 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNetRoller: Interfacing General and Specialized Models for End-to-End Autonomous Driving
Jun 17, 2025Integrating General Models (GMs) such as Large Language Models (LLMs), with Specialized Models (SMs) in autonomous driving tasks presents a promising approach to mitigating challenges in data diversity and model capacity of existing specialized driving models. However, this integration leads to problems of asynchronous systems, which arise from the distinct characteristics inherent in GMs and SMs. To tackle this challenge, we propose NetRoller, an adapter that incorporates a set of novel mechanisms to facilitate the seamless integration of GMs and specialized driving models. Specifically, our mechanisms for interfacing the asynchronous GMs and SMs are organized into three key stages. NetRoller first harvests semantically rich and computationally efficient representations from the reasoning processes of LLMs using an early stopping mechanism, which preserves critical insights on driving context while maintaining low overhead. It then applies learnable query embeddings, nonsensical embeddings, and positional layer embeddings to facilitate robust and efficient cross-modality translation. At last, it employs computationally efficient Query Shift and Feature Shift mechanisms to enhance the performance of SMs through few-epoch fine-tuning. Based on the mechanisms formalized in these three stages, NetRoller enables specialized driving models to operate at their native frequencies while maintaining situational awareness of the GM. Experiments conducted on the nuScenes dataset demonstrate that integrating GM through NetRoller significantly improves human similarity and safety in planning tasks, and it also achieves noticeable precision improvements in detection and mapping tasks for end-to-end autonomous driving. The code and models are available at https://github.com/Rex-sys-hk/NetRoller .
End-to-End HOI Reconstruction Transformer with Graph-based Encoding
Mar 08, 2025



With the diversification of human-object interaction (HOI) applications and the success of capturing human meshes, HOI reconstruction has gained widespread attention. Existing mainstream HOI reconstruction methods often rely on explicitly modeling interactions between humans and objects. However, such a way leads to a natural conflict between 3D mesh reconstruction, which emphasizes global structure, and fine-grained contact reconstruction, which focuses on local details. To address the limitations of explicit modeling, we propose the End-to-End HOI Reconstruction Transformer with Graph-based Encoding (HOI-TG). It implicitly learns the interaction between humans and objects by leveraging self-attention mechanisms. Within the transformer architecture, we devise graph residual blocks to aggregate the topology among vertices of different spatial structures. This dual focus effectively balances global and local representations. Without bells and whistles, HOI-TG achieves state-of-the-art performance on BEHAVE and InterCap datasets. Particularly on the challenging InterCap dataset, our method improves the reconstruction results for human and object meshes by 8.9% and 8.6%, respectively.
Hints of Prompt: Enhancing Visual Representation for Multimodal LLMs in Autonomous Driving
Nov 20, 2024



In light of the dynamic nature of autonomous driving environments and stringent safety requirements, general MLLMs combined with CLIP alone often struggle to represent driving-specific scenarios accurately, particularly in complex interactions and long-tail cases. To address this, we propose the Hints of Prompt (HoP) framework, which introduces three key enhancements: Affinity hint to emphasize instance-level structure by strengthening token-wise connections, Semantic hint to incorporate high-level information relevant to driving-specific cases, such as complex interactions among vehicles and traffic signs, and Question hint to align visual features with the query context, focusing on question-relevant regions. These hints are fused through a Hint Fusion module, enriching visual representations and enhancing multimodal reasoning for autonomous driving VQA tasks. Extensive experiments confirm the effectiveness of the HoP framework, showing it significantly outperforms previous state-of-the-art methods across all key metrics.
Learning High-resolution Vector Representation from Multi-Camera Images for 3D Object Detection
Jul 22, 2024The Bird's-Eye-View (BEV) representation is a critical factor that directly impacts the 3D object detection performance, but the traditional BEV grid representation induces quadratic computational cost as the spatial resolution grows. To address this limitation, we present a new camera-based 3D object detector with high-resolution vector representation: VectorFormer. The presented high-resolution vector representation is combined with the lower-resolution BEV representation to efficiently exploit 3D geometry from multi-camera images at a high resolution through our two novel modules: vector scattering and gathering. To this end, the learned vector representation with richer scene contexts can serve as the decoding query for final predictions. We conduct extensive experiments on the nuScenes dataset and demonstrate state-of-the-art performance in NDS and inference time. Furthermore, we investigate query-BEV-based methods incorporated with our proposed vector representation and observe a consistent performance improvement.
Cross-Cluster Shifting for Efficient and Effective 3D Object Detection in Autonomous Driving
Mar 10, 2024



We present a new 3D point-based detector model, named Shift-SSD, for precise 3D object detection in autonomous driving. Traditional point-based 3D object detectors often employ architectures that rely on a progressive downsampling of points. While this method effectively reduces computational demands and increases receptive fields, it will compromise the preservation of crucial non-local information for accurate 3D object detection, especially in the complex driving scenarios. To address this, we introduce an intriguing Cross-Cluster Shifting operation to unleash the representation capacity of the point-based detector by efficiently modeling longer-range inter-dependency while including only a negligible overhead. Concretely, the Cross-Cluster Shifting operation enhances the conventional design by shifting partial channels from neighboring clusters, which enables richer interaction with non-local regions and thus enlarges the receptive field of clusters. We conduct extensive experiments on the KITTI, Waymo, and nuScenes datasets, and the results demonstrate the state-of-the-art performance of Shift-SSD in both detection accuracy and runtime efficiency.
DeepEMplanner: An End-to-End EM Motion Planner with Iterative Interactions
Nov 29, 2023

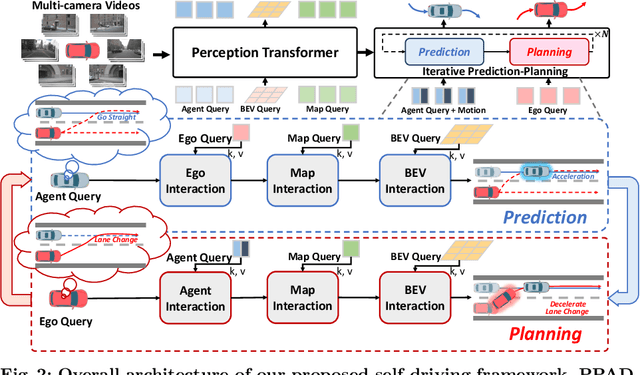

Motion planning is a computational problem that finds a sequence of valid trajectories, often based on surrounding agents' forecasting, environmental understanding, and historical and future contexts. It can also be viewed as a game in which agents continuously plan their next move according to other agents' intentions and the encountering environment, further achieving their ultimate goals through incremental actions. To model the dynamic planning and interaction process, we propose a novel framework, DeepEMplanner, which takes the stepwise interaction into account for fine-grained behavior learning. The ego vehicle maximizes each step motion to reach its eventual driving outcome based on the stepwise expectation from agents and its upcoming road conditions. On the other hand, the agents also follow the same philosophy to maximize their stepwise behavior under the encountering environment and the expectations from ego and other agents. Our DeepEMplanner models the interactions among ego, agents, and the dynamic environment in an autoregressive manner by interleaving the Expectation and Maximization processes. Further, we design ego-to-agents, ego-to-map, and ego-to-BEV interaction mechanisms with hierarchical dynamic key objects attention to better model the interactions. Experiments on the nuScenes benchmark show that our approach achieves state-of-the-art results.
DCMS: Motion Forecasting with Dual Consistency and Multi-Pseudo-Target Supervision
Apr 12, 2022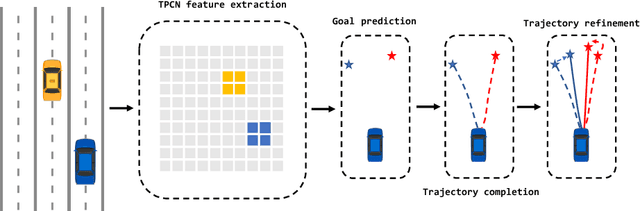
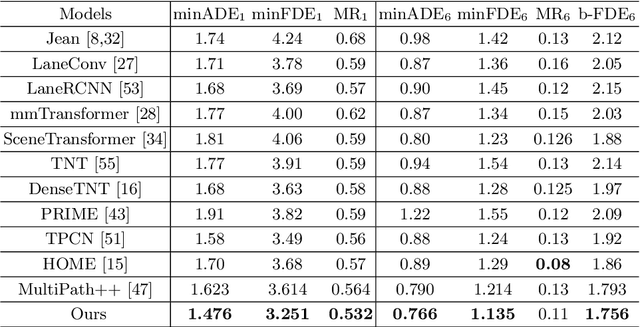
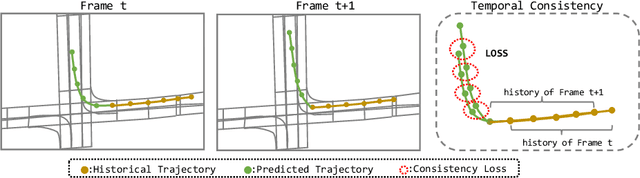
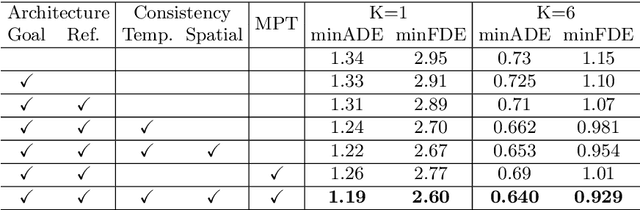
We present a novel framework for motion forecasting with Dual Consistency Constraints and Multi-Pseudo-Target supervision. The motion forecasting task predicts future trajectories of vehicles by incorporating spatial and temporal information from the past. A key design of DCMS is the proposed Dual Consistency Constraints that regularize the predicted trajectories under spatial and temporal perturbation during the training stage. In addition, we design a novel self-ensembling scheme to obtain accurate pseudo targets to model the multi-modality in motion forecasting through supervision with multiple targets explicitly, namely Multi-Pseudo-Target supervision. Our experimental results on the Argoverse motion forecasting benchmark show that DCMS significantly outperforms the state-of-the-art methods, achieving 1st place on the leaderboard. We also demonstrate that our proposed strategies can be incorporated into other motion forecasting approaches as general training schemes.
Sparse Cross-scale Attention Network for Efficient LiDAR Panoptic Segmentation
Jan 16, 2022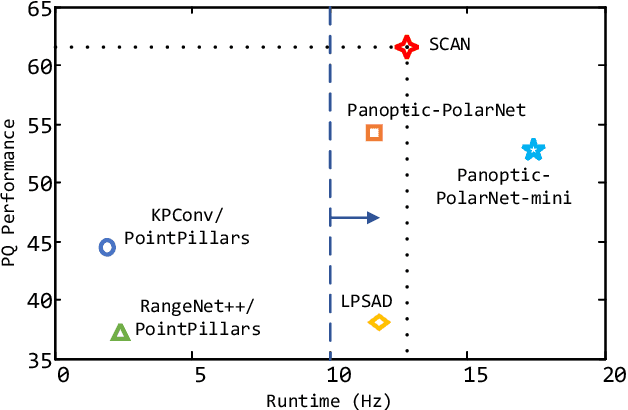


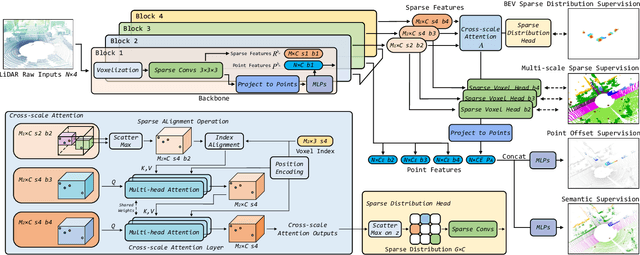
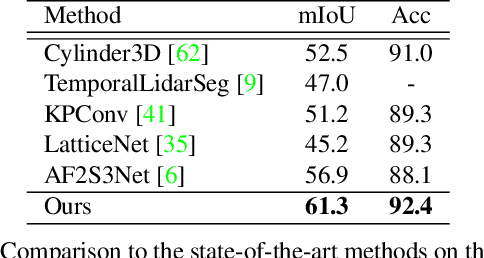
Two major challenges of 3D LiDAR Panoptic Segmentation (PS) are that point clouds of an object are surface-aggregated and thus hard to model the long-range dependency especially for large instances, and that objects are too close to separate each other. Recent literature addresses these problems by time-consuming grouping processes such as dual-clustering, mean-shift offsets, etc., or by bird-eye-view (BEV) dense centroid representation that downplays geometry. However, the long-range geometry relationship has not been sufficiently modeled by local feature learning from the above methods. To this end, we present SCAN, a novel sparse cross-scale attention network to first align multi-scale sparse features with global voxel-encoded attention to capture the long-range relationship of instance context, which can boost the regression accuracy of the over-segmented large objects. For the surface-aggregated points, SCAN adopts a novel sparse class-agnostic representation of instance centroids, which can not only maintain the sparsity of aligned features to solve the under-segmentation on small objects, but also reduce the computation amount of the network through sparse convolution. Our method outperforms previous methods by a large margin in the SemanticKITTI dataset for the challenging 3D PS task, achieving 1st place with a real-time inference speed.
DRINet++: Efficient Voxel-as-point Point Cloud Segmentation
Nov 16, 2021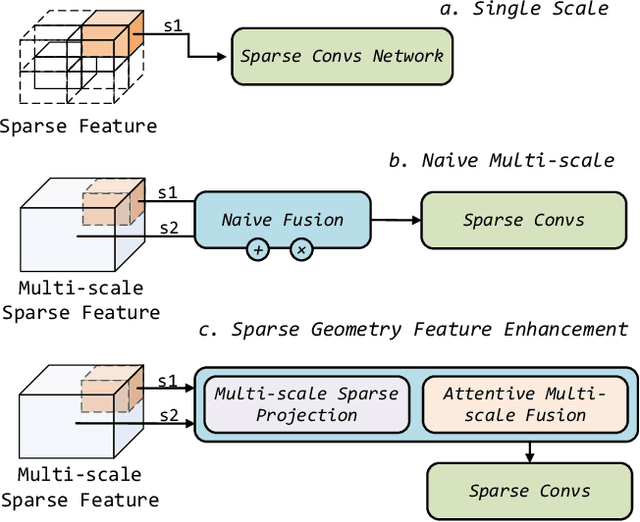
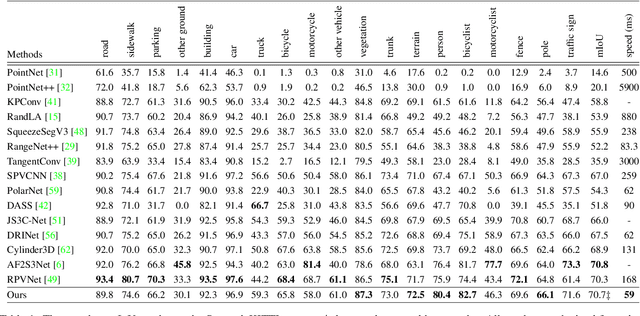
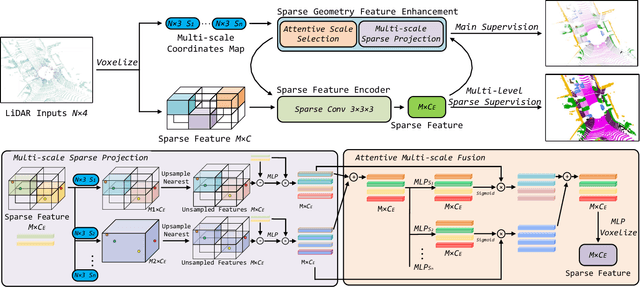
Recently, many approaches have been proposed through single or multiple representations to improve the performance of point cloud semantic segmentation. However, these works do not maintain a good balance among performance, efficiency, and memory consumption. To address these issues, we propose DRINet++ that extends DRINet by enhancing the sparsity and geometric properties of a point cloud with a voxel-as-point principle. To improve efficiency and performance, DRINet++ mainly consists of two modules: Sparse Feature Encoder and Sparse Geometry Feature Enhancement. The Sparse Feature Encoder extracts the local context information for each point, and the Sparse Geometry Feature Enhancement enhances the geometric properties of a sparse point cloud via multi-scale sparse projection and attentive multi-scale fusion. In addition, we propose deep sparse supervision in the training phase to help convergence and alleviate the memory consumption problem. Our DRINet++ achieves state-of-the-art outdoor point cloud segmentation on both SemanticKITTI and Nuscenes datasets while running significantly faster and consuming less memory.
DRINet: A Dual-Representation Iterative Learning Network for Point Cloud Segmentation
Aug 09, 2021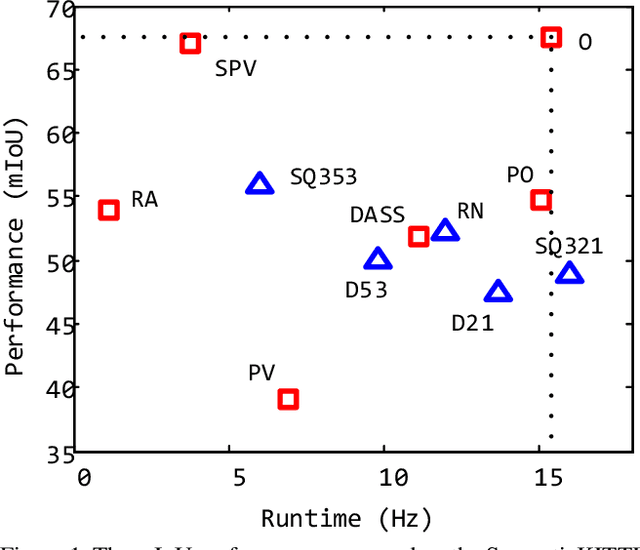
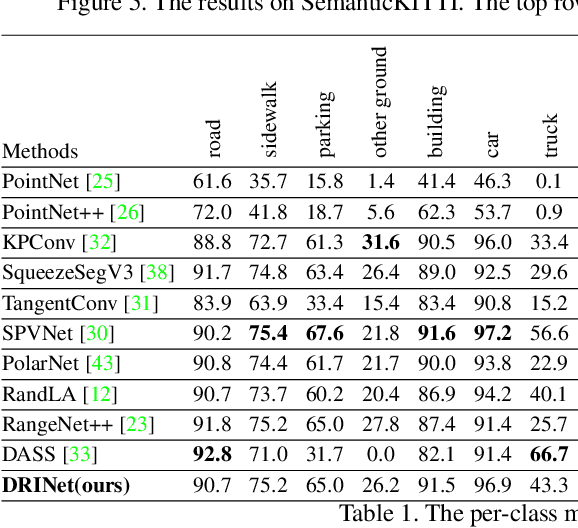
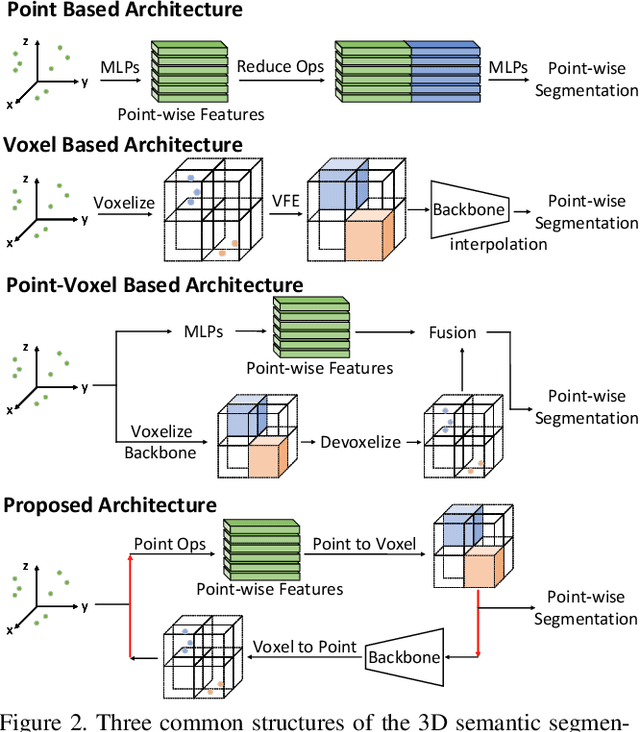

We present a novel and flexible architecture for point cloud segmentation with dual-representation iterative learning. In point cloud processing, different representations have their own pros and cons. Thus, finding suitable ways to represent point cloud data structure while keeping its own internal physical property such as permutation and scale-invariant is a fundamental problem. Therefore, we propose our work, DRINet, which serves as the basic network structure for dual-representation learning with great flexibility at feature transferring and less computation cost, especially for large-scale point clouds. DRINet mainly consists of two modules called Sparse Point-Voxel Feature Extraction and Sparse Voxel-Point Feature Extraction. By utilizing these two modules iteratively, features can be propagated between two different representations. We further propose a novel multi-scale pooling layer for pointwise locality learning to improve context information propagation. Our network achieves state-of-the-art results for point cloud classification and segmentation tasks on several datasets while maintaining high runtime efficiency. For large-scale outdoor scenarios, our method outperforms state-of-the-art methods with a real-time inference speed of 62ms per frame.