 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Factor Models: Generating High-Dimensional Returns with Factor Structure
Apr 09, 2025Financial scenario simulation is essential for risk management and portfolio optimization, yet it remains challenging especially in high-dimensional and small data settings common in finance. We propose a diffusion factor model that integrates latent factor structure into generative diffusion processes, bridging econometrics with modern generative AI to address the challenges of the curse of dimensionality and data scarcity in financial simulation. By exploiting the low-dimensional factor structure inherent in asset returns, we decompose the score function--a key component in diffusion models--using time-varying orthogonal projections, and this decomposition is incorporated into the design of neural network architectures. We derive rigorous statistical guarantees, establishing nonasymptotic error bounds for both score estimation at O(d^{5/2} n^{-2/(k+5)}) and generated distribution at O(d^{5/4} n^{-1/2(k+5)}), primarily driven by the intrinsic factor dimension k rather than the number of assets d, surpassing the dimension-dependent limits in the classical nonparametric statistics literature and making the framework viable for markets with thousands of assets. Numerical studies confirm superior performance in latent subspace recovery under small data regimes. Empirical analysis demonstrates the economic significance of our framework in constructing mean-variance optimal portfolios and factor portfolios. This work presents the first theoretical integration of factor structure with diffusion models, offering a principled approach for high-dimensional financial simulation with limited data.
Debiasing Watermarks for Large Language Models via Maximal Coupling
Nov 17, 2024Watermarking language models is essential for distinguishing between human and machine-generated text and thus maintaining the integrity and trustworthiness of digital communication. We present a novel green/red list watermarking approach that partitions the token set into ``green'' and ``red'' lists, subtly increasing the generation probability for green tokens. To correct token distribution bias, our method employs maximal coupling, using a uniform coin flip to decide whether to apply bias correction, with the result embedded as a pseudorandom watermark signal. Theoretical analysis confirms this approach's unbiased nature and robust detection capabilities. Experimental results show that it outperforms prior techniques by preserving text quality while maintaining high detectability, and it demonstrates resilience to targeted modifications aimed at improving text quality. This research provides a promising watermarking solution for language models, balancing effective detection with minimal impact on text quality.
The Devil is in the Details: Boosting Guided Depth Super-Resolution via Rethinking Cross-Modal Alignment and Aggregation
Jan 16, 2024Guided depth super-resolution (GDSR) involves restoring missing depth details using the high-resolution RGB image of the same scene. Previous approaches have struggled with the heterogeneity and complementarity of the multi-modal inputs, and neglected the issues of modal misalignment, geometrical misalignment, and feature selection. In this study, we rethink some essential components in GDSR networks and propose a simple yet effective Dynamic Dual Alignment and Aggregation network (D2A2). D2A2 mainly consists of 1) a dynamic dual alignment module that adapts to alleviate the modal misalignment via a learnable domain alignment block and geometrically align cross-modal features by learning the offset; and 2) a mask-to-pixel feature aggregate module that uses the gated mechanism and pixel attention to filter out irrelevant texture noise from RGB features and combine the useful features with depth features. By combining the strengths of RGB and depth features while minimizing disturbance introduced by the RGB image, our method with simple reuse and redesign of basic components achieves state-of-the-art performance on multiple benchmark datasets. The code is available at https://github.com/JiangXinni/D2A2.
Lighting Every Darkness in Two Pairs: A Calibration-Free Pipeline for RAW Denoising
Aug 07, 2023Calibration-based methods have dominated RAW image denoising under extremely low-light environments. However, these methods suffer from several main deficiencies: 1) the calibration procedure is laborious and time-consuming, 2) denoisers for different cameras are difficult to transfer, and 3) the discrepancy between synthetic noise and real noise is enlarged by high digital gain. To overcome the above shortcomings, we propose a calibration-free pipeline for Lighting Every Drakness (LED), regardless of the digital gain or camera sensor. Instead of calibrating the noise parameters and training repeatedly, our method could adapt to a target camera only with few-shot paired data and fine-tuning. In addition, well-designed structural modification during both stages alleviates the domain gap between synthetic and real noise without any extra computational cost. With 2 pairs for each additional digital gain (in total 6 pairs) and 0.5% iterations, our method achieves superior performance over other calibration-based methods. Our code is available at https://github.com/Srameo/LED .
On Consistency of Signatures Using Lasso
May 24, 2023Signature transforms are iterated path integrals of continuous and discrete-time time series data, and their universal nonlinearity linearizes the problem of feature selection. This paper revisits the consistency issue of Lasso regression for the signature transform, both theoretically and numerically. Our study shows that, for processes and time series that are closer to Brownian motion or random walk with weaker inter-dimensional correlations, the Lasso regression is more consistent for their signatures defined by It\^o integrals; for mean reverting processes and time series, their signatures defined by Stratonovich integrals have more consistency in the Lasso regression. Our findings highlight the importance of choosing appropriate definitions of signatures and stochastic models in statistical inference and machine learning.
M2RNet: Multi-modal and Multi-scale Refined Network for RGB-D Salient Object Detection
Sep 16, 2021
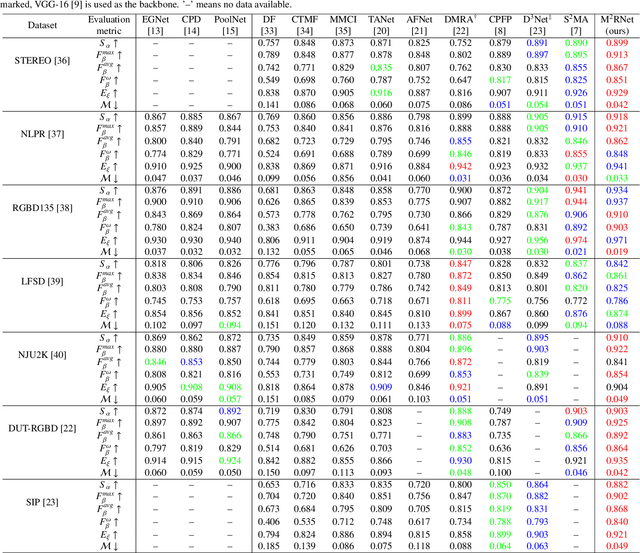
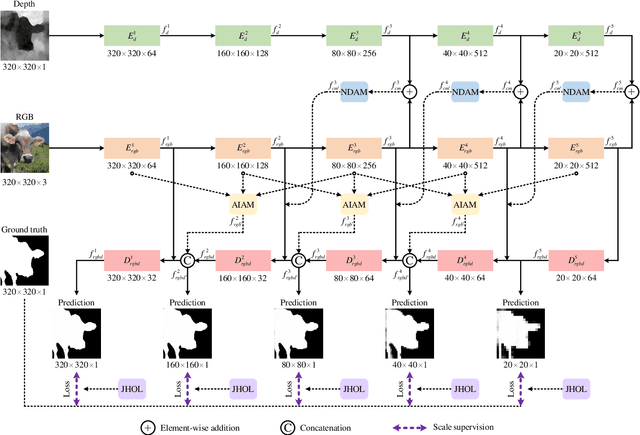

Salient object detection is a fundamental topic in computer vision. Previous methods based on RGB-D often suffer from the incompatibility of multi-modal feature fusion and the insufficiency of multi-scale feature aggregation. To tackle these two dilemmas, we propose a novel multi-modal and multi-scale refined network (M2RNet). Three essential components are presented in this network. The nested dual attention module (NDAM) explicitly exploits the combined features of RGB and depth flows. The adjacent interactive aggregation module (AIAM) gradually integrates the neighbor features of high, middle and low levels. The joint hybrid optimization loss (JHOL) makes the predictions have a prominent outline. Extensive experiments demonstrate that our method outperforms other state-of-the-art approaches.