 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-PiT: Enhancing Structural Coherence in Part-Based Image Synthesis via Graph Priors
Apr 07, 2026Achieving fine-grained and structurally sound controllability is a cornerstone of advanced visual generation. Existing part-based frameworks treat user-provided parts as an unordered set and therefore ignore their intrinsic spatial and semantic relationships, which often results in compositions that lack structural integrity. To bridge this gap, we propose Graph-PiT, a framework that explicitly models the structural dependencies of visual components using a graph prior. Specifically, we represent visual parts as nodes and their spatial-semantic relationships as edges. At the heart of our method is a Hierarchical Graph Neural Network (HGNN) module that performs bidirectional message passing between coarse-grained part-level super-nodes and fine-grained IP+ token sub-nodes, refining part embeddings before they enter the generative pipeline. We also introduce a graph Laplacian smoothness loss and an edge-reconstruction loss so that adjacent parts acquire compatible, relation-aware embeddings. Quantitative experiments on controlled synthetic domains (character, product, indoor layout, and jigsaw), together with qualitative transfer to real web images, show that Graph-PiT improves structural coherence over vanilla PiT while remaining compatible with the original IP-Prior pipeline. Ablation experiments confirm that explicit relational reasoning is crucial for enforcing user-specified adjacency constraints. Our approach not only enhances the plausibility of generated concepts but also offers a scalable and interpretable mechanism for complex, multi-part image synthesis. The code is available at https://github.com/wolf-bailang/Graph-PiT.
DermoGPT: Open Weights and Open Data for Morphology-Grounded Dermatological Reasoning MLLMs
Jan 05, 2026Multimodal Large Language Models (MLLMs) show promise for medical applications, yet progress in dermatology lags due to limited training data, narrow task coverage, and lack of clinically-grounded supervision that mirrors expert diagnostic workflows. We present a comprehensive framework to address these gaps. First, we introduce DermoInstruct, a large-scale morphology-anchored instruction corpus comprising 211,243 images and 772,675 trajectories across five task formats, capturing the complete diagnostic pipeline from morphological observation and clinical reasoning to final diagnosis. Second, we establish DermoBench, a rigorous benchmark evaluating 11 tasks across four clinical axes: Morphology, Diagnosis, Reasoning, and Fairness, including a challenging subset of 3,600 expert-verified open-ended instances and human performance baselines. Third, we develop DermoGPT, a dermatology reasoning MLLM trained via supervised fine-tuning followed by our Morphologically-Anchored Visual-Inference-Consistent (MAVIC) reinforcement learning objective, which enforces consistency between visual observations and diagnostic conclusions. At inference, we deploy Confidence-Consistency Test-time adaptation (CCT) for robust predictions. Experiments show DermoGPT significantly outperforms 16 representative baselines across all axes, achieving state-of-the-art performance while substantially narrowing the human-AI gap. DermoInstruct, DermoBench and DermoGPT will be made publicly available at https://github.com/mendicant04/DermoGPT upon acceptance.
MolSculpt: Sculpting 3D Molecular Geometries from Chemical Syntax
Dec 09, 2025Generating precise 3D molecular geometries is crucial for drug discovery and material science. While prior efforts leverage 1D representations like SELFIES to ensure molecular validity, they fail to fully exploit the rich chemical knowledge entangled within 1D models, leading to a disconnect between 1D syntactic generation and 3D geometric realization. To bridge this gap, we propose MolSculpt, a novel framework that "sculpts" 3D molecular geometries from chemical syntax. MolSculpt is built upon a frozen 1D molecular foundation model and a 3D molecular diffusion model. We introduce a set of learnable queries to extract inherent chemical knowledge from the foundation model, and a trainable projector then injects this cross-modal information into the conditioning space of the diffusion model to guide the 3D geometry generation. In this way, our model deeply integrates 1D latent chemical knowledge into the 3D generation process through end-to-end optimization. Experiments demonstrate that MolSculpt achieves state-of-the-art (SOTA) performance in \textit{de novo} 3D molecule generation and conditional 3D molecule generation, showing superior 3D fidelity and stability on both the GEOM-DRUGS and QM9 datasets. Code is available at https://github.com/SakuraTroyChen/MolSculpt.
IC-Custom: Diverse Image Customization via In-Context Learning
Jul 02, 2025Image customization, a crucial technique for industrial media production, aims to generate content that is consistent with reference images. However, current approaches conventionally separate image customization into position-aware and position-free customization paradigms and lack a universal framework for diverse customization, limiting their applications across various scenarios. To overcome these limitations, we propose IC-Custom, a unified framework that seamlessly integrates position-aware and position-free image customization through in-context learning. IC-Custom concatenates reference images with target images to a polyptych, leveraging DiT's multi-modal attention mechanism for fine-grained token-level interactions. We introduce the In-context Multi-Modal Attention (ICMA) mechanism with learnable task-oriented register tokens and boundary-aware positional embeddings to enable the model to correctly handle different task types and distinguish various inputs in polyptych configurations. To bridge the data gap, we carefully curated a high-quality dataset of 12k identity-consistent samples with 8k from real-world sources and 4k from high-quality synthetic data, avoiding the overly glossy and over-saturated synthetic appearance. IC-Custom supports various industrial applications, including try-on, accessory placement, furniture arrangement, and creative IP customization. Extensive evaluations on our proposed ProductBench and the publicly available DreamBench demonstrate that IC-Custom significantly outperforms community workflows, closed-source models, and state-of-the-art open-source approaches. IC-Custom achieves approximately 73% higher human preference across identity consistency, harmonicity, and text alignment metrics, while training only 0.4% of the original model parameters. Project page: https://liyaowei-stu.github.io/project/IC_Custom
Not All Tokens and Heads Are Equally Important: Dual-Level Attention Intervention for Hallucination Mitigation
Jun 14, 2025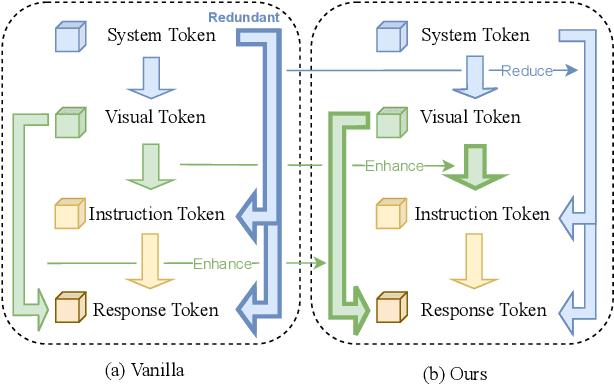
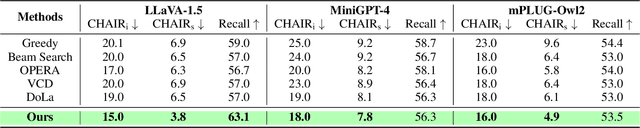
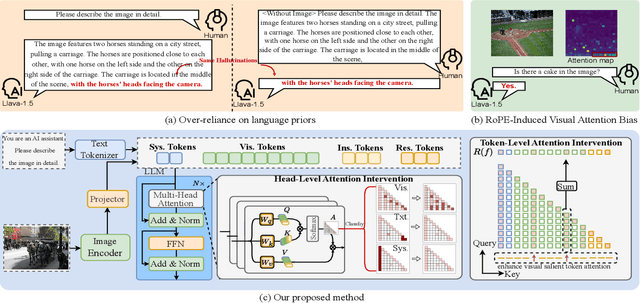

Large vision-language models (LVLMs) have shown remarkable capabilities across a wide range of multimodal tasks. However, they remain prone to visual hallucination (VH), often producing confident but incorrect descriptions of visual content. We present VisFlow, an efficient and training-free framework designed to mitigate VH by directly manipulating attention patterns during inference. Through systematic analysis, we identify three key pathological attention behaviors in LVLMs: (1) weak visual grounding, where attention to visual tokens is insufficient or misallocated, over-focusing on uninformative regions; (2) language prior dominance, where excessive attention to prior response tokens reinforces autoregressive patterns and impairs multimodal alignment; (3) prompt redundancy, where many attention heads fixate on system prompt tokens, disrupting the integration of image, instruction, and response content. To address these issues, we introduce two inference-time interventions: token-level attention intervention (TAI), which enhances focus on salient visual content, and head-level attention intervention (HAI), which suppresses over-attention to prompt and nearby text tokens. VisFlow operates without additional training or model modifications. Extensive experiments across models and benchmarks show that VisFlow effectively reduces hallucinations and improves visual factuality, with negligible computational cost.
BlobCtrl: A Unified and Flexible Framework for Element-level Image Generation and Editing
Mar 17, 2025Element-level visual manipulation is essential in digital content creation, but current diffusion-based methods lack the precision and flexibility of traditional tools. In this work, we introduce BlobCtrl, a framework that unifies element-level generation and editing using a probabilistic blob-based representation. By employing blobs as visual primitives, our approach effectively decouples and represents spatial location, semantic content, and identity information, enabling precise element-level manipulation. Our key contributions include: 1) a dual-branch diffusion architecture with hierarchical feature fusion for seamless foreground-background integration; 2) a self-supervised training paradigm with tailored data augmentation and score functions; and 3) controllable dropout strategies to balance fidelity and diversity. To support further research, we introduce BlobData for large-scale training and BlobBench for systematic evaluation. Experiments show that BlobCtrl excels in various element-level manipulation tasks while maintaining computational efficiency, offering a practical solution for precise and flexible visual content creation. Project page: https://liyaowei-stu.github.io/project/BlobCtrl/
ATRI: Mitigating Multilingual Audio Text Retrieval Inconsistencies by Reducing Data Distribution Errors
Feb 22, 2025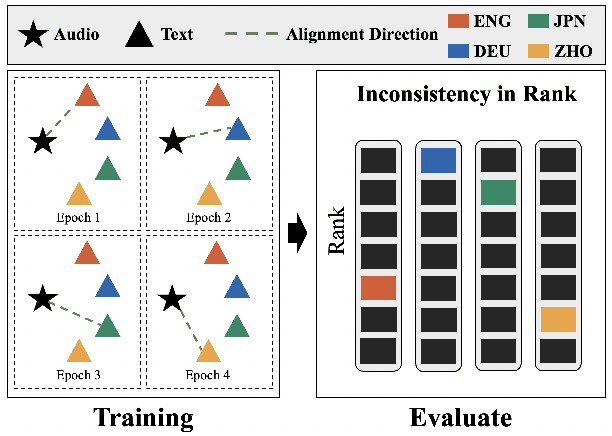
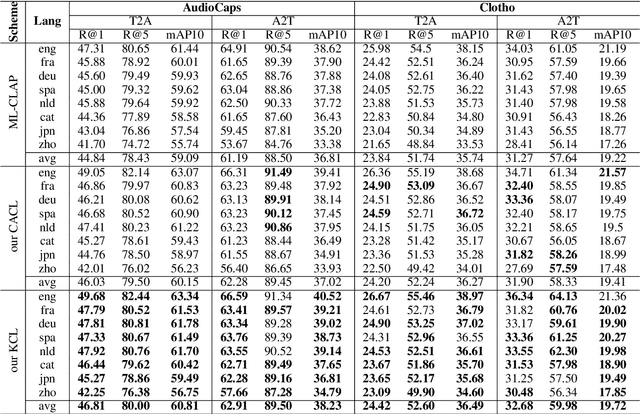
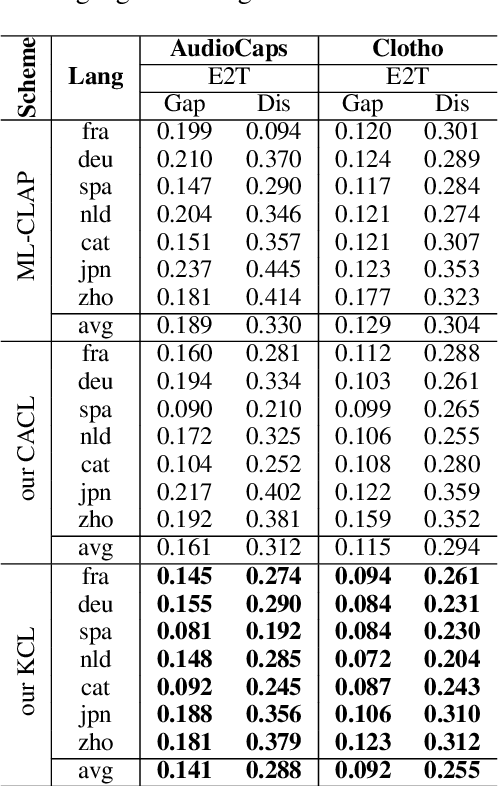
Multilingual audio-text retrieval (ML-ATR) is a challenging task that aims to retrieve audio clips or multilingual texts from databases. However, existing ML-ATR schemes suffer from inconsistencies for instance similarity matching across languages. We theoretically analyze the inconsistency in terms of both multilingual modal alignment direction error and weight error, and propose the theoretical weight error upper bound for quantifying the inconsistency. Based on the analysis of the weight error upper bound, we find that the inconsistency problem stems from the data distribution error caused by random sampling of languages. We propose a consistent ML-ATR scheme using 1-to-k contrastive learning and audio-English co-anchor contrastive learning, aiming to mitigate the negative impact of data distribution error on recall and consistency in ML-ATR. Experimental results on the translated AudioCaps and Clotho datasets show that our scheme achieves state-of-the-art performance on recall and consistency metrics for eight mainstream languages, including English. Our code will be available at https://github.com/ATRI-ACL/ATRI-ACL.
Do we really have to filter out random noise in pre-training data for language models?
Feb 10, 2025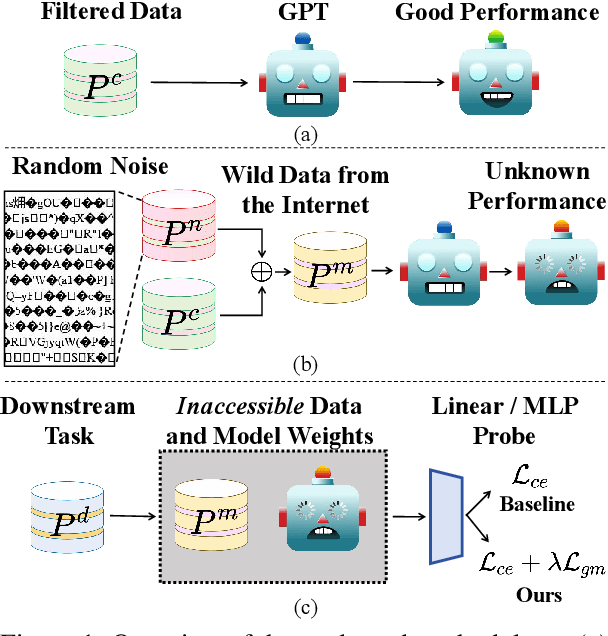



Web-scale pre-training datasets are the cornerstone of LLMs' success. However, text data curated from the internet inevitably contains random noise caused by decoding errors or unregulated web content. In contrast to previous works that focus on low quality or synthetic data, our study \textbf{provides the first systematic investigation into such random noise through a cohesive ``What-Why-How'' framework.} Surprisingly, we observed that the resulting increase in next-token prediction (NTP) loss was significantly lower than the proportion of random noise. We provide a theoretical justification for this phenomenon, which also elucidates the success of multilingual models. On the other hand, experiments show that the model's performance in downstream tasks is not based solely on the NTP loss, which means that random noise may result in degraded downstream performance. To address the potential adverse effects, we introduce a novel plug-and-play Local Gradient Matching loss, which explicitly enhances the denoising capability of the downstream task head by aligning the gradient of normal and perturbed features without requiring knowledge of the model's parameters. Additional experiments on 8 language and 14 vision benchmarks further validate its effectiveness.
VARGPT: Unified Understanding and Generation in a Visual Autoregressive Multimodal Large Language Model
Jan 21, 2025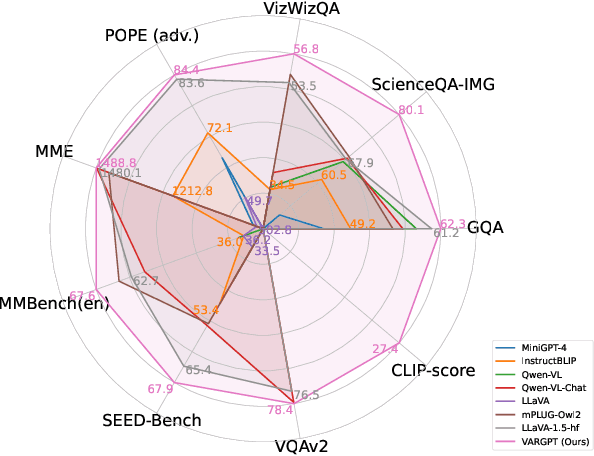
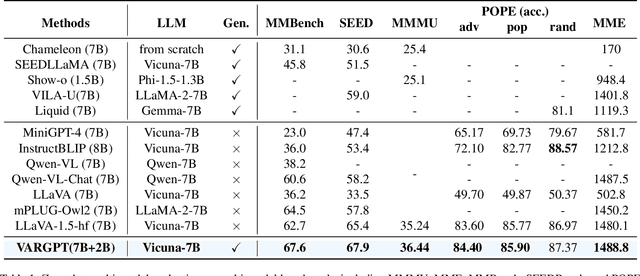

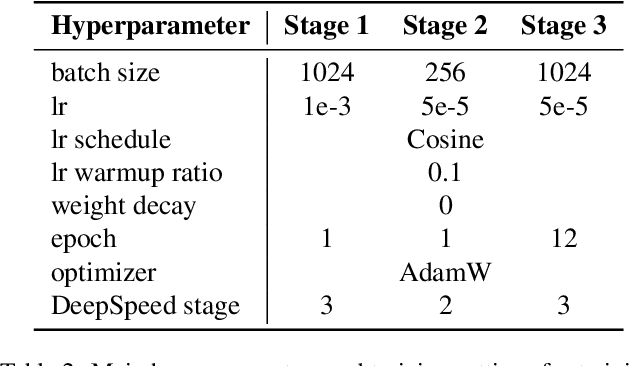
We present VARGPT, a novel multimodal large language model (MLLM) that unifies visual understanding and generation within a single autoregressive framework. VARGPT employs a next-token prediction paradigm for visual understanding and a next-scale prediction paradigm for visual autoregressive generation. VARGPT innovatively extends the LLaVA architecture, achieving efficient scale-wise autoregressive visual generation within MLLMs while seamlessly accommodating mixed-modal input and output within a single model framework. Our VARGPT undergoes a three-stage unified training process on specially curated datasets, comprising a pre-training phase and two mixed visual instruction-tuning phases. The unified training strategy are designed to achieve alignment between visual and textual features, enhance instruction following for both understanding and generation, and improve visual generation quality, respectively. Despite its LLAVA-based architecture for multimodel understanding, VARGPT significantly outperforms LLaVA-1.5 across various vision-centric benchmarks, such as visual question-answering and reasoning tasks. Notably, VARGPT naturally supports capabilities in autoregressive visual generation and instruction-to-image synthesis, showcasing its versatility in both visual understanding and generation tasks. Project page is at: \url{https://vargpt-1.github.io/}
Advancing General Multimodal Capability of Vision-language Models with Pyramid-descent Visual Position Encoding
Jan 19, 2025Vision-language Models (VLMs) have shown remarkable capabilities in advancing general artificial intelligence, yet the irrational encoding of visual positions persists in inhibiting the models' comprehensive perception performance across different levels of granularity. In this work, we propose Pyramid-descent Visual Position Encoding (PyPE), a novel approach designed to enhance the perception of visual tokens within VLMs. By assigning visual position indexes from the periphery to the center and expanding the central receptive field incrementally, PyPE addresses the limitations of traditional raster-scan methods and mitigates the long-term decay effects induced by Rotary Position Embedding (RoPE). Our method reduces the relative distance between interrelated visual elements and instruction tokens, promoting a more rational allocation of attention weights and allowing for a multi-granularity perception of visual elements and countering the over-reliance on anchor tokens. Extensive experimental evaluations demonstrate that PyPE consistently improves the general capabilities of VLMs across various sizes. Code is available at https://github.com/SakuraTroyChen/PyPE.