 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRACE: A Temporal Conditional Estimation for Multimodal Time Series Foundation Models
Jun 04, 2026Time series foundation models (TS-FMs) aim to learn generalizable temporal representations that can be adapted to a wide range of downstream tasks. In real-world multimodal settings, time series are frequently affected by temporal misalignment and partial modality missingness, where different modalities are observed at heterogeneous time scales or are partially absent. Existing approaches typically rely on naive imputation or masking strategies, which fail to account for cross-modal dependencies and often lead to misaligned or degraded representations. We propose TRACE, a conditional estimation paradigm for multimodal time series foundation model pipelines under missingness and irregular sampling, allowing incomplete target modalities to be systematically inferred from available auxiliary modalities. We evaluate TRACE on diverse multimodal benchmarks spanning healthcare and affective computing, including the MIMIC-IV clinical dataset and the CMU-MOSI and CMU-MOSEI benchmarks for multimodal sentiment analysis. Across a range of downstream prediction tasks and missing-modality settings, TRACE consistently outperforms prior multimodal fusion approaches, demonstrating improved robustness to severe modality missingness and more reliable cross-modal representations.
Learning to target with network interference
May 27, 2026This paper studies adaptive targeting under network interference in a bandit setting, where treatments applied to one individual may affect others through spillover effects. We consider a linear model in a sparse regime, where each individual's outcome can be affected by at most a few others. We first establish a regret lower bound showing that ignoring the network structure and reducing the problem to a standard linear bandit inevitably leads to inefficient learning, particularly in large populations. To understand how structural information can be leveraged, we analyze regimes with varying levels of knowledge of the interference structure: (1) full support knowledge, (2) knowledge of the column support sizes, and (3) no prior knowledge. For each regime, we establish regret lower bounds characterizing the fundamental limits of learning, and develop algorithms that achieve near-optimal regret. Together, our results provide a unified view of how knowledge of the interference structure governs the efficiency of online learning under interference, and offer practical adaptive targeting algorithms in each setting. Numerical experiments on synthetic and real-world data demonstrate the practical benefits of our algorithms.
DS-CIM: Digital Stochastic Computing-In-Memory Featuring Accurate OR-Accumulation via Sample Region Remapping for Edge AI Models
Jan 10, 2026Stochastic computing (SC) offers hardware simplicity but suffers from low throughput, while high-throughput Digital Computing-in-Memory (DCIM) is bottlenecked by costly adder logic for matrix-vector multiplication (MVM). To address this trade-off, this paper introduces a digital stochastic CIM (DS-CIM) architecture that achieves both high accuracy and efficiency. We implement signed multiply-accumulation (MAC) in a compact, unsigned OR-based circuit by modifying the data representation. Throughput is enhanced by replicating this low-cost circuit 64 times with only a 1x area increase. Our core strategy, a shared Pseudo Random Number Generator (PRNG) with 2D partitioning, enables single-cycle mutually exclusive activation to eliminate OR-gate collisions. We also resolve the 1s saturation issue via stochastic process analysis and data remapping, significantly improving accuracy and resilience to input sparsity. Our high-accuracy DS-CIM1 variant achieves 94.45% accuracy for INT8 ResNet18 on CIFAR-10 with a root-mean-squared error (RMSE) of just 0.74%. Meanwhile, our high-efficiency DS-CIM2 variant attains an energy efficiency of 3566.1 TOPS/W and an area efficiency of 363.7 TOPS/mm^2, while maintaining a low RMSE of 3.81%. The DS-CIM capability with larger models is further demonstrated through experiments with INT8 ResNet50 on ImageNet and the FP8 LLaMA-7B model.
GeoGrid-Bench: Can Foundation Models Understand Multimodal Gridded Geo-Spatial Data?
May 15, 2025We present GeoGrid-Bench, a benchmark designed to evaluate the ability of foundation models to understand geo-spatial data in the grid structure. Geo-spatial datasets pose distinct challenges due to their dense numerical values, strong spatial and temporal dependencies, and unique multimodal representations including tabular data, heatmaps, and geographic visualizations. To assess how foundation models can support scientific research in this domain, GeoGrid-Bench features large-scale, real-world data covering 16 climate variables across 150 locations and extended time frames. The benchmark includes approximately 3,200 question-answer pairs, systematically generated from 8 domain expert-curated templates to reflect practical tasks encountered by human scientists. These range from basic queries at a single location and time to complex spatiotemporal comparisons across regions and periods. Our evaluation reveals that vision-language models perform best overall, and we provide a fine-grained analysis of the strengths and limitations of different foundation models in different geo-spatial tasks. This benchmark offers clearer insights into how foundation models can be effectively applied to geo-spatial data analysis and used to support scientific research.
XR-VIO: High-precision Visual Inertial Odometry with Fast Initialization for XR Applications
Feb 03, 2025This paper presents a novel approach to Visual Inertial Odometry (VIO), focusing on the initialization and feature matching modules. Existing methods for initialization often suffer from either poor stability in visual Structure from Motion (SfM) or fragility in solving a huge number of parameters simultaneously. To address these challenges, we propose a new pipeline for visual inertial initialization that robustly handles various complex scenarios. By tightly coupling gyroscope measurements, we enhance the robustness and accuracy of visual SfM. Our method demonstrates stable performance even with only four image frames, yielding competitive results. In terms of feature matching, we introduce a hybrid method that combines optical flow and descriptor-based matching. By leveraging the robustness of continuous optical flow tracking and the accuracy of descriptor matching, our approach achieves efficient, accurate, and robust tracking results. Through evaluation on multiple benchmarks, our method demonstrates state-of-the-art performance in terms of accuracy and success rate. Additionally, a video demonstration on mobile devices showcases the practical applicability of our approach in the field of Augmented Reality/Virtual Reality (AR/VR).
Car-GS: Addressing Reflective and Transparent Surface Challenges in 3D Car Reconstruction
Jan 19, 2025



3D car modeling is crucial for applications in autonomous driving systems, virtual and augmented reality, and gaming. However, due to the distinctive properties of cars, such as highly reflective and transparent surface materials, existing methods often struggle to achieve accurate 3D car reconstruction.To address these limitations, we propose Car-GS, a novel approach designed to mitigate the effects of specular highlights and the coupling of RGB and geometry in 3D geometric and shading reconstruction (3DGS). Our method incorporates three key innovations: First, we introduce view-dependent Gaussian primitives to effectively model surface reflections. Second, we identify the limitations of using a shared opacity parameter for both image rendering and geometric attributes when modeling transparent objects. To overcome this, we assign a learnable geometry-specific opacity to each 2D Gaussian primitive, dedicated solely to rendering depth and normals. Third, we observe that reconstruction errors are most prominent when the camera view is nearly orthogonal to glass surfaces. To address this issue, we develop a quality-aware supervision module that adaptively leverages normal priors from a pre-trained large-scale normal model.Experimental results demonstrate that Car-GS achieves precise reconstruction of car surfaces and significantly outperforms prior methods. The project page is available at https://lcc815.github.io/Car-GS.
StarGen: A Spatiotemporal Autoregression Framework with Video Diffusion Model for Scalable and Controllable Scene Generation
Jan 10, 2025
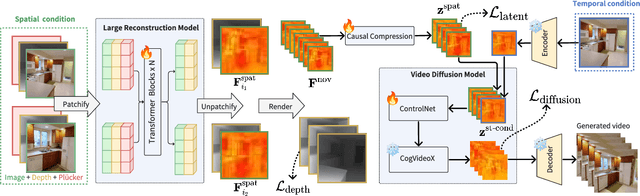


Recent advances in large reconstruction and generative models have significantly improved scene reconstruction and novel view generation. However, due to compute limitations, each inference with these large models is confined to a small area, making long-range consistent scene generation challenging. To address this, we propose StarGen, a novel framework that employs a pre-trained video diffusion model in an autoregressive manner for long-range scene generation. The generation of each video clip is conditioned on the 3D warping of spatially adjacent images and the temporally overlapping image from previously generated clips, improving spatiotemporal consistency in long-range scene generation with precise pose control. The spatiotemporal condition is compatible with various input conditions, facilitating diverse tasks, including sparse view interpolation, perpetual view generation, and layout-conditioned city generation. Quantitative and qualitative evaluations demonstrate StarGen's superior scalability, fidelity, and pose accuracy compared to state-of-the-art methods.
AHMSA-Net: Adaptive Hierarchical Multi-Scale Attention Network for Micro-Expression Recognition
Jan 05, 2025



Micro-expression recognition (MER) presents a significant challenge due to the transient and subtle nature of the motion changes involved. In recent years, deep learning methods based on attention mechanisms have made some breakthroughs in MER. However, these methods still suffer from the limitations of insufficient feature capture and poor dynamic adaptation when coping with the instantaneous subtle movement changes of micro-expressions. Therefore, in this paper, we design an Adaptive Hierarchical Multi-Scale Attention Network (AHMSA-Net) for MER. Specifically, we first utilize the onset and apex frames of the micro-expression sequence to extract three-dimensional (3D) optical flow maps, including horizontal optical flow, vertical optical flow, and optical flow strain. Subsequently, the optical flow feature maps are inputted into AHMSA-Net, which consists of two parts: an adaptive hierarchical framework and a multi-scale attention mechanism. Based on the adaptive downsampling hierarchical attention framework, AHMSA-Net captures the subtle changes of micro-expressions from different granularities (fine and coarse) by dynamically adjusting the size of the optical flow feature map at each layer. Based on the multi-scale attention mechanism, AHMSA-Net learns micro-expression action information by fusing features from different scales (channel and spatial). These two modules work together to comprehensively improve the accuracy of MER. Additionally, rigorous experiments demonstrate that the proposed method achieves competitive results on major micro-expression databases, with AHMSA-Net achieving recognition accuracy of up to 78.21% on composite databases (SMIC, SAMM, CASMEII) and 77.08% on the CASME^{}3 database.
Partial Knowledge Distillation for Alleviating the Inherent Inter-Class Discrepancy in Federated Learning
Nov 23, 2024



Substantial efforts have been devoted to alleviating the impact of the long-tailed class distribution in federated learning. In this work, we observe an interesting phenomenon that weak classes consistently exist even for class-balanced learning. These weak classes, different from the minority classes in the previous works, are inherent to data and remain fairly consistent for various network structures and learning paradigms. The inherent inter-class accuracy discrepancy can reach over 36.9% for federated learning on the FashionMNIST and CIFAR-10 datasets, even when the class distribution is balanced both globally and locally. In this study, we empirically analyze the potential reason for this phenomenon. Furthermore, a class-specific partial knowledge distillation method is proposed to improve the model's classification accuracy for weak classes. In this approach, knowledge transfer is initiated upon the occurrence of specific misclassifications within certain weak classes. Experimental results show that the accuracy of weak classes can be improved by 10.7%, reducing the inherent interclass discrepancy effectively.
XRDSLAM: A Flexible and Modular Framework for Deep Learning based SLAM
Oct 31, 2024



In this paper, we propose a flexible SLAM framework, XRDSLAM. It adopts a modular code design and a multi-process running mechanism, providing highly reusable foundational modules such as unified dataset management, 3d visualization, algorithm configuration, and metrics evaluation. It can help developers quickly build a complete SLAM system, flexibly combine different algorithm modules, and conduct standardized benchmarking for accuracy and efficiency comparison. Within this framework, we integrate several state-of-the-art SLAM algorithms with different types, including NeRF and 3DGS based SLAM, and even odometry or reconstruction algorithms, which demonstrates the flexibility and extensibility. We also conduct a comprehensive comparison and evaluation of these integrated algorithms, analyzing the characteristics of each. Finally, we contribute all the code, configuration and data to the open-source community, which aims to promote the widespread research and development of SLAM technology within the open-source ecosystem.