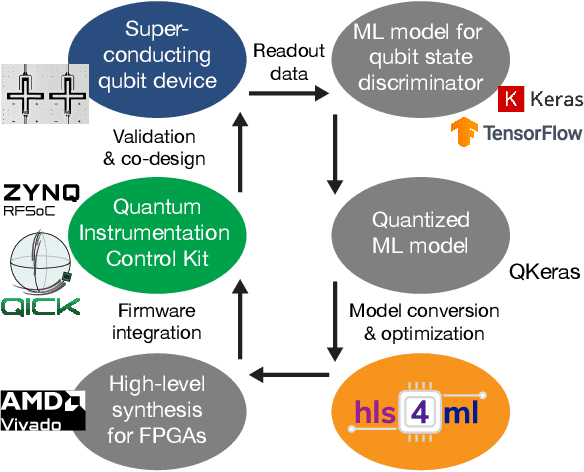
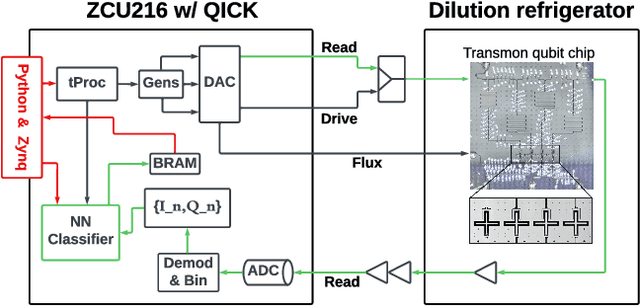
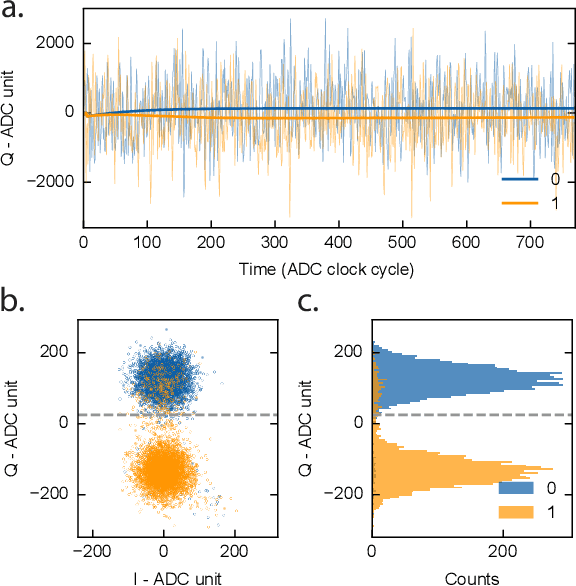

We present an end-to-end workflow for superconducting qubit readout that embeds co-designed Neural Networks (NNs) into the Quantum Instrumentation Control Kit (QICK). Capitalizing on the custom firmware and software of the QICK platform, which is built on Xilinx RFSoC FPGAs, we aim to leverage machine learning (ML) to address critical challenges in qubit readout accuracy and scalability. The workflow utilizes the hls4ml package and employs quantization-aware training to translate ML models into hardware-efficient FPGA implementations via user-friendly Python APIs. We experimentally demonstrate the design, optimization, and integration of an ML algorithm for single transmon qubit readout, achieving 96% single-shot fidelity with a latency of 32ns and less than 16% FPGA look-up table resource utilization. Our results offer the community an accessible workflow to advance ML-driven readout and adaptive control in quantum information processing applications.
Neural Architecture Codesign for Fast Physics Applications
Jan 09, 2025



We develop a pipeline to streamline neural architecture codesign for physics applications to reduce the need for ML expertise when designing models for novel tasks. Our method employs neural architecture search and network compression in a two-stage approach to discover hardware efficient models. This approach consists of a global search stage that explores a wide range of architectures while considering hardware constraints, followed by a local search stage that fine-tunes and compresses the most promising candidates. We exceed performance on various tasks and show further speedup through model compression techniques such as quantization-aware-training and neural network pruning. We synthesize the optimal models to high level synthesis code for FPGA deployment with the hls4ml library. Additionally, our hierarchical search space provides greater flexibility in optimization, which can easily extend to other tasks and domains. We demonstrate this with two case studies: Bragg peak finding in materials science and jet classification in high energy physics, achieving models with improved accuracy, smaller latencies, or reduced resource utilization relative to the baseline models.
Reliable edge machine learning hardware for scientific applications
Jun 27, 2024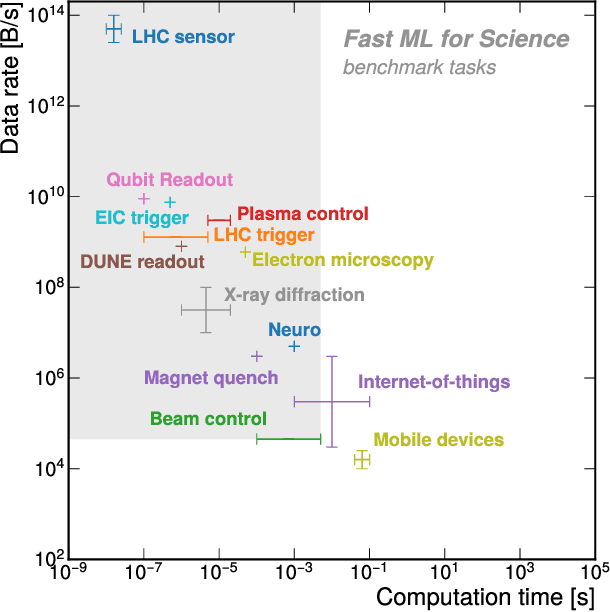
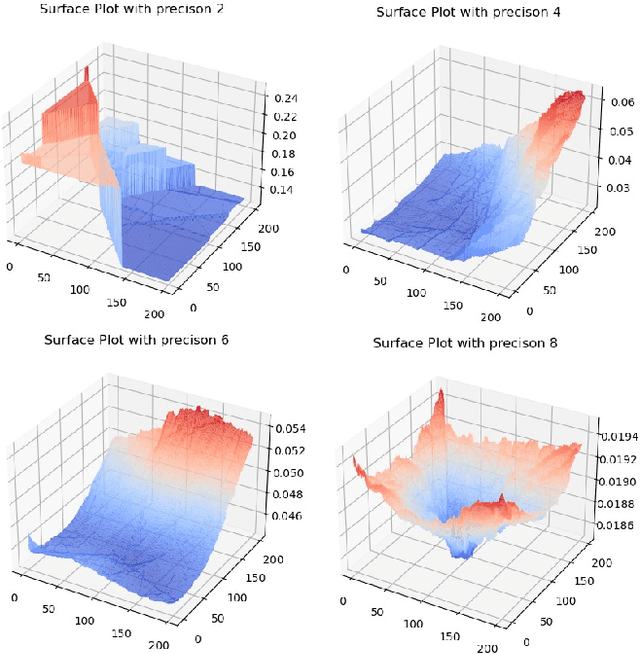
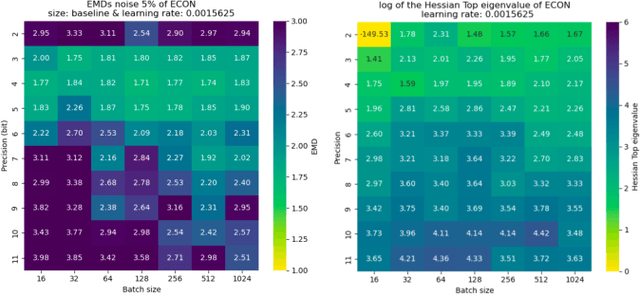
Extreme data rate scientific experiments create massive amounts of data that require efficient ML edge processing. This leads to unique validation challenges for VLSI implementations of ML algorithms: enabling bit-accurate functional simulations for performance validation in experimental software frameworks, verifying those ML models are robust under extreme quantization and pruning, and enabling ultra-fine-grained model inspection for efficient fault tolerance. We discuss approaches to developing and validating reliable algorithms at the scientific edge under such strict latency, resource, power, and area requirements in extreme experimental environments. We study metrics for developing robust algorithms, present preliminary results and mitigation strategies, and conclude with an outlook of these and future directions of research towards the longer-term goal of developing autonomous scientific experimentation methods for accelerated scientific discovery.