 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhys4D: Fine-Grained Physics-Consistent 4D Modeling from Video Diffusion
Mar 03, 2026Recent video diffusion models have achieved impressive capabilities as large-scale generative world models. However, these models often struggle with fine-grained physical consistency, exhibiting physically implausible dynamics over time. In this work, we present \textbf{Phys4D}, a pipeline for learning physics-consistent 4D world representations from video diffusion models. Phys4D adopts \textbf{a three-stage training paradigm} that progressively lifts appearance-driven video diffusion models into physics-consistent 4D world representations. We first bootstrap robust geometry and motion representations through large-scale pseudo-supervised pretraining, establishing a foundation for 4D scene modeling. We then perform physics-grounded supervised fine-tuning using simulation-generated data, enforcing temporally consistent 4D dynamics. Finally, we apply simulation-grounded reinforcement learning to correct residual physical violations that are difficult to capture through explicit supervision. To evaluate fine-grained physical consistency beyond appearance-based metrics, we introduce a set of \textbf{4D world consistency evaluation} that probe geometric coherence, motion stability, and long-horizon physical plausibility. Experimental results demonstrate that Phys4D substantially improves fine-grained spatiotemporal and physical consistency compared to appearance-driven baselines, while maintaining strong generative performance. Our project page is available at https://sensational-brioche-7657e7.netlify.app/
PhyPrompt: RL-based Prompt Refinement for Physically Plausible Text-to-Video Generation
Mar 03, 2026State-of-the-art text-to-video (T2V) generators frequently violate physical laws despite high visual quality. We show this stems from insufficient physical constraints in prompts rather than model limitations: manually adding physics details reliably produces physically plausible videos, but requires expertise and does not scale. We present PhyPrompt, a two-stage reinforcement learning framework that automatically refines prompts for physically realistic generation. First, we fine-tune a large language model on a physics-focused Chain-of-Thought dataset to integrate principles like object motion and force interactions while preserving user intent. Second, we apply Group Relative Policy Optimization with a dynamic reward curriculum that initially prioritizes semantic fidelity, then progressively shifts toward physical commonsense. This curriculum achieves synergistic optimization: PhyPrompt-7B reaches 40.8\% joint success on VideoPhy2 (8.6pp gain), improving physical commonsense by 11pp (55.8\% to 66.8\%) while simultaneously increasing semantic adherence by 4.4pp (43.4\% to 47.8\%). Remarkably, our curriculum exceeds single-objective training on both metrics, demonstrating compositional prompt discovery beyond conventional multi-objective trade-offs. PhyPrompt outperforms GPT-4o (+3.8\% joint) and DeepSeek-V3 (+2.2\%, 100$\times$ larger) using only 7B parameters. The approach transfers zero-shot across diverse T2V architectures (Lavie, VideoCrafter2, CogVideoX-5B) with up to 16.8\% improvement, establishing that domain-specialized reinforcement learning with compositional curricula surpasses general-purpose scaling for physics-aware generation.
Towards Sparse Video Understanding and Reasoning
Feb 14, 2026We present \revise (\underline{Re}asoning with \underline{Vi}deo \underline{S}parsity), a multi-round agent for video question answering (VQA). Instead of uniformly sampling frames, \revise selects a small set of informative frames, maintains a summary-as-state across rounds, and stops early when confident. It supports proprietary vision-language models (VLMs) in a ``plug-and-play'' setting and enables reinforcement fine-tuning for open-source models. For fine-tuning, we introduce EAGER (Evidence-Adjusted Gain for Efficient Reasoning), an annotation-free reward with three terms: (1) Confidence gain: after new frames are added, we reward the increase in the log-odds gap between the correct option and the strongest alternative; (2) Summary sufficiency: at answer time we re-ask using only the last committed summary and reward success; (3) Correct-and-early stop: answering correctly within a small turn budget is rewarded. Across multiple VQA benchmarks, \revise improves accuracy while reducing frames, rounds, and prompt tokens, demonstrating practical sparse video reasoning.
LLM-based Text Simplification and its Effect on User Comprehension and Cognitive Load
May 04, 2025Information on the web, such as scientific publications and Wikipedia, often surpasses users' reading level. To help address this, we used a self-refinement approach to develop a LLM capability for minimally lossy text simplification. To validate our approach, we conducted a randomized study involving 4563 participants and 31 texts spanning 6 broad subject areas: PubMed (biomedical scientific articles), biology, law, finance, literature/philosophy, and aerospace/computer science. Participants were randomized to viewing original or simplified texts in a subject area, and answered multiple-choice questions (MCQs) that tested their comprehension of the text. The participants were also asked to provide qualitative feedback such as task difficulty. Our results indicate that participants who read the simplified text answered more MCQs correctly than their counterparts who read the original text (3.9% absolute increase, p<0.05). This gain was most striking with PubMed (14.6%), while more moderate gains were observed for finance (5.5%), aerospace/computer science (3.8%) domains, and legal (3.5%). Notably, the results were robust to whether participants could refer back to the text while answering MCQs. The absolute accuracy decreased by up to ~9% for both original and simplified setups where participants could not refer back to the text, but the ~4% overall improvement persisted. Finally, participants' self-reported perceived ease based on a simplified NASA Task Load Index was greater for those who read the simplified text (absolute change on a 5-point scale 0.33, p<0.05). This randomized study, involving an order of magnitude more participants than prior works, demonstrates the potential of LLMs to make complex information easier to understand. Our work aims to enable a broader audience to better learn and make use of expert knowledge available on the web, improving information accessibility.
Adaptive Batch Size Schedules for Distributed Training of Language Models with Data and Model Parallelism
Dec 30, 2024
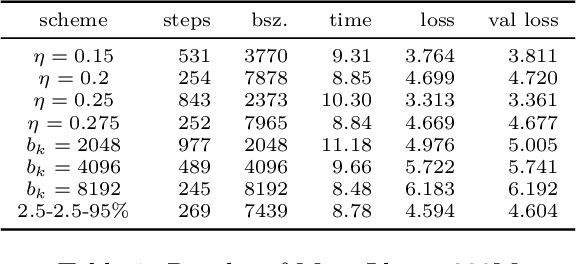

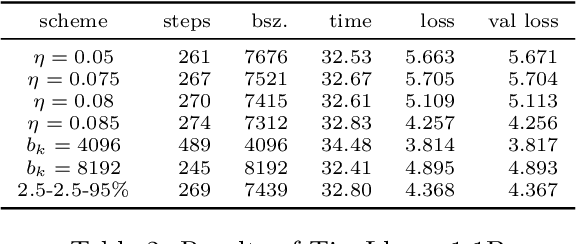
An appropriate choice of batch sizes in large-scale model training is crucial, yet it involves an intrinsic yet inevitable dilemma: large-batch training improves training efficiency in terms of memory utilization, while generalization performance often deteriorates due to small amounts of gradient noise. Despite this dilemma, the common practice of choosing batch sizes in language model training often prioritizes training efficiency -- employing either constant large sizes with data parallelism or implementing batch size warmup schedules. However, such batch size schedule designs remain heuristic and often fail to adapt to training dynamics, presenting the challenge of designing adaptive batch size schedules. Given the abundance of available datasets and the data-hungry nature of language models, data parallelism has become an indispensable distributed training paradigm, enabling the use of larger batch sizes for gradient computation. However, vanilla data parallelism requires replicas of model parameters, gradients, and optimizer states at each worker, which prohibits training larger models with billions of parameters. To optimize memory usage, more advanced parallelism strategies must be employed. In this work, we propose general-purpose and theoretically principled adaptive batch size schedules compatible with data parallelism and model parallelism. We develop a practical implementation with PyTorch Fully Sharded Data Parallel, facilitating the pretraining of language models of different sizes. We empirically demonstrate that our proposed approaches outperform constant batch sizes and heuristic batch size warmup schedules in the pretraining of models in the Llama family, with particular focus on smaller models with up to 3 billion parameters. We also establish theoretical convergence guarantees for such adaptive batch size schedules with Adam for general smooth nonconvex objectives.
AlignAb: Pareto-Optimal Energy Alignment for Designing Nature-Like Antibodies
Dec 30, 2024We present a three-stage framework for training deep learning models specializing in antibody sequence-structure co-design. We first pre-train a language model using millions of antibody sequence data. Then, we employ the learned representations to guide the training of a diffusion model for joint optimization over both sequence and structure of antibodies. During the final alignment stage, we optimize the model to favor antibodies with low repulsion and high attraction to the antigen binding site, enhancing the rationality and functionality of the designs. To mitigate conflicting energy preferences, we extend AbDPO (Antibody Direct Preference Optimization) to guide the model towards Pareto optimality under multiple energy-based alignment objectives. Furthermore, we adopt an iterative learning paradigm with temperature scaling, enabling the model to benefit from diverse online datasets without requiring additional data. In practice, our proposed methods achieve high stability and efficiency in producing a better Pareto front of antibody designs compared to top samples generated by baselines and previous alignment techniques. Through extensive experiments, we showcase the superior performance of our methods in generating nature-like antibodies with high binding affinity consistently.
Communication-Efficient Adaptive Batch Size Strategies for Distributed Local Gradient Methods
Jun 20, 2024



Modern deep neural networks often require distributed training with many workers due to their large size. As worker numbers increase, communication overheads become the main bottleneck in data-parallel minibatch stochastic gradient methods with per-iteration gradient synchronization. Local gradient methods like Local SGD reduce communication by only syncing after several local steps. Despite understanding their convergence in i.i.d. and heterogeneous settings and knowing the importance of batch sizes for efficiency and generalization, optimal local batch sizes are difficult to determine. We introduce adaptive batch size strategies for local gradient methods that increase batch sizes adaptively to reduce minibatch gradient variance. We provide convergence guarantees under homogeneous data conditions and support our claims with image classification experiments, demonstrating the effectiveness of our strategies in training and generalization.
BiSHop: Bi-Directional Cellular Learning for Tabular Data with Generalized Sparse Modern Hopfield Model
Apr 04, 2024



We introduce the \textbf{B}i-Directional \textbf{S}parse \textbf{Hop}field Network (\textbf{BiSHop}), a novel end-to-end framework for deep tabular learning. BiSHop handles the two major challenges of deep tabular learning: non-rotationally invariant data structure and feature sparsity in tabular data. Our key motivation comes from the recent established connection between associative memory and attention mechanisms. Consequently, BiSHop uses a dual-component approach, sequentially processing data both column-wise and row-wise through two interconnected directional learning modules. Computationally, these modules house layers of generalized sparse modern Hopfield layers, a sparse extension of the modern Hopfield model with adaptable sparsity. Methodologically, BiSHop facilitates multi-scale representation learning, capturing both intra-feature and inter-feature interactions, with adaptive sparsity at each scale. Empirically, through experiments on diverse real-world datasets, we demonstrate that BiSHop surpasses current SOTA methods with significantly less HPO runs, marking it a robust solution for deep tabular learning.
SMUTF: Schema Matching Using Generative Tags and Hybrid Features
Feb 06, 2024



We introduce SMUTF, a unique approach for large-scale tabular data schema matching (SM), which assumes that supervised learning does not affect performance in open-domain tasks, thereby enabling effective cross-domain matching. This system uniquely combines rule-based feature engineering, pre-trained language models, and generative large language models. In an innovative adaptation inspired by the Humanitarian Exchange Language, we deploy 'generative tags' for each data column, enhancing the effectiveness of SM. SMUTF exhibits extensive versatility, working seamlessly with any pre-existing pre-trained embeddings, classification methods, and generative models. Recognizing the lack of extensive, publicly available datasets for SM, we have created and open-sourced the HDXSM dataset from the public humanitarian data. We believe this to be the most exhaustive SM dataset currently available. In evaluations across various public datasets and the novel HDXSM dataset, SMUTF demonstrated exceptional performance, surpassing existing state-of-the-art models in terms of accuracy and efficiency, and} improving the F1 score by 11.84% and the AUC of ROC by 5.08%.
Beyond PID Controllers: PPO with Neuralized PID Policy for Proton Beam Intensity Control in Mu2e
Dec 28, 2023
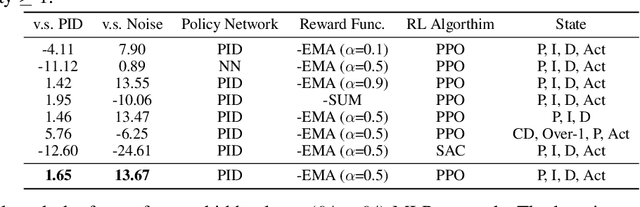
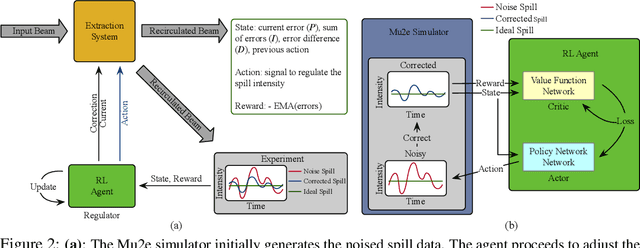

We introduce a novel Proximal Policy Optimization (PPO) algorithm aimed at addressing the challenge of maintaining a uniform proton beam intensity delivery in the Muon to Electron Conversion Experiment (Mu2e) at Fermi National Accelerator Laboratory (Fermilab). Our primary objective is to regulate the spill process to ensure a consistent intensity profile, with the ultimate goal of creating an automated controller capable of providing real-time feedback and calibration of the Spill Regulation System (SRS) parameters on a millisecond timescale. We treat the Mu2e accelerator system as a Markov Decision Process suitable for Reinforcement Learning (RL), utilizing PPO to reduce bias and enhance training stability. A key innovation in our approach is the integration of a neuralized Proportional-Integral-Derivative (PID) controller into the policy function, resulting in a significant improvement in the Spill Duty Factor (SDF) by 13.6%, surpassing the performance of the current PID controller baseline by an additional 1.6%. This paper presents the preliminary offline results based on a differentiable simulator of the Mu2e accelerator. It paves the groundwork for real-time implementations and applications, representing a crucial step towards automated proton beam intensity control for the Mu2e experiment.