 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCar-GS: Addressing Reflective and Transparent Surface Challenges in 3D Car Reconstruction
Jan 19, 2025



3D car modeling is crucial for applications in autonomous driving systems, virtual and augmented reality, and gaming. However, due to the distinctive properties of cars, such as highly reflective and transparent surface materials, existing methods often struggle to achieve accurate 3D car reconstruction.To address these limitations, we propose Car-GS, a novel approach designed to mitigate the effects of specular highlights and the coupling of RGB and geometry in 3D geometric and shading reconstruction (3DGS). Our method incorporates three key innovations: First, we introduce view-dependent Gaussian primitives to effectively model surface reflections. Second, we identify the limitations of using a shared opacity parameter for both image rendering and geometric attributes when modeling transparent objects. To overcome this, we assign a learnable geometry-specific opacity to each 2D Gaussian primitive, dedicated solely to rendering depth and normals. Third, we observe that reconstruction errors are most prominent when the camera view is nearly orthogonal to glass surfaces. To address this issue, we develop a quality-aware supervision module that adaptively leverages normal priors from a pre-trained large-scale normal model.Experimental results demonstrate that Car-GS achieves precise reconstruction of car surfaces and significantly outperforms prior methods. The project page is available at https://lcc815.github.io/Car-GS.
Hints of Prompt: Enhancing Visual Representation for Multimodal LLMs in Autonomous Driving
Nov 20, 2024



In light of the dynamic nature of autonomous driving environments and stringent safety requirements, general MLLMs combined with CLIP alone often struggle to represent driving-specific scenarios accurately, particularly in complex interactions and long-tail cases. To address this, we propose the Hints of Prompt (HoP) framework, which introduces three key enhancements: Affinity hint to emphasize instance-level structure by strengthening token-wise connections, Semantic hint to incorporate high-level information relevant to driving-specific cases, such as complex interactions among vehicles and traffic signs, and Question hint to align visual features with the query context, focusing on question-relevant regions. These hints are fused through a Hint Fusion module, enriching visual representations and enhancing multimodal reasoning for autonomous driving VQA tasks. Extensive experiments confirm the effectiveness of the HoP framework, showing it significantly outperforms previous state-of-the-art methods across all key metrics.
PriorMapNet: Enhancing Online Vectorized HD Map Construction with Priors
Aug 16, 2024



Online vectorized High-Definition (HD) map construction is crucial for subsequent prediction and planning tasks in autonomous driving. Following MapTR paradigm, recent works have made noteworthy achievements. However, reference points are randomly initialized in mainstream methods, leading to unstable matching between predictions and ground truth. To address this issue, we introduce PriorMapNet to enhance online vectorized HD map construction with priors. We propose the PPS-Decoder, which provides reference points with position and structure priors. Fitted from the map elements in the dataset, prior reference points lower the learning difficulty and achieve stable matching. Furthermore, we propose the PF-Encoder to enhance the image-to-BEV transformation with BEV feature priors. Besides, we propose the DMD cross-attention, which decouples cross-attention along multi-scale and multi-sample respectively to achieve efficiency. Our proposed PriorMapNet achieves state-of-the-art performance in the online vectorized HD map construction task on nuScenes and Argoverse2 datasets. The code will be released publicly soon.
Mitigating Covariate Shift in Misspecified Regression with Applications to Reinforcement Learning
Jan 22, 2024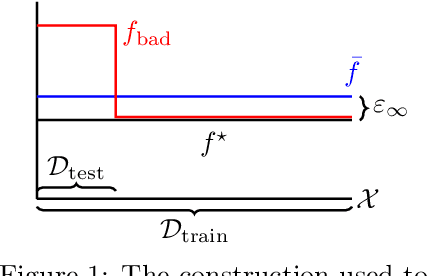
A pervasive phenomenon in machine learning applications is distribution shift, where training and deployment conditions for a machine learning model differ. As distribution shift typically results in a degradation in performance, much attention has been devoted to algorithmic interventions that mitigate these detrimental effects. In this paper, we study the effect of distribution shift in the presence of model misspecification, specifically focusing on $L_{\infty}$-misspecified regression and adversarial covariate shift, where the regression target remains fixed while the covariate distribution changes arbitrarily. We show that empirical risk minimization, or standard least squares regression, can result in undesirable misspecification amplification where the error due to misspecification is amplified by the density ratio between the training and testing distributions. As our main result, we develop a new algorithm -- inspired by robust optimization techniques -- that avoids this undesirable behavior, resulting in no misspecification amplification while still obtaining optimal statistical rates. As applications, we use this regression procedure to obtain new guarantees in offline and online reinforcement learning with misspecification and establish new separations between previously studied structural conditions and notions of coverage.
DeepEMplanner: An End-to-End EM Motion Planner with Iterative Interactions
Nov 29, 2023

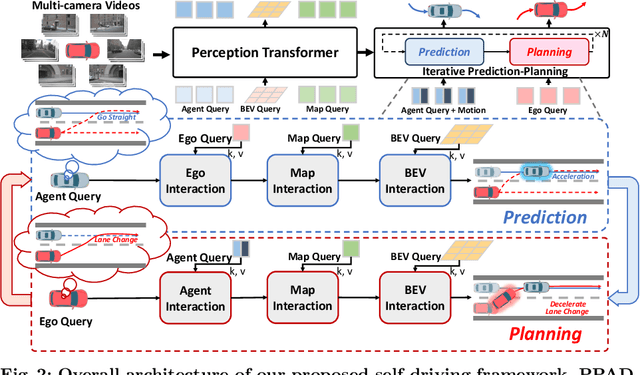

Motion planning is a computational problem that finds a sequence of valid trajectories, often based on surrounding agents' forecasting, environmental understanding, and historical and future contexts. It can also be viewed as a game in which agents continuously plan their next move according to other agents' intentions and the encountering environment, further achieving their ultimate goals through incremental actions. To model the dynamic planning and interaction process, we propose a novel framework, DeepEMplanner, which takes the stepwise interaction into account for fine-grained behavior learning. The ego vehicle maximizes each step motion to reach its eventual driving outcome based on the stepwise expectation from agents and its upcoming road conditions. On the other hand, the agents also follow the same philosophy to maximize their stepwise behavior under the encountering environment and the expectations from ego and other agents. Our DeepEMplanner models the interactions among ego, agents, and the dynamic environment in an autoregressive manner by interleaving the Expectation and Maximization processes. Further, we design ego-to-agents, ego-to-map, and ego-to-BEV interaction mechanisms with hierarchical dynamic key objects attention to better model the interactions. Experiments on the nuScenes benchmark show that our approach achieves state-of-the-art results.
SVQNet: Sparse Voxel-Adjacent Query Network for 4D Spatio-Temporal LiDAR Semantic Segmentation
Aug 25, 2023



LiDAR-based semantic perception tasks are critical yet challenging for autonomous driving. Due to the motion of objects and static/dynamic occlusion, temporal information plays an essential role in reinforcing perception by enhancing and completing single-frame knowledge. Previous approaches either directly stack historical frames to the current frame or build a 4D spatio-temporal neighborhood using KNN, which duplicates computation and hinders realtime performance. Based on our observation that stacking all the historical points would damage performance due to a large amount of redundant and misleading information, we propose the Sparse Voxel-Adjacent Query Network (SVQNet) for 4D LiDAR semantic segmentation. To take full advantage of the historical frames high-efficiently, we shunt the historical points into two groups with reference to the current points. One is the Voxel-Adjacent Neighborhood carrying local enhancing knowledge. The other is the Historical Context completing the global knowledge. Then we propose new modules to select and extract the instructive features from the two groups. Our SVQNet achieves state-of-the-art performance in LiDAR semantic segmentation of the SemanticKITTI benchmark and the nuScenes dataset.
From One to Many: Dynamic Cross Attention Networks for LiDAR and Camera Fusion
Sep 25, 2022
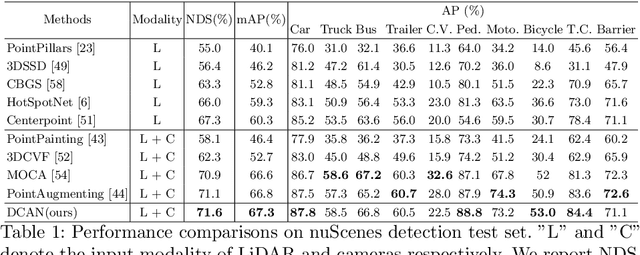
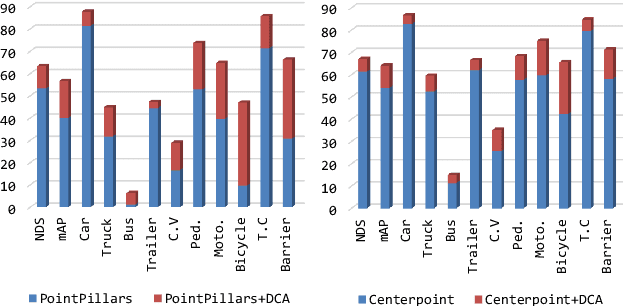
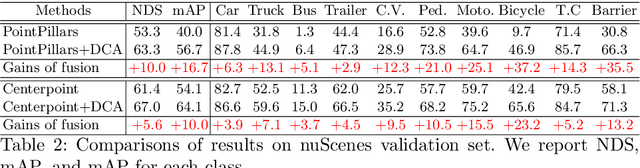
LiDAR and cameras are two complementary sensors for 3D perception in autonomous driving. LiDAR point clouds have accurate spatial and geometry information, while RGB images provide textural and color data for context reasoning. To exploit LiDAR and cameras jointly, existing fusion methods tend to align each 3D point to only one projected image pixel based on calibration, namely one-to-one mapping. However, the performance of these approaches highly relies on the calibration quality, which is sensitive to the temporal and spatial synchronization of sensors. Therefore, we propose a Dynamic Cross Attention (DCA) module with a novel one-to-many cross-modality mapping that learns multiple offsets from the initial projection towards the neighborhood and thus develops tolerance to calibration error. Moreover, a \textit{dynamic query enhancement} is proposed to perceive the model-independent calibration, which further strengthens DCA's tolerance to the initial misalignment. The whole fusion architecture named Dynamic Cross Attention Network (DCAN) exploits multi-level image features and adapts to multiple representations of point clouds, which allows DCA to serve as a plug-in fusion module. Extensive experiments on nuScenes and KITTI prove DCA's effectiveness. The proposed DCAN outperforms state-of-the-art methods on the nuScenes detection challenge.
DCMS: Motion Forecasting with Dual Consistency and Multi-Pseudo-Target Supervision
Apr 12, 2022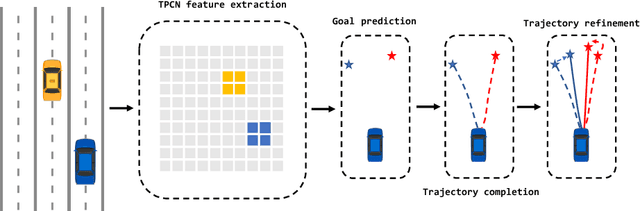
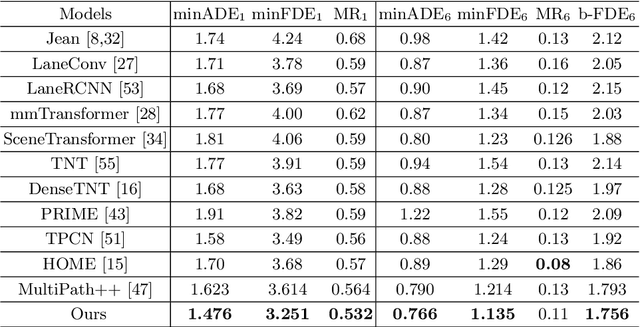
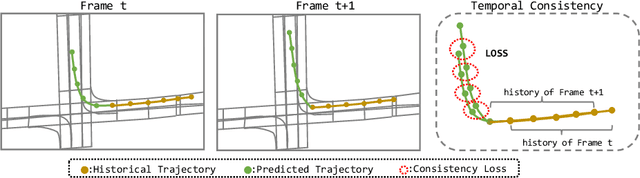
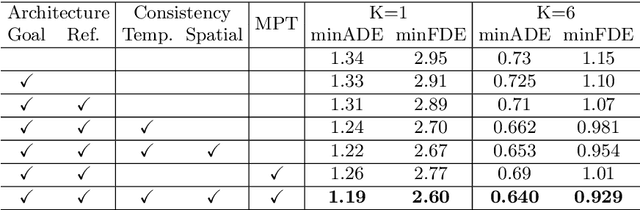
We present a novel framework for motion forecasting with Dual Consistency Constraints and Multi-Pseudo-Target supervision. The motion forecasting task predicts future trajectories of vehicles by incorporating spatial and temporal information from the past. A key design of DCMS is the proposed Dual Consistency Constraints that regularize the predicted trajectories under spatial and temporal perturbation during the training stage. In addition, we design a novel self-ensembling scheme to obtain accurate pseudo targets to model the multi-modality in motion forecasting through supervision with multiple targets explicitly, namely Multi-Pseudo-Target supervision. Our experimental results on the Argoverse motion forecasting benchmark show that DCMS significantly outperforms the state-of-the-art methods, achieving 1st place on the leaderboard. We also demonstrate that our proposed strategies can be incorporated into other motion forecasting approaches as general training schemes.
Sparse Cross-scale Attention Network for Efficient LiDAR Panoptic Segmentation
Jan 16, 2022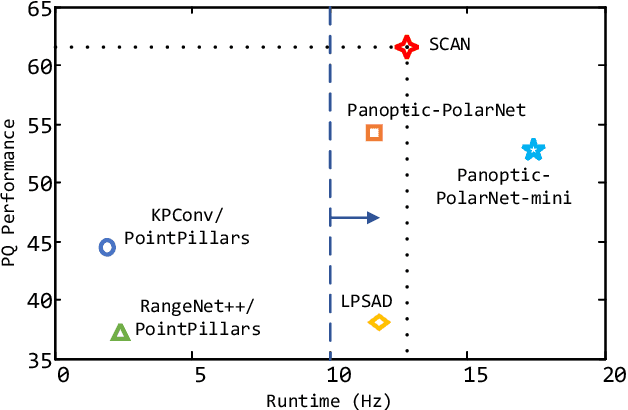


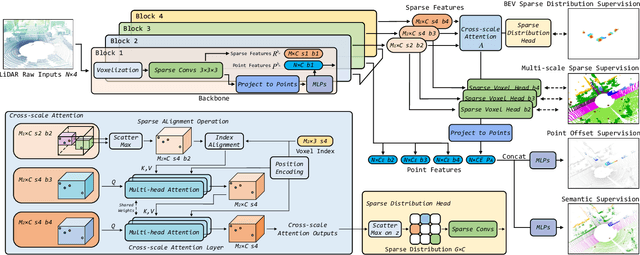
Two major challenges of 3D LiDAR Panoptic Segmentation (PS) are that point clouds of an object are surface-aggregated and thus hard to model the long-range dependency especially for large instances, and that objects are too close to separate each other. Recent literature addresses these problems by time-consuming grouping processes such as dual-clustering, mean-shift offsets, etc., or by bird-eye-view (BEV) dense centroid representation that downplays geometry. However, the long-range geometry relationship has not been sufficiently modeled by local feature learning from the above methods. To this end, we present SCAN, a novel sparse cross-scale attention network to first align multi-scale sparse features with global voxel-encoded attention to capture the long-range relationship of instance context, which can boost the regression accuracy of the over-segmented large objects. For the surface-aggregated points, SCAN adopts a novel sparse class-agnostic representation of instance centroids, which can not only maintain the sparsity of aligned features to solve the under-segmentation on small objects, but also reduce the computation amount of the network through sparse convolution. Our method outperforms previous methods by a large margin in the SemanticKITTI dataset for the challenging 3D PS task, achieving 1st place with a real-time inference speed.
DRINet++: Efficient Voxel-as-point Point Cloud Segmentation
Nov 16, 2021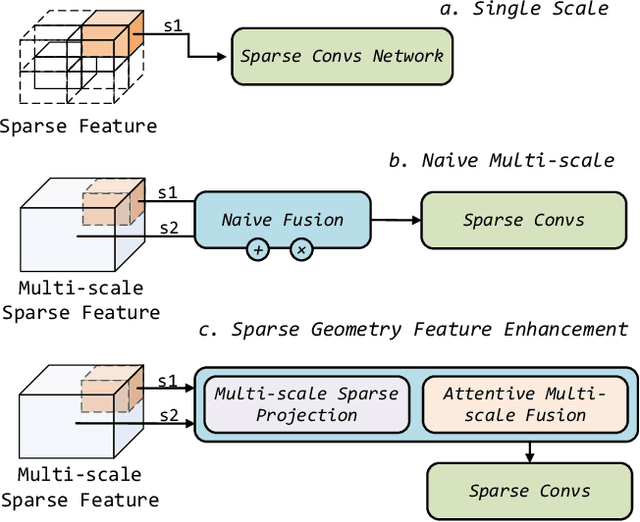
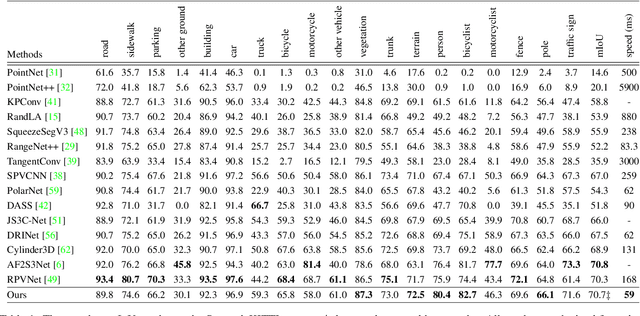
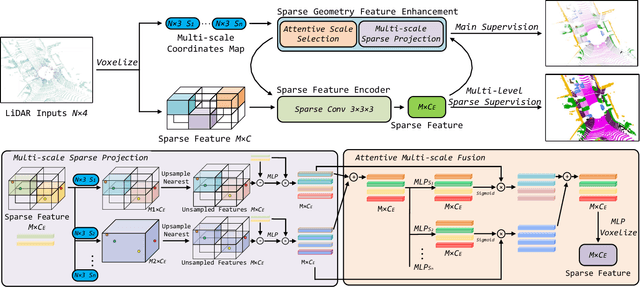
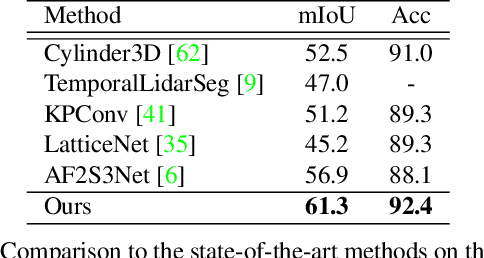
Recently, many approaches have been proposed through single or multiple representations to improve the performance of point cloud semantic segmentation. However, these works do not maintain a good balance among performance, efficiency, and memory consumption. To address these issues, we propose DRINet++ that extends DRINet by enhancing the sparsity and geometric properties of a point cloud with a voxel-as-point principle. To improve efficiency and performance, DRINet++ mainly consists of two modules: Sparse Feature Encoder and Sparse Geometry Feature Enhancement. The Sparse Feature Encoder extracts the local context information for each point, and the Sparse Geometry Feature Enhancement enhances the geometric properties of a sparse point cloud via multi-scale sparse projection and attentive multi-scale fusion. In addition, we propose deep sparse supervision in the training phase to help convergence and alleviate the memory consumption problem. Our DRINet++ achieves state-of-the-art outdoor point cloud segmentation on both SemanticKITTI and Nuscenes datasets while running significantly faster and consuming less memory.