 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Domain Learning for Cross-domain Image Denoising
Nov 03, 2024



Different camera sensors have different noise patterns, and thus an image denoising model trained on one sensor often does not generalize well to a different sensor. One plausible solution is to collect a large dataset for each sensor for training or fine-tuning, which is inevitably time-consuming. To address this cross-domain challenge, we present a novel adaptive domain learning (ADL) scheme for cross-domain RAW image denoising by utilizing existing data from different sensors (source domain) plus a small amount of data from the new sensor (target domain). The ADL training scheme automatically removes the data in the source domain that are harmful to fine-tuning a model for the target domain (some data are harmful as adding them during training lowers the performance due to domain gaps). Also, we introduce a modulation module to adopt sensor-specific information (sensor type and ISO) to understand input data for image denoising. We conduct extensive experiments on public datasets with various smartphone and DSLR cameras, which show our proposed model outperforms prior work on cross-domain image denoising, given a small amount of image data from the target domain sensor.
Learning High-resolution Vector Representation from Multi-Camera Images for 3D Object Detection
Jul 22, 2024The Bird's-Eye-View (BEV) representation is a critical factor that directly impacts the 3D object detection performance, but the traditional BEV grid representation induces quadratic computational cost as the spatial resolution grows. To address this limitation, we present a new camera-based 3D object detector with high-resolution vector representation: VectorFormer. The presented high-resolution vector representation is combined with the lower-resolution BEV representation to efficiently exploit 3D geometry from multi-camera images at a high resolution through our two novel modules: vector scattering and gathering. To this end, the learned vector representation with richer scene contexts can serve as the decoding query for final predictions. We conduct extensive experiments on the nuScenes dataset and demonstrate state-of-the-art performance in NDS and inference time. Furthermore, we investigate query-BEV-based methods incorporated with our proposed vector representation and observe a consistent performance improvement.
Point Cloud Compression with Sibling Context and Surface Priors
May 02, 2022
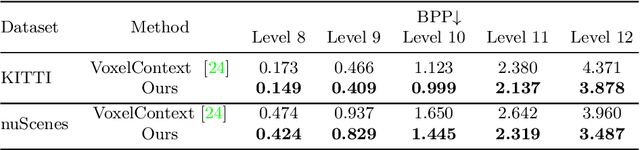
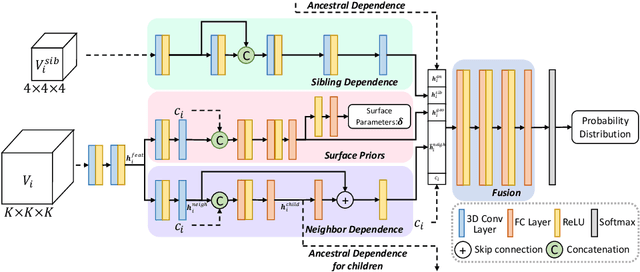
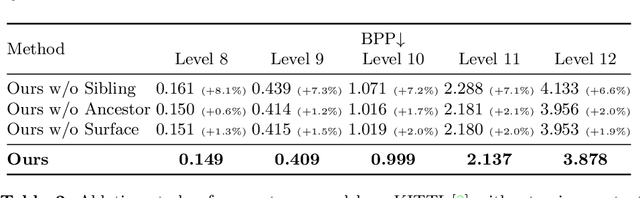
We present a novel octree-based multi-level framework for large-scale point cloud compression, which can organize sparse and unstructured point clouds in a memory-efficient way. In this framework, we propose a new entropy model that explores the hierarchical dependency in an octree using the context of siblings' children, ancestors, and neighbors to encode the occupancy information of each non-leaf octree node into a bitstream. Moreover, we locally fit quadratic surfaces with a voxel-based geometry-aware module to provide geometric priors in entropy encoding. These strong priors empower our entropy framework to encode the octree into a more compact bitstream. In the decoding stage, we apply a two-step heuristic strategy to restore point clouds with better reconstruction quality. The quantitative evaluation shows that our method outperforms state-of-the-art baselines with a bitrate improvement of 11-16% and 12-14% on the KITTI Odometry and nuScenes datasets, respectively.
Invertible Image Signal Processing
Apr 06, 2021
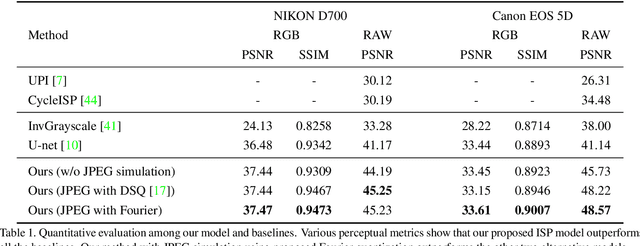

Unprocessed RAW data is a highly valuable image format for image editing and computer vision. However, since the file size of RAW data is huge, most users can only get access to processed and compressed sRGB images. To bridge this gap, we design an Invertible Image Signal Processing (InvISP) pipeline, which not only enables rendering visually appealing sRGB images but also allows recovering nearly perfect RAW data. Due to our framework's inherent reversibility, we can reconstruct realistic RAW data instead of synthesizing RAW data from sRGB images without any memory overhead. We also integrate a differentiable JPEG compression simulator that empowers our framework to reconstruct RAW data from JPEG images. Extensive quantitative and qualitative experiments on two DSLR demonstrate that our method obtains much higher quality in both rendered sRGB images and reconstructed RAW data than alternative methods.
Video Deblurring by Fitting to Test Data
Dec 09, 2020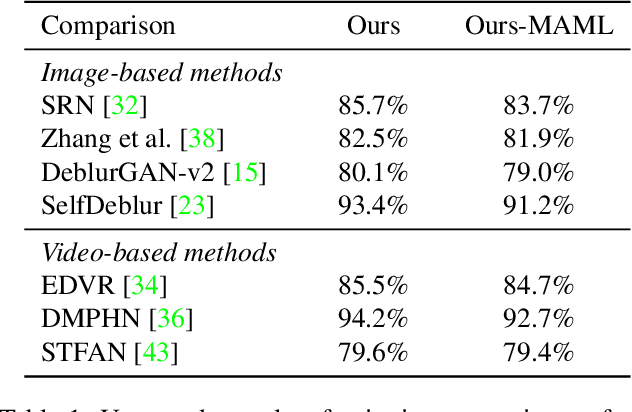
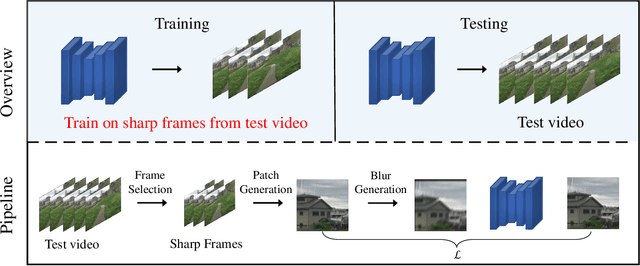


We present a novel approach to video deblurring by fitting a deep network to the test video. One key observation is that some frames in a video with motion blur are much sharper than others, and thus we can transfer the texture information in those sharp frames to blurry frames. Our approach heuristically selects sharp frames from a video and then trains a convolutional neural network on these sharp frames. The trained network often absorbs enough details in the scene to perform deblurring on all the video frames. As an internal learning method, our approach has no domain gap between training and test data, which is a problematic issue for existing video deblurring approaches. The conducted experiments on real-world video data show that our model can reconstruct clearer and sharper videos than state-of-the-art video deblurring approaches. Code and data are available at https://github.com/xrenaa/Deblur-by-Fitting.