 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuzzy Reasoning Chain (FRC): An Innovative Reasoning Framework from Fuzziness to Clarity
Sep 26, 2025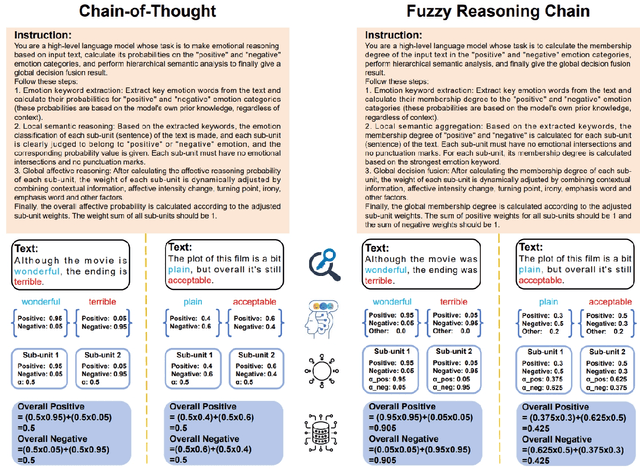
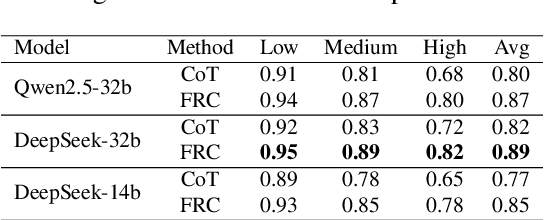
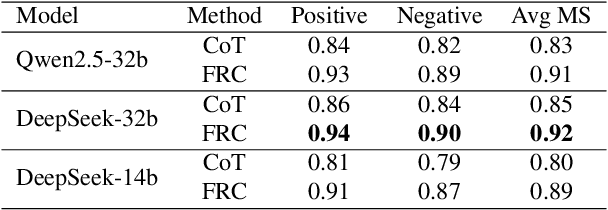
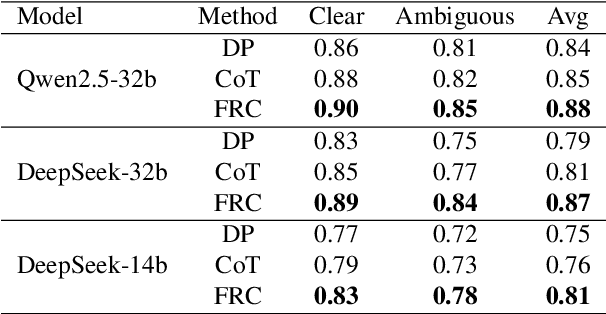
With the rapid advancement of large language models (LLMs), natural language processing (NLP) has achieved remarkable progress. Nonetheless, significant challenges remain in handling texts with ambiguity, polysemy, or uncertainty. We introduce the Fuzzy Reasoning Chain (FRC) framework, which integrates LLM semantic priors with continuous fuzzy membership degrees, creating an explicit interaction between probability-based reasoning and fuzzy membership reasoning. This transition allows ambiguous inputs to be gradually transformed into clear and interpretable decisions while capturing conflicting or uncertain signals that traditional probability-based methods cannot. We validate FRC on sentiment analysis tasks, where both theoretical analysis and empirical results show that it ensures stable reasoning and facilitates knowledge transfer across different model scales. These findings indicate that FRC provides a general mechanism for managing subtle and ambiguous expressions with improved interpretability and robustness.
Quantitative Analysis of Performance Drop in DeepSeek Model Quantization
May 05, 2025Recently, there is a high demand for deploying DeepSeek-R1 and V3 locally, possibly because the official service often suffers from being busy and some organizations have data privacy concerns. While single-machine deployment offers infrastructure simplicity, the models' 671B FP8 parameter configuration exceeds the practical memory limits of a standard 8-GPU machine. Quantization is a widely used technique that helps reduce model memory consumption. However, it is unclear what the performance of DeepSeek-R1 and V3 will be after being quantized. This technical report presents the first quantitative evaluation of multi-bitwidth quantization across the complete DeepSeek model spectrum. Key findings reveal that 4-bit quantization maintains little performance degradation versus FP8 while enabling single-machine deployment on standard NVIDIA GPU devices. We further propose DQ3_K_M, a dynamic 3-bit quantization method that significantly outperforms traditional Q3_K_M variant on various benchmarks, which is also comparable with 4-bit quantization (Q4_K_M) approach in most tasks. Moreover, DQ3_K_M supports single-machine deployment configurations for both NVIDIA H100/A100 and Huawei 910B. Our implementation of DQ3\_K\_M is released at https://github.com/UnicomAI/DeepSeek-Eval, containing optimized 3-bit quantized variants of both DeepSeek-R1 and DeepSeek-V3.
DAST: Difficulty-Adaptive Slow-Thinking for Large Reasoning Models
Mar 06, 2025Recent advancements in slow-thinking reasoning models have shown exceptional performance in complex reasoning tasks. However, these models often exhibit overthinking-generating redundant reasoning steps for simple problems, leading to excessive computational resource usage. While current mitigation strategies uniformly reduce reasoning tokens, they risk degrading performance on challenging tasks that require extended reasoning. This paper introduces Difficulty-Adaptive Slow-Thinking (DAST), a novel framework that enables models to autonomously adjust the length of Chain-of-Thought(CoT) based on problem difficulty. We first propose a Token Length Budget (TLB) metric to quantify difficulty, then leveraging length-aware reward shaping and length preference optimization to implement DAST. DAST penalizes overlong responses for simple tasks while incentivizing sufficient reasoning for complex problems. Experiments on diverse datasets and model scales demonstrate that DAST effectively mitigates overthinking (reducing token usage by over 30\% on average) while preserving reasoning accuracy on complex problems.
CuDIP: Enhancing Theorem Proving in LLMs via Curriculum Learning-based Direct Preference Optimization
Feb 25, 2025Automated theorem proving (ATP) is one of the most challenging mathematical reasoning tasks for Large Language Models (LLMs). Most existing LLM-based ATP methods rely on supervised fine-tuning, which results in a limited alignment between the theorem proving process and human preferences. Direct Preference Optimization (DPO), which aligns LLMs with human preferences, has shown positive effects for certain tasks. However, the lack of high-quality preference data for theorem proving presents a significant challenge. In this paper, we innovatively apply DPO to formal automated theorem proving and introduces a Curriculum Learning-based DPO Iterative Theorem Proving (CuDIP) method. Specifically, we propose a method for constructing preference data which utilizes LLMs and existing theorem proving data to enhance the diversity of the preference data while reducing the reliance on human preference annotations. We then integrate this preference data construction method with curriculum learning to iteratively fine-tune the theorem proving model through DPO. Experimental results on the MiniF2F and ProofNet datasets demonstrate the effectiveness of the proposed method.
Selection-p: Self-Supervised Task-Agnostic Prompt Compression for Faithfulness and Transferability
Oct 15, 2024
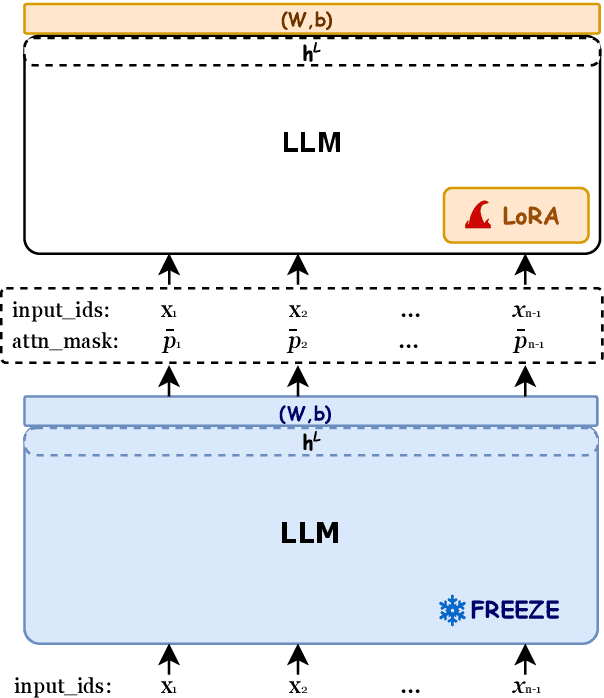


Large Language Models (LLMs) have demonstrated impressive capabilities in a wide range of natural language processing tasks when leveraging in-context learning. To mitigate the additional computational and financial costs associated with in-context learning, several prompt compression methods have been proposed to compress the in-context learning prompts. Despite their success, these methods face challenges with transferability due to model-specific compression, or rely on external training data, such as GPT-4. In this paper, we investigate the ability of LLMs to develop a unified compression method that discretizes uninformative tokens, utilizing a self-supervised pre-training technique. By introducing a small number of parameters during the continual pre-training, the proposed Selection-p produces a probability for each input token, indicating whether to preserve or discard it. Experiments show Selection-p achieves state-of-the-art performance across numerous classification tasks, achieving compression rates of up to 10 times while experiencing only a marginal 0.8% decrease in performance. Moreover, it exhibits superior transferability to different models compared to prior work. Additionally, we further analyze how Selection-p helps maintain performance on in-context learning with long contexts.
An Energy-based Model for Word-level AutoCompletion in Computer-aided Translation
Jul 29, 2024Word-level AutoCompletion(WLAC) is a rewarding yet challenging task in Computer-aided Translation. Existing work addresses this task through a classification model based on a neural network that maps the hidden vector of the input context into its corresponding label (i.e., the candidate target word is treated as a label). Since the context hidden vector itself does not take the label into account and it is projected to the label through a linear classifier, the model can not sufficiently leverage valuable information from the source sentence as verified in our experiments, which eventually hinders its overall performance. To alleviate this issue, this work proposes an energy-based model for WLAC, which enables the context hidden vector to capture crucial information from the source sentence. Unfortunately, training and inference suffer from efficiency and effectiveness challenges, thereby we employ three simple yet effective strategies to put our model into practice. Experiments on four standard benchmarks demonstrate that our reranking-based approach achieves substantial improvements (about 6.07%) over the previous state-of-the-art model. Further analyses show that each strategy of our approach contributes to the final performance.
Not All Preference Pairs Are Created Equal: A Recipe for Annotation-Efficient Iterative Preference Learning
Jun 25, 2024



Iterative preference learning, though yielding superior performances, requires online annotated preference labels. In this work, we study strategies to select worth-annotating response pairs for cost-efficient annotation while achieving competitive or even better performances compared with the random selection baseline for iterative preference learning. Built on assumptions regarding uncertainty and distribution shifts, we propose a comparative view to rank the implicit reward margins as predicted by DPO to select the response pairs that yield more benefits. Through extensive experiments, we show that annotating those response pairs with small margins is generally better than large or random, under both single- and multi-iteration scenarios. Besides, our empirical results suggest allocating more annotation budgets in the earlier iterations rather than later across multiple iterations.
On the Transformations across Reward Model, Parameter Update, and In-Context Prompt
Jun 24, 2024Despite the general capabilities of pre-trained large language models (LLMs), they still need further adaptation to better serve practical applications. In this paper, we demonstrate the interchangeability of three popular and distinct adaptation tools: parameter updating, reward modeling, and in-context prompting. This interchangeability establishes a triangular framework with six transformation directions, each of which facilitates a variety of applications. Our work offers a holistic view that unifies numerous existing studies and suggests potential research directions. We envision our work as a useful roadmap for future research on LLMs.
Disperse-Then-Merge: Pushing the Limits of Instruction Tuning via Alignment Tax Reduction
May 22, 2024



Supervised fine-tuning (SFT) on instruction-following corpus is a crucial approach toward the alignment of large language models (LLMs). However, the performance of LLMs on standard knowledge and reasoning benchmarks tends to suffer from deterioration at the latter stage of the SFT process, echoing the phenomenon of alignment tax. Through our pilot study, we put a hypothesis that the data biases are probably one cause behind the phenomenon. To address the issue, we introduce a simple disperse-then-merge framework. To be concrete, we disperse the instruction-following data into portions and train multiple sub-models using different data portions. Then we merge multiple models into a single one via model merging techniques. Despite its simplicity, our framework outperforms various sophisticated methods such as data curation and training regularization on a series of standard knowledge and reasoning benchmarks.
Spotting AI's Touch: Identifying LLM-Paraphrased Spans in Text
May 21, 2024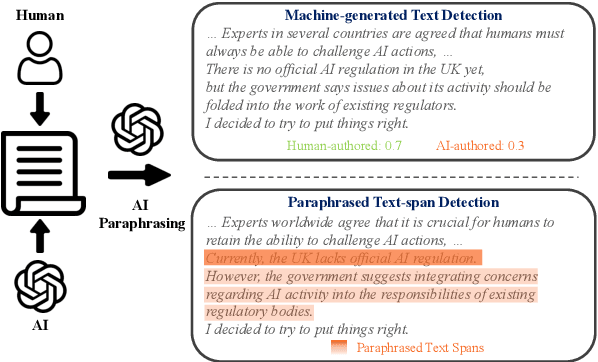



AI-generated text detection has attracted increasing attention as powerful language models approach human-level generation. Limited work is devoted to detecting (partially) AI-paraphrased texts. However, AI paraphrasing is commonly employed in various application scenarios for text refinement and diversity. To this end, we propose a novel detection framework, paraphrased text span detection (PTD), aiming to identify paraphrased text spans within a text. Different from text-level detection, PTD takes in the full text and assigns each of the sentences with a score indicating the paraphrasing degree. We construct a dedicated dataset, PASTED, for paraphrased text span detection. Both in-distribution and out-of-distribution results demonstrate the effectiveness of PTD models in identifying AI-paraphrased text spans. Statistical and model analysis explains the crucial role of the surrounding context of the paraphrased text spans. Extensive experiments show that PTD models can generalize to versatile paraphrasing prompts and multiple paraphrased text spans. We release our resources at https://github.com/Linzwcs/PASTED.