 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Statistical Rates of Conditional Diffusion Transformers: Approximation, Estimation and Minimax Optimality
Nov 26, 2024



We investigate the approximation and estimation rates of conditional diffusion transformers (DiTs) with classifier-free guidance. We present a comprehensive analysis for ``in-context'' conditional DiTs under four common data assumptions. We show that both conditional DiTs and their latent variants lead to the minimax optimality of unconditional DiTs under identified settings. Specifically, we discretize the input domains into infinitesimal grids and then perform a term-by-term Taylor expansion on the conditional diffusion score function under H\"older smooth data assumption. This enables fine-grained use of transformers' universal approximation through a more detailed piecewise constant approximation and hence obtains tighter bounds. Additionally, we extend our analysis to the latent setting under the linear latent subspace assumption. We not only show that latent conditional DiTs achieve lower bounds than conditional DiTs both in approximation and estimation, but also show the minimax optimality of latent unconditional DiTs. Our findings establish statistical limits for conditional and unconditional DiTs, and offer practical guidance toward developing more efficient and accurate DiT models.
Two Tales of Persona in LLMs: A Survey of Role-Playing and Personalization
Jun 03, 2024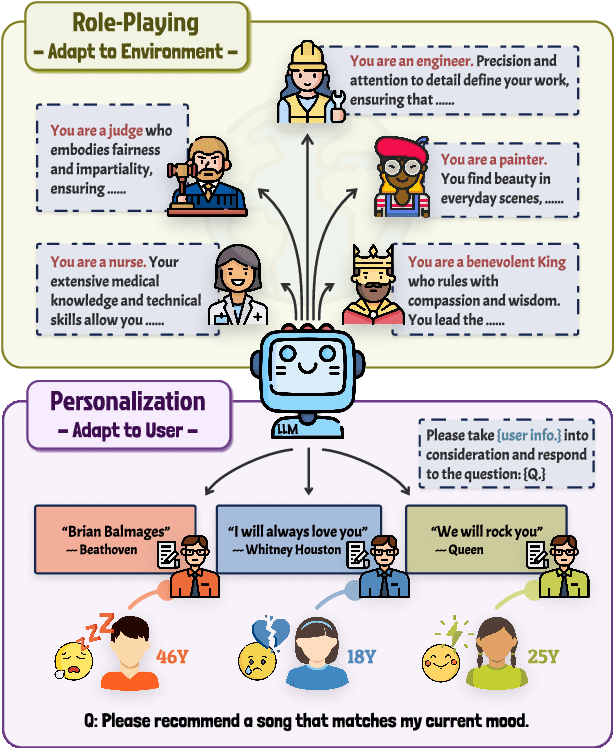

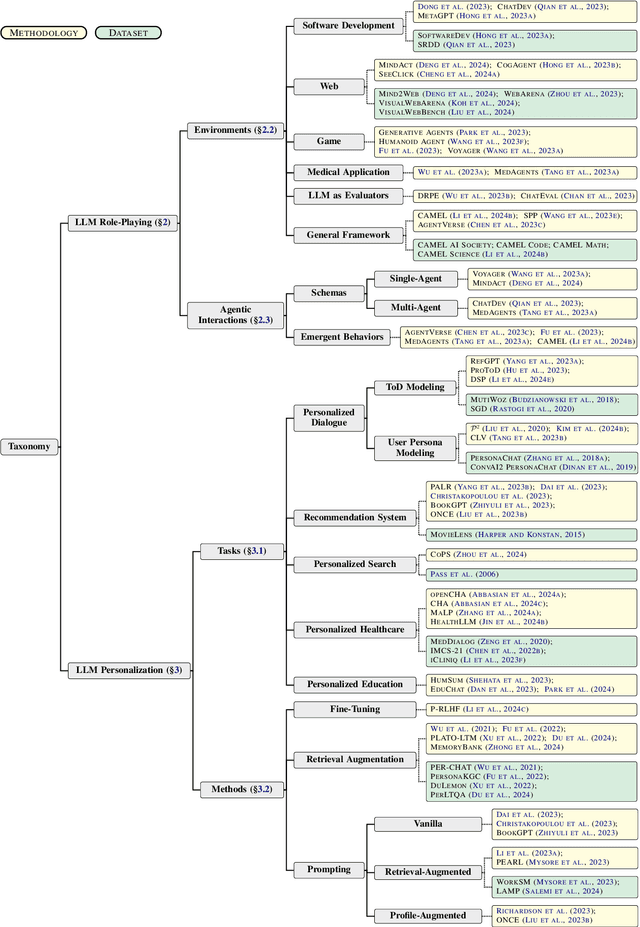
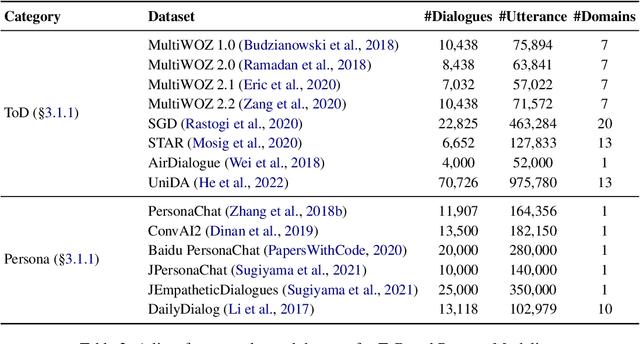
Recently, methods investigating how to adapt large language models (LLMs) for specific scenarios have gained great attention. Particularly, the concept of \textit{persona}, originally adopted in dialogue literature, has re-surged as a promising avenue. However, the growing research on persona is relatively disorganized, lacking a systematic overview. To close the gap, we present a comprehensive survey to categorize the current state of the field. We identify two lines of research, namely (1) LLM Role-Playing, where personas are assigned to LLMs, and (2) LLM Personalization, where LLMs take care of user personas. To the best of our knowledge, we present the first survey tailored for LLM role-playing and LLM personalization under the unified view of persona, including taxonomy, current challenges, and potential directions. To foster future endeavors, we actively maintain a paper collection available to the community: https://github.com/MiuLab/PersonaLLM-Survey
BiSHop: Bi-Directional Cellular Learning for Tabular Data with Generalized Sparse Modern Hopfield Model
Apr 04, 2024



We introduce the \textbf{B}i-Directional \textbf{S}parse \textbf{Hop}field Network (\textbf{BiSHop}), a novel end-to-end framework for deep tabular learning. BiSHop handles the two major challenges of deep tabular learning: non-rotationally invariant data structure and feature sparsity in tabular data. Our key motivation comes from the recent established connection between associative memory and attention mechanisms. Consequently, BiSHop uses a dual-component approach, sequentially processing data both column-wise and row-wise through two interconnected directional learning modules. Computationally, these modules house layers of generalized sparse modern Hopfield layers, a sparse extension of the modern Hopfield model with adaptable sparsity. Methodologically, BiSHop facilitates multi-scale representation learning, capturing both intra-feature and inter-feature interactions, with adaptive sparsity at each scale. Empirically, through experiments on diverse real-world datasets, we demonstrate that BiSHop surpasses current SOTA methods with significantly less HPO runs, marking it a robust solution for deep tabular learning.