 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Models for Adaptive Sequential Data Generation
Jun 04, 2026Generating realistic synthetic sequential data is critical in real-world applications across operations research, finance, healthcare, energy systems, and scientific computing, where time-indexed observations are used for prediction, simulation, risk assessment, and data-driven decision-making. While diffusion models have achieved remarkable success in generating static data, their direct extensions to sequential settings often fail to capture temporal dependence and information structure. Designing diffusion models that can simulate sequential data in an adapted manner, and hence without anticipation of future information, therefore remains an open challenge. In this work, we propose a sequential forward-backward diffusion framework for adapted time series generation. Our approach progressively injects and removes noise along the sequence, conditioning on the previously generated history to ensure adaptiveness. A novel score-matching objective is introduced for efficient parallel training. We derive rigorous statistical guarantees under a generic framework, then establish score approximation, score estimation, and distribution estimation results with ReLU networks serving as a concrete instance. Empirically, we validate our method on synthetic data, including ARMA models and Gaussian processes, and demonstrate its effectiveness in constructing mean-variance optimal portfolios.
CreFlow: Corrective Reflow for Sparse-Reward Embodied Video Diffusion RL
May 14, 2026Video generation models trained on heterogeneous data with likelihood-surrogate objectives can produce visually plausible rollouts that violate physical constraints in embodied manipulation. Although reinforcement-learning post-training offers a natural route to adapting VGMs, existing video-RL rewards often reduce each rollout to a low-level visual metric, whereas manipulation video evaluation requires logic-based verification of whether the rollout satisfies a compositional task specification. To fill this gap, we introduce a compositional constraint-based reward model for post-training embodied video generation models, which automatically formulates task requirements as a composition of Linear Temporal Logic constraints, providing faithful rewards and localized error information in generated videos. To achieve effective improvement in high-dimensional video generation using these reward signals, we further propose CreFlow, a novel online RL framework with two key designs: i) a credit-aware NFT loss that confines the RL update to reward-relevant regions, preventing perturbations to unrelated regions during post-training; and ii) a corrective reflow loss that leverages within-group positive samples as an explicit estimate of the correction direction, stabilizing and accelerating training. Experiments show that CreFlow yields reward judgments better aligned with human and simulator success labels than existing methods and improves downstream execution success by 23.8 percentage points across eight bimanual manipulation tasks.
Diffusion Model for Manifold Data: Score Decomposition, Curvature, and Statistical Complexity
Mar 21, 2026Diffusion models have become a leading framework in generative modeling, yet their theoretical understanding -- especially for high-dimensional data concentrated on low-dimensional structures -- remains incomplete. This paper investigates how diffusion models learn such structured data, focusing on two key aspects: statistical complexity and influence of data geometric properties. By modeling data as samples from a smooth Riemannian manifold, our analysis reveals crucial decompositions of score functions in diffusion models under different levels of injected noise. We also highlight the interplay of manifold curvature with the structures in the score function. These analyses enable an efficient neural network approximation to the score function, built upon which we further provide statistical rates for score estimation and distribution learning. Remarkably, the obtained statistical rates are governed by the intrinsic dimension of data and the manifold curvature. These results advance the statistical foundations of diffusion models, bridging theory and practice for generative modeling on manifolds.
Training-Free Adaptation of Diffusion Models via Doob's $h$-Transform
Feb 18, 2026Adaptation methods have been a workhorse for unlocking the transformative power of pre-trained diffusion models in diverse applications. Existing approaches often abstract adaptation objectives as a reward function and steer diffusion models to generate high-reward samples. However, these approaches can incur high computational overhead due to additional training, or rely on stringent assumptions on the reward such as differentiability. Moreover, despite their empirical success, theoretical justification and guarantees are seldom established. In this paper, we propose DOIT (Doob-Oriented Inference-time Transformation), a training-free and computationally efficient adaptation method that applies to generic, non-differentiable rewards. The key framework underlying our method is a measure transport formulation that seeks to transport the pre-trained generative distribution to a high-reward target distribution. We leverage Doob's $h$-transform to realize this transport, which induces a dynamic correction to the diffusion sampling process and enables efficient simulation-based computation without modifying the pre-trained model. Theoretically, we establish a high probability convergence guarantee to the target high-reward distribution via characterizing the approximation error in the dynamic Doob's correction. Empirically, on D4RL offline RL benchmarks, our method consistently outperforms state-of-the-art baselines while preserving sampling efficiency.
Diffusion Transformers for Imputation: Statistical Efficiency and Uncertainty Quantification
Oct 02, 2025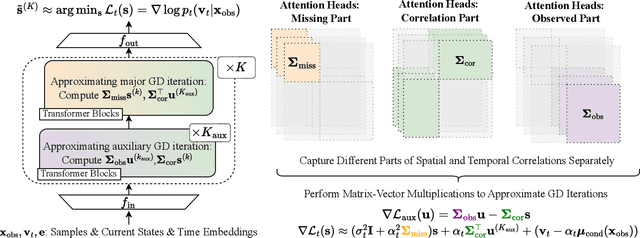

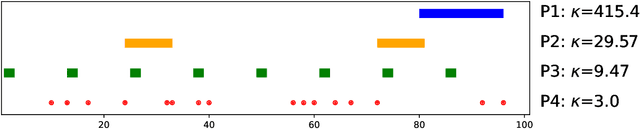
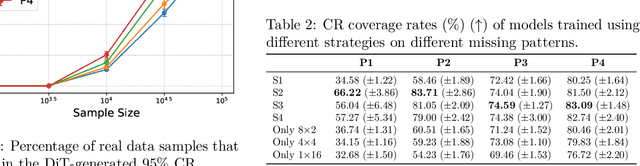
Imputation methods play a critical role in enhancing the quality of practical time-series data, which often suffer from pervasive missing values. Recently, diffusion-based generative imputation methods have demonstrated remarkable success compared to autoregressive and conventional statistical approaches. Despite their empirical success, the theoretical understanding of how well diffusion-based models capture complex spatial and temporal dependencies between the missing values and observed ones remains limited. Our work addresses this gap by investigating the statistical efficiency of conditional diffusion transformers for imputation and quantifying the uncertainty in missing values. Specifically, we derive statistical sample complexity bounds based on a novel approximation theory for conditional score functions using transformers, and, through this, construct tight confidence regions for missing values. Our findings also reveal that the efficiency and accuracy of imputation are significantly influenced by the missing patterns. Furthermore, we validate these theoretical insights through simulation and propose a mixed-masking training strategy to enhance the imputation performance.
Diffusion Factor Models: Generating High-Dimensional Returns with Factor Structure
Apr 09, 2025



Financial scenario simulation is essential for risk management and portfolio optimization, yet it remains challenging especially in high-dimensional and small data settings common in finance. We propose a diffusion factor model that integrates latent factor structure into generative diffusion processes, bridging econometrics with modern generative AI to address the challenges of the curse of dimensionality and data scarcity in financial simulation. By exploiting the low-dimensional factor structure inherent in asset returns, we decompose the score function--a key component in diffusion models--using time-varying orthogonal projections, and this decomposition is incorporated into the design of neural network architectures. We derive rigorous statistical guarantees, establishing nonasymptotic error bounds for both score estimation at O(d^{5/2} n^{-2/(k+5)}) and generated distribution at O(d^{5/4} n^{-1/2(k+5)}), primarily driven by the intrinsic factor dimension k rather than the number of assets d, surpassing the dimension-dependent limits in the classical nonparametric statistics literature and making the framework viable for markets with thousands of assets. Numerical studies confirm superior performance in latent subspace recovery under small data regimes. Empirical analysis demonstrates the economic significance of our framework in constructing mean-variance optimal portfolios and factor portfolios. This work presents the first theoretical integration of factor structure with diffusion models, offering a principled approach for high-dimensional financial simulation with limited data.
On Statistical Rates of Conditional Diffusion Transformers: Approximation, Estimation and Minimax Optimality
Nov 26, 2024



We investigate the approximation and estimation rates of conditional diffusion transformers (DiTs) with classifier-free guidance. We present a comprehensive analysis for ``in-context'' conditional DiTs under four common data assumptions. We show that both conditional DiTs and their latent variants lead to the minimax optimality of unconditional DiTs under identified settings. Specifically, we discretize the input domains into infinitesimal grids and then perform a term-by-term Taylor expansion on the conditional diffusion score function under H\"older smooth data assumption. This enables fine-grained use of transformers' universal approximation through a more detailed piecewise constant approximation and hence obtains tighter bounds. Additionally, we extend our analysis to the latent setting under the linear latent subspace assumption. We not only show that latent conditional DiTs achieve lower bounds than conditional DiTs both in approximation and estimation, but also show the minimax optimality of latent unconditional DiTs. Our findings establish statistical limits for conditional and unconditional DiTs, and offer practical guidance toward developing more efficient and accurate DiT models.
A Theoretical Perspective for Speculative Decoding Algorithm
Oct 30, 2024



Transformer-based autoregressive sampling has been the major bottleneck for slowing down large language model inferences. One effective way to accelerate inference is \emph{Speculative Decoding}, which employs a small model to sample a sequence of draft tokens and a large model to validate. Given its empirical effectiveness, the theoretical understanding of Speculative Decoding is falling behind. This paper tackles this gap by conceptualizing the decoding problem via markov chain abstraction and studying the key properties, \emph{output quality and inference acceleration}, from a theoretical perspective. Our analysis covers the theoretical limits of speculative decoding, batch algorithms, and output quality-inference acceleration tradeoffs. Our results reveal the fundamental connections between different components of LLMs via total variation distances and show how they jointly affect the efficiency of decoding algorithms.
Diffusion Transformer Captures Spatial-Temporal Dependencies: A Theory for Gaussian Process Data
Jul 23, 2024



Diffusion Transformer, the backbone of Sora for video generation, successfully scales the capacity of diffusion models, pioneering new avenues for high-fidelity sequential data generation. Unlike static data such as images, sequential data consists of consecutive data frames indexed by time, exhibiting rich spatial and temporal dependencies. These dependencies represent the underlying dynamic model and are critical to validate the generated data. In this paper, we make the first theoretical step towards bridging diffusion transformers for capturing spatial-temporal dependencies. Specifically, we establish score approximation and distribution estimation guarantees of diffusion transformers for learning Gaussian process data with covariance functions of various decay patterns. We highlight how the spatial-temporal dependencies are captured and affect learning efficiency. Our study proposes a novel transformer approximation theory, where the transformer acts to unroll an algorithm. We support our theoretical results by numerical experiments, providing strong evidence that spatial-temporal dependencies are captured within attention layers, aligning with our approximation theory.
Provable Statistical Rates for Consistency Diffusion Models
Jun 23, 2024Diffusion models have revolutionized various application domains, including computer vision and audio generation. Despite the state-of-the-art performance, diffusion models are known for their slow sample generation due to the extensive number of steps involved. In response, consistency models have been developed to merge multiple steps in the sampling process, thereby significantly boosting the speed of sample generation without compromising quality. This paper contributes towards the first statistical theory for consistency models, formulating their training as a distribution discrepancy minimization problem. Our analysis yields statistical estimation rates based on the Wasserstein distance for consistency models, matching those of vanilla diffusion models. Additionally, our results encompass the training of consistency models through both distillation and isolation methods, demystifying their underlying advantage.