 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTLDM: Spatio-Temporal Latent Diffusion Model for Precipitation Nowcasting
Dec 24, 2025Precipitation nowcasting is a critical spatio-temporal prediction task for society to prevent severe damage owing to extreme weather events. Despite the advances in this field, the complex and stochastic nature of this task still poses challenges to existing approaches. Specifically, deterministic models tend to produce blurry predictions while generative models often struggle with poor accuracy. In this paper, we present a simple yet effective model architecture termed STLDM, a diffusion-based model that learns the latent representation from end to end alongside both the Variational Autoencoder and the conditioning network. STLDM decomposes this task into two stages: a deterministic forecasting stage handled by the conditioning network, and an enhancement stage performed by the latent diffusion model. Experimental results on multiple radar datasets demonstrate that STLDM achieves superior performance compared to the state of the art, while also improving inference efficiency. The code is available in https://github.com/sqfoo/stldm_official.
DivLogicEval: A Framework for Benchmarking Logical Reasoning Evaluation in Large Language Models
Sep 19, 2025Logic reasoning in natural language has been recognized as an important measure of human intelligence for Large Language Models (LLMs). Popular benchmarks may entangle multiple reasoning skills and thus provide unfaithful evaluations on the logic reasoning skill. Meanwhile, existing logic reasoning benchmarks are limited in language diversity and their distributions are deviated from the distribution of an ideal logic reasoning benchmark, which may lead to biased evaluation results. This paper thereby proposes a new classical logic benchmark DivLogicEval, consisting of natural sentences composed of diverse statements in a counterintuitive way. To ensure a more reliable evaluation, we also introduce a new evaluation metric that mitigates the influence of bias and randomness inherent in LLMs. Through experiments, we demonstrate the extent to which logical reasoning is required to answer the questions in DivLogicEval and compare the performance of different popular LLMs in conducting logical reasoning.
ECCV 2024 W-CODA: 1st Workshop on Multimodal Perception and Comprehension of Corner Cases in Autonomous Driving
Jul 02, 2025
In this paper, we present details of the 1st W-CODA workshop, held in conjunction with the ECCV 2024. W-CODA aims to explore next-generation solutions for autonomous driving corner cases, empowered by state-of-the-art multimodal perception and comprehension techniques. 5 Speakers from both academia and industry are invited to share their latest progress and opinions. We collect research papers and hold a dual-track challenge, including both corner case scene understanding and generation. As the pioneering effort, we will continuously bridge the gap between frontier autonomous driving techniques and fully intelligent, reliable self-driving agents robust towards corner cases.
Learning 3D Persistent Embodied World Models
May 05, 2025
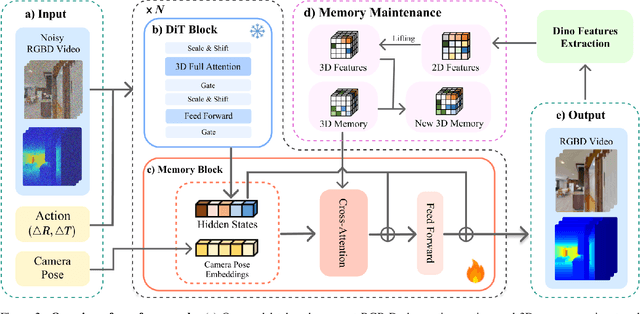
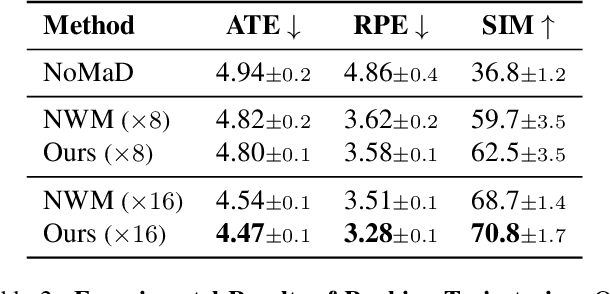
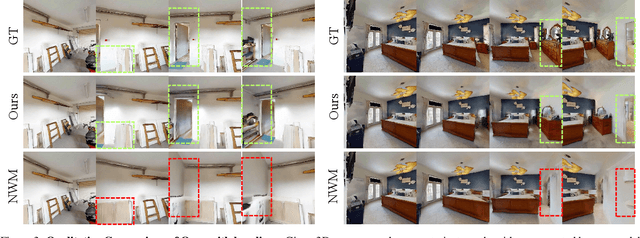
The ability to simulate the effects of future actions on the world is a crucial ability of intelligent embodied agents, enabling agents to anticipate the effects of their actions and make plans accordingly. While a large body of existing work has explored how to construct such world models using video models, they are often myopic in nature, without any memory of a scene not captured by currently observed images, preventing agents from making consistent long-horizon plans in complex environments where many parts of the scene are partially observed. We introduce a new persistent embodied world model with an explicit memory of previously generated content, enabling much more consistent long-horizon simulation. During generation time, our video diffusion model predicts RGB-D video of the future observations of the agent. This generation is then aggregated into a persistent 3D map of the environment. By conditioning the video model on this 3D spatial map, we illustrate how this enables video world models to faithfully simulate both seen and unseen parts of the world. Finally, we illustrate the efficacy of such a world model in downstream embodied applications, enabling effective planning and policy learning.
CoherenDream: Boosting Holistic Text Coherence in 3D Generation via Multimodal Large Language Models Feedback
Apr 28, 2025



Score Distillation Sampling (SDS) has achieved remarkable success in text-to-3D content generation. However, SDS-based methods struggle to maintain semantic fidelity for user prompts, particularly when involving multiple objects with intricate interactions. While existing approaches often address 3D consistency through multiview diffusion model fine-tuning on 3D datasets, this strategy inadvertently exacerbates text-3D alignment degradation. The limitation stems from SDS's inherent accumulation of view-independent biases during optimization, which progressively diverges from the ideal text alignment direction. To alleviate this limitation, we propose a novel SDS objective, dubbed as Textual Coherent Score Distillation (TCSD), which integrates alignment feedback from multimodal large language models (MLLMs). Our TCSD leverages cross-modal understanding capabilities of MLLMs to assess and guide the text-3D correspondence during the optimization. We further develop 3DLLaVA-CRITIC - a fine-tuned MLLM specialized for evaluating multiview text alignment in 3D generations. Additionally, we introduce an LLM-layout initialization that significantly accelerates optimization convergence through semantic-aware spatial configuration. Comprehensive evaluations demonstrate that our framework, CoherenDream, establishes state-of-the-art performance in text-aligned 3D generation across multiple benchmarks, including T$^3$Bench and TIFA subset. Qualitative results showcase the superior performance of CoherenDream in preserving textual consistency and semantic interactions. As the first study to incorporate MLLMs into SDS optimization, we also conduct extensive ablation studies to explore optimal MLLM adaptations for 3D generation tasks.
The Stochastic Parrot on LLM's Shoulder: A Summative Assessment of Physical Concept Understanding
Feb 13, 2025



In a systematic way, we investigate a widely asked question: Do LLMs really understand what they say?, which relates to the more familiar term Stochastic Parrot. To this end, we propose a summative assessment over a carefully designed physical concept understanding task, PhysiCo. Our task alleviates the memorization issue via the usage of grid-format inputs that abstractly describe physical phenomena. The grids represents varying levels of understanding, from the core phenomenon, application examples to analogies to other abstract patterns in the grid world. A comprehensive study on our task demonstrates: (1) state-of-the-art LLMs, including GPT-4o, o1 and Gemini 2.0 flash thinking, lag behind humans by ~40%; (2) the stochastic parrot phenomenon is present in LLMs, as they fail on our grid task but can describe and recognize the same concepts well in natural language; (3) our task challenges the LLMs due to intrinsic difficulties rather than the unfamiliar grid format, as in-context learning and fine-tuning on same formatted data added little to their performance.
Understanding LLMs' Fluid Intelligence Deficiency: An Analysis of the ARC Task
Feb 11, 2025



While LLMs have exhibited strong performance on various NLP tasks, it is noteworthy that most of these tasks rely on utilizing the vast amount of knowledge encoded in LLMs' parameters, rather than solving new problems without prior knowledge. In cognitive research, the latter ability is referred to as fluid intelligence, which is considered to be critical for assessing human intelligence. Recent research on fluid intelligence assessments has highlighted significant deficiencies in LLMs' abilities. In this paper, we analyze the challenges LLMs face in demonstrating fluid intelligence through controlled experiments, using the most representative ARC task as an example. Our study revealed three major limitations in existing LLMs: limited ability for skill composition, unfamiliarity with abstract input formats, and the intrinsic deficiency of left-to-right decoding. Our data and code can be found in https://wujunjie1998.github.io/araoc-benchmark.github.io/.
G-VEval: A Versatile Metric for Evaluating Image and Video Captions Using GPT-4o
Dec 19, 2024



Evaluation metric of visual captioning is important yet not thoroughly explored. Traditional metrics like BLEU, METEOR, CIDEr, and ROUGE often miss semantic depth, while trained metrics such as CLIP-Score, PAC-S, and Polos are limited in zero-shot scenarios. Advanced Language Model-based metrics also struggle with aligning to nuanced human preferences. To address these issues, we introduce G-VEval, a novel metric inspired by G-Eval and powered by the new GPT-4o. G-VEval uses chain-of-thought reasoning in large multimodal models and supports three modes: reference-free, reference-only, and combined, accommodating both video and image inputs. We also propose MSVD-Eval, a new dataset for video captioning evaluation, to establish a more transparent and consistent framework for both human experts and evaluation metrics. It is designed to address the lack of clear criteria in existing datasets by introducing distinct dimensions of Accuracy, Completeness, Conciseness, and Relevance (ACCR). Extensive results show that G-VEval outperforms existing methods in correlation with human annotations, as measured by Kendall tau-b and Kendall tau-c. This provides a flexible solution for diverse captioning tasks and suggests a straightforward yet effective approach for large language models to understand video content, paving the way for advancements in automated captioning. Codes are available at https://github.com/ztangaj/gveval
SG-LRA: Self-Generating Automatic Scoliosis Cobb Angle Measurement with Low-Rank Approximation
Nov 19, 2024



Automatic Cobb angle measurement from X-ray images is crucial for scoliosis screening and diagnosis. However, most existing regression-based methods and segmentation-based methods struggle with inaccurate spine representations or mask connectivity/fragmentation issues. Besides, landmark-based methods suffer from insufficient training data and annotations. To address these challenges, we propose a novel framework including Self-Generation pipeline and Low-Rank Approximation representation (SG-LRA) for automatic Cobb angle measurement. Specifically, we propose a parameterized spine contour representation based on LRA, which enables eigen-spine decomposition and spine contour reconstruction. We can directly obtain spine contour with only regressed LRA coefficients, which form a more accurate spine representation than rectangular boxes. Also, we combine LRA coefficient regression with anchor box classification to solve inaccurate predictions and mask connectivity issues. Moreover, we develop a data engine with automatic annotation and automatic selection in an iterative manner, which is trained on a private Spinal2023 dataset. With our data engine, we generate the largest scoliosis X-ray dataset named Spinal-AI2024 largely without privacy leaks. Extensive experiments on public AASCE2019, private Spinal2023, and generated Spinal-AI2024 datasets demonstrate that our method achieves state-of-the-art Cobb angle measurement performance. Our code and Spinal-AI2024 dataset are available at https://github.com/Ernestchenchen/SG-LRA and https://github.com/Ernestchenchen/Spinal-AI2024, respectively.
Fourier Amplitude and Correlation Loss: Beyond Using L2 Loss for Skillful Precipitation Nowcasting
Oct 30, 2024



Deep learning approaches have been widely adopted for precipitation nowcasting in recent years. Previous studies mainly focus on proposing new model architectures to improve pixel-wise metrics. However, they frequently result in blurry predictions which provide limited utility to forecasting operations. In this work, we propose a new Fourier Amplitude and Correlation Loss (FACL) which consists of two novel loss terms: Fourier Amplitude Loss (FAL) and Fourier Correlation Loss (FCL). FAL regularizes the Fourier amplitude of the model prediction and FCL complements the missing phase information. The two loss terms work together to replace the traditional $L_2$ losses such as MSE and weighted MSE for the spatiotemporal prediction problem on signal-based data. Our method is generic, parameter-free and efficient. Extensive experiments using one synthetic dataset and three radar echo datasets demonstrate that our method improves perceptual metrics and meteorology skill scores, with a small trade-off to pixel-wise accuracy and structural similarity. Moreover, to improve the error margin in meteorological skill scores such as Critical Success Index (CSI) and Fractions Skill Score (FSS), we propose and adopt the Regional Histogram Divergence (RHD), a distance metric that considers the patch-wise similarity between signal-based imagery patterns with tolerance to local transforms. Code is available at https://github.com/argenycw/FACL