 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural collapse in the orthoplex regime
Mar 21, 2026When training a neural network for classification, the feature vectors of the training set are known to collapse to the vertices of a regular simplex, provided the dimension $d$ of the feature space and the number $n$ of classes satisfies $n\leq d+1$. This phenomenon is known as neural collapse. For other applications like language models, one instead takes $n\gg d$. Here, the neural collapse phenomenon still occurs, but with different emergent geometric figures. We characterize these geometric figures in the orthoplex regime where $d+2\leq n\leq 2d$. The techniques in our analysis primarily involve Radon's theorem and convexity.
Statistical Early Stopping for Reasoning Models
Feb 15, 2026While LLMs have seen substantial improvement in reasoning capabilities, they also sometimes overthink, generating unnecessary reasoning steps, particularly under uncertainty, given ill-posed or ambiguous queries. We introduce statistically principled early stopping methods that monitor uncertainty signals during generation to mitigate this issue. Our first approach is parametric: it models inter-arrival times of uncertainty keywords as a renewal process and applies sequential testing for stopping. Our second approach is nonparametric and provides finite-sample guarantees on the probability of halting too early on well-posed queries. We conduct empirical evaluations on reasoning tasks across several domains and models. Our results indicate that uncertainty-aware early stopping can improve both efficiency and reliability in LLM reasoning, and we observe especially significant gains for math reasoning.
SCORE: Specificity, Context Utilization, Robustness, and Relevance for Reference-Free LLM Evaluation
Feb 10, 2026Large language models (LLMs) are increasingly used to support question answering and decision-making in high-stakes, domain-specific settings such as natural hazard response and infrastructure planning, where effective answers must convey fine-grained, decision-critical details. However, existing evaluation frameworks for retrieval-augmented generation (RAG) and open-ended question answering primarily rely on surface-level similarity, factual consistency, or semantic relevance, and often fail to assess whether responses provide the specific information required for domain-sensitive decisions. To address this gap, we propose a multi-dimensional, reference-free evaluation framework that assesses LLM outputs along four complementary dimensions: specificity, robustness to paraphrasing and semantic perturbations, answer relevance, and context utilization. We introduce a curated dataset of 1,412 domain-specific question-answer pairs spanning 40 professional roles and seven natural hazard types to support systematic evaluation. We further conduct human evaluation to assess inter-annotator agreement and alignment between model outputs and human judgments, which highlights the inherent subjectivity of open-ended, domain-specific evaluation. Our results show that no single metric sufficiently captures answer quality in isolation and demonstrate the need for structured, multi-metric evaluation frameworks when deploying LLMs in high-stakes applications.
Foundations of Top-$k$ Decoding For Language Models
May 25, 2025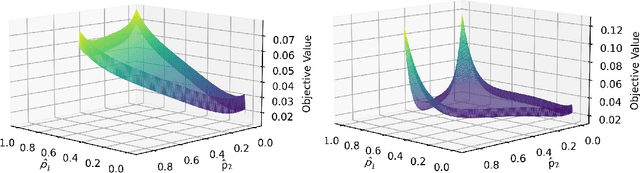

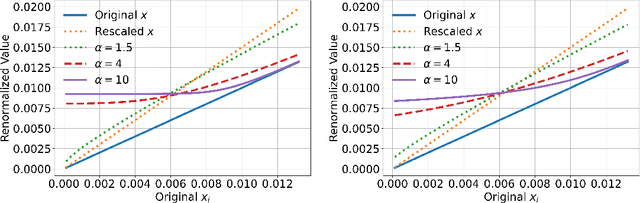

Top-$k$ decoding is a widely used method for sampling from LLMs: at each token, only the largest $k$ next-token-probabilities are kept, and the next token is sampled after re-normalizing them to sum to unity. Top-$k$ and other sampling methods are motivated by the intuition that true next-token distributions are sparse, and the noisy LLM probabilities need to be truncated. However, to our knowledge, a precise theoretical motivation for the use of top-$k$ decoding is missing. In this work, we develop a theoretical framework that both explains and generalizes top-$k$ decoding. We view decoding at a fixed token as the recovery of a sparse probability distribution. We consider \emph{Bregman decoders} obtained by minimizing a separable Bregman divergence (for both the \emph{primal} and \emph{dual} cases) with a sparsity-inducing $\ell_0$ regularization. Despite the combinatorial nature of the objective, we show how to optimize it efficiently for a large class of divergences. We show that the optimal decoding strategies are greedy, and further that the loss function is discretely convex in $k$, so that binary search provably and efficiently finds the optimal $k$. We show that top-$k$ decoding arises as a special case for the KL divergence, and identify new decoding strategies that have distinct behaviors (e.g., non-linearly up-weighting larger probabilities after re-normalization).
Comparative Evaluation of Prompting and Fine-Tuning for Applying Large Language Models to Grid-Structured Geospatial Data
May 21, 2025This paper presents a comparative study of large language models (LLMs) in interpreting grid-structured geospatial data. We evaluate the performance of a base model through structured prompting and contrast it with a fine-tuned variant trained on a dataset of user-assistant interactions. Our results highlight the strengths and limitations of zero-shot prompting and demonstrate the benefits of fine-tuning for structured geospatial and temporal reasoning.
GeoGrid-Bench: Can Foundation Models Understand Multimodal Gridded Geo-Spatial Data?
May 15, 2025We present GeoGrid-Bench, a benchmark designed to evaluate the ability of foundation models to understand geo-spatial data in the grid structure. Geo-spatial datasets pose distinct challenges due to their dense numerical values, strong spatial and temporal dependencies, and unique multimodal representations including tabular data, heatmaps, and geographic visualizations. To assess how foundation models can support scientific research in this domain, GeoGrid-Bench features large-scale, real-world data covering 16 climate variables across 150 locations and extended time frames. The benchmark includes approximately 3,200 question-answer pairs, systematically generated from 8 domain expert-curated templates to reflect practical tasks encountered by human scientists. These range from basic queries at a single location and time to complex spatiotemporal comparisons across regions and periods. Our evaluation reveals that vision-language models perform best overall, and we provide a fine-grained analysis of the strengths and limitations of different foundation models in different geo-spatial tasks. This benchmark offers clearer insights into how foundation models can be effectively applied to geo-spatial data analysis and used to support scientific research.
A RAG-Based Multi-Agent LLM System for Natural Hazard Resilience and Adaptation
Apr 24, 2025Large language models (LLMs) are a transformational capability at the frontier of artificial intelligence and machine learning that can support decision-makers in addressing pressing societal challenges such as extreme natural hazard events. As generalized models, LLMs often struggle to provide context-specific information, particularly in areas requiring specialized knowledge. In this work we propose a retrieval-augmented generation (RAG)-based multi-agent LLM system to support analysis and decision-making in the context of natural hazards and extreme weather events. As a proof of concept, we present WildfireGPT, a specialized system focused on wildfire hazards. The architecture employs a user-centered, multi-agent design to deliver tailored risk insights across diverse stakeholder groups. By integrating natural hazard and extreme weather projection data, observational datasets, and scientific literature through an RAG framework, the system ensures both the accuracy and contextual relevance of the information it provides. Evaluation across ten expert-led case studies demonstrates that WildfireGPT significantly outperforms existing LLM-based solutions for decision support.
Information Retrieval for Climate Impact
Apr 01, 2025The purpose of the MANILA24 Workshop on information retrieval for climate impact was to bring together researchers from academia, industry, governments, and NGOs to identify and discuss core research problems in information retrieval to assess climate change impacts. The workshop aimed to foster collaboration by bringing communities together that have so far not been very well connected -- information retrieval, natural language processing, systematic reviews, impact assessments, and climate science. The workshop brought together a diverse set of researchers and practitioners interested in contributing to the development of a technical research agenda for information retrieval to assess climate change impacts.
Debiasing Watermarks for Large Language Models via Maximal Coupling
Nov 17, 2024Watermarking language models is essential for distinguishing between human and machine-generated text and thus maintaining the integrity and trustworthiness of digital communication. We present a novel green/red list watermarking approach that partitions the token set into ``green'' and ``red'' lists, subtly increasing the generation probability for green tokens. To correct token distribution bias, our method employs maximal coupling, using a uniform coin flip to decide whether to apply bias correction, with the result embedded as a pseudorandom watermark signal. Theoretical analysis confirms this approach's unbiased nature and robust detection capabilities. Experimental results show that it outperforms prior techniques by preserving text quality while maintaining high detectability, and it demonstrates resilience to targeted modifications aimed at improving text quality. This research provides a promising watermarking solution for language models, balancing effective detection with minimal impact on text quality.
TrIM: Transformed Iterative Mondrian Forests for Gradient-based Dimension Reduction and High-Dimensional Regression
Jul 13, 2024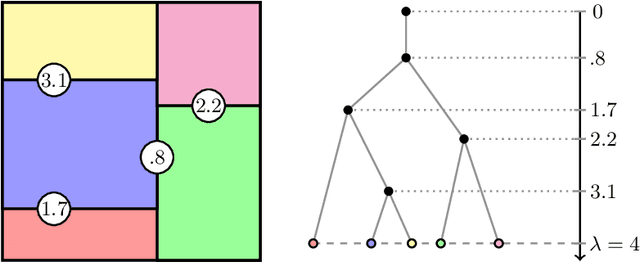
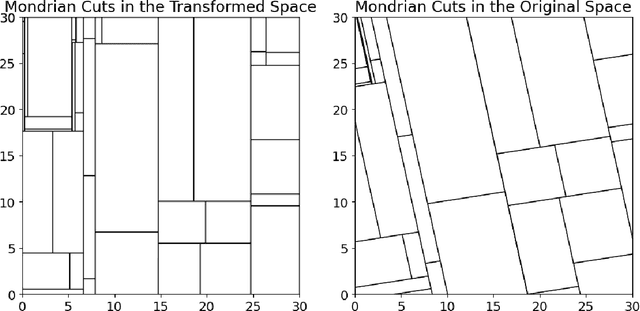
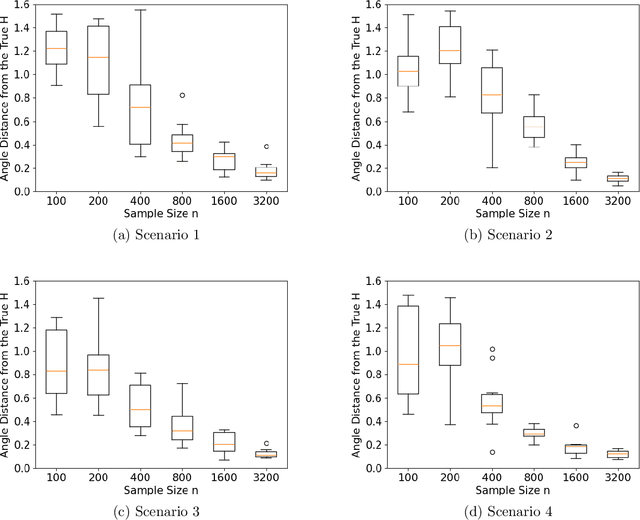
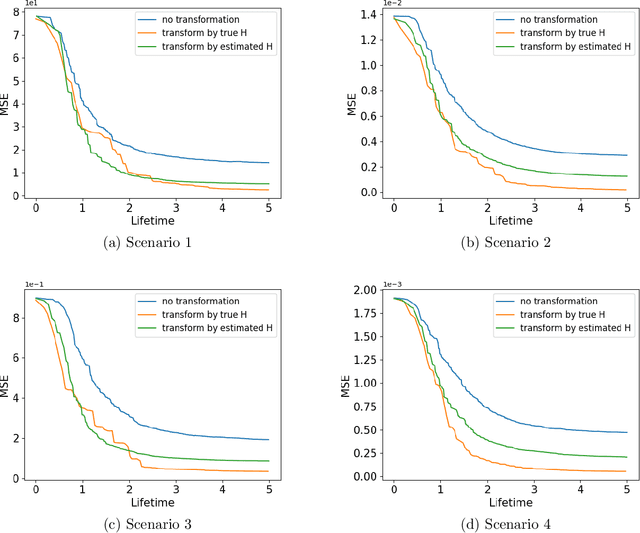
We propose a computationally efficient algorithm for gradient-based linear dimension reduction and high-dimensional regression. The algorithm initially computes a Mondrian forest and uses this estimator to identify a relevant feature subspace of the inputs from an estimate of the expected gradient outer product (EGOP) of the regression function. In addition, we introduce an iterative approach known as Transformed Iterative Mondrian (TrIM) forest to improve the Mondrian forest estimator by using the EGOP estimate to update the set of features and weights used by the Mondrian partitioning mechanism. We obtain consistency guarantees and convergence rates for the estimation of the EGOP matrix and the random forest estimator obtained from one iteration of the TrIM algorithm. Lastly, we demonstrate the effectiveness of our proposed algorithm for learning the relevant feature subspace across a variety of settings with both simulated and real data.