 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASK: Adaptive Self-improving Knowledge Framework for Audio Text Retrieval
Dec 11, 2025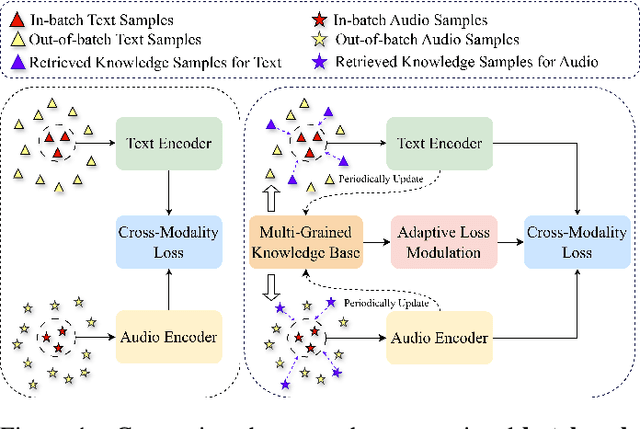
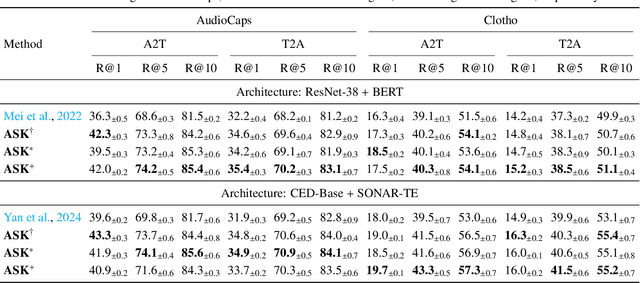
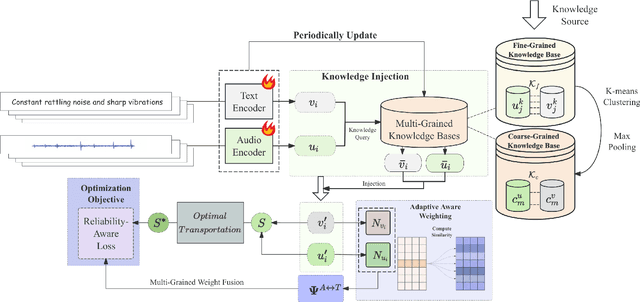
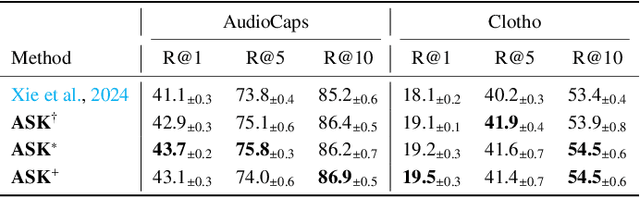
The dominant paradigm for Audio-Text Retrieval (ATR) relies on mini-batch-based contrastive learning. This process, however, is inherently limited by what we formalize as the Gradient Locality Bottleneck (GLB), which structurally prevents models from leveraging out-of-batch knowledge and thus impairs fine-grained and long-tail learning. While external knowledge-enhanced methods can alleviate the GLB, we identify a critical, unaddressed side effect: the Representation-Drift Mismatch (RDM), where a static knowledge base becomes progressively misaligned with the evolving model, turning guidance into noise. To address this dual challenge, we propose the Adaptive Self-improving Knowledge (ASK) framework, a model-agnostic, plug-and-play solution. ASK breaks the GLB via multi-grained knowledge injection, systematically mitigates RDM through dynamic knowledge refinement, and introduces a novel adaptive reliability weighting scheme to ensure consistent knowledge contributes to optimization. Experimental results on two benchmark datasets with superior, state-of-the-art performance justify the efficacy of our proposed ASK framework.
Not All Tokens and Heads Are Equally Important: Dual-Level Attention Intervention for Hallucination Mitigation
Jun 14, 2025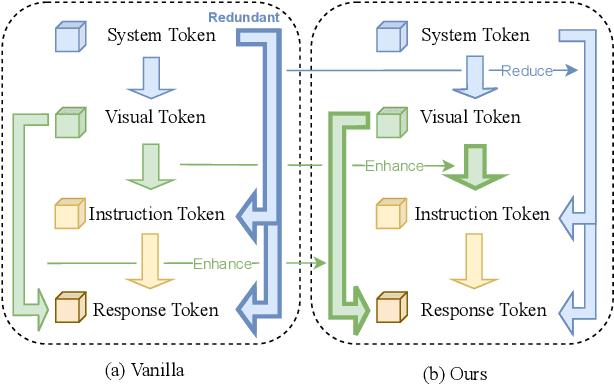
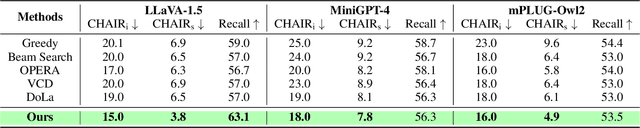
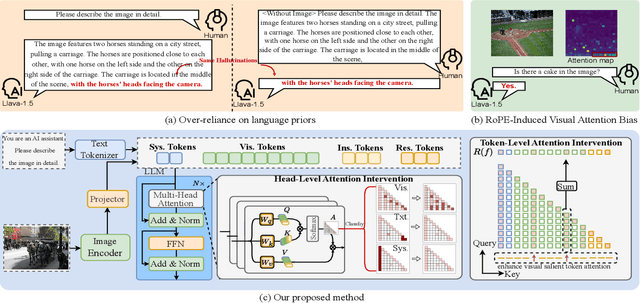

Large vision-language models (LVLMs) have shown remarkable capabilities across a wide range of multimodal tasks. However, they remain prone to visual hallucination (VH), often producing confident but incorrect descriptions of visual content. We present VisFlow, an efficient and training-free framework designed to mitigate VH by directly manipulating attention patterns during inference. Through systematic analysis, we identify three key pathological attention behaviors in LVLMs: (1) weak visual grounding, where attention to visual tokens is insufficient or misallocated, over-focusing on uninformative regions; (2) language prior dominance, where excessive attention to prior response tokens reinforces autoregressive patterns and impairs multimodal alignment; (3) prompt redundancy, where many attention heads fixate on system prompt tokens, disrupting the integration of image, instruction, and response content. To address these issues, we introduce two inference-time interventions: token-level attention intervention (TAI), which enhances focus on salient visual content, and head-level attention intervention (HAI), which suppresses over-attention to prompt and nearby text tokens. VisFlow operates without additional training or model modifications. Extensive experiments across models and benchmarks show that VisFlow effectively reduces hallucinations and improves visual factuality, with negligible computational cost.
ATRI: Mitigating Multilingual Audio Text Retrieval Inconsistencies by Reducing Data Distribution Errors
Feb 22, 2025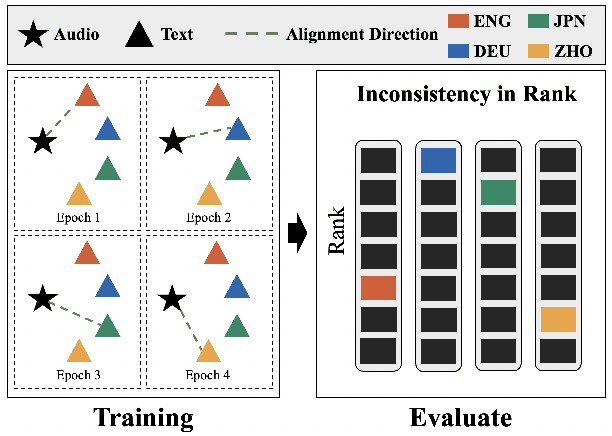
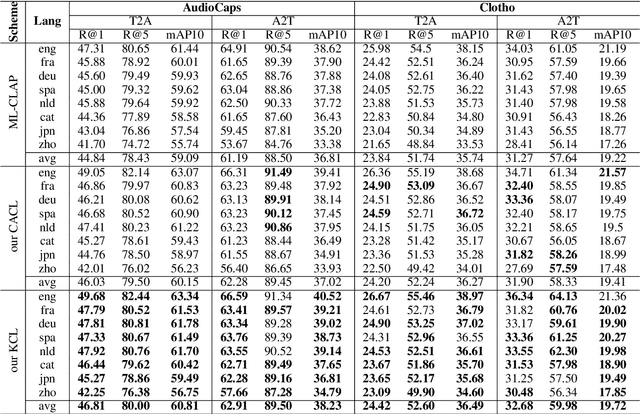
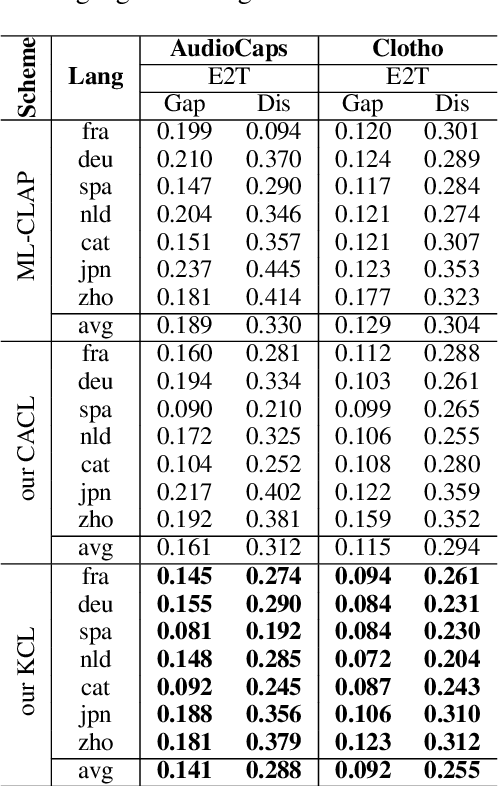
Multilingual audio-text retrieval (ML-ATR) is a challenging task that aims to retrieve audio clips or multilingual texts from databases. However, existing ML-ATR schemes suffer from inconsistencies for instance similarity matching across languages. We theoretically analyze the inconsistency in terms of both multilingual modal alignment direction error and weight error, and propose the theoretical weight error upper bound for quantifying the inconsistency. Based on the analysis of the weight error upper bound, we find that the inconsistency problem stems from the data distribution error caused by random sampling of languages. We propose a consistent ML-ATR scheme using 1-to-k contrastive learning and audio-English co-anchor contrastive learning, aiming to mitigate the negative impact of data distribution error on recall and consistency in ML-ATR. Experimental results on the translated AudioCaps and Clotho datasets show that our scheme achieves state-of-the-art performance on recall and consistency metrics for eight mainstream languages, including English. Our code will be available at https://github.com/ATRI-ACL/ATRI-ACL.
Do we really have to filter out random noise in pre-training data for language models?
Feb 10, 2025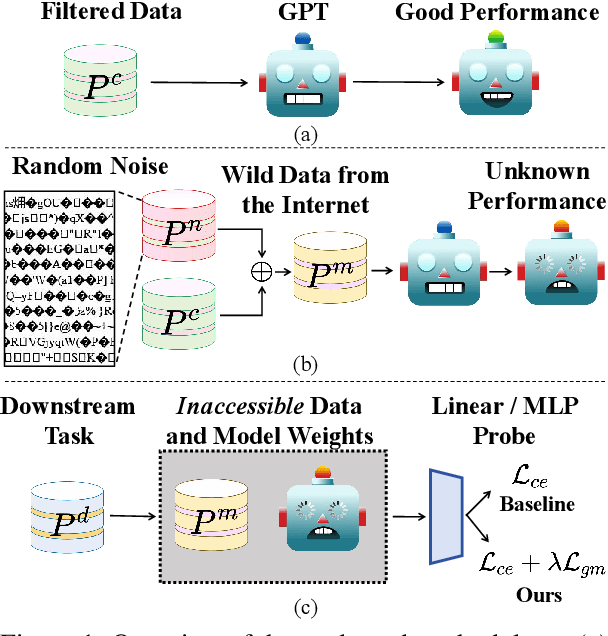



Web-scale pre-training datasets are the cornerstone of LLMs' success. However, text data curated from the internet inevitably contains random noise caused by decoding errors or unregulated web content. In contrast to previous works that focus on low quality or synthetic data, our study \textbf{provides the first systematic investigation into such random noise through a cohesive ``What-Why-How'' framework.} Surprisingly, we observed that the resulting increase in next-token prediction (NTP) loss was significantly lower than the proportion of random noise. We provide a theoretical justification for this phenomenon, which also elucidates the success of multilingual models. On the other hand, experiments show that the model's performance in downstream tasks is not based solely on the NTP loss, which means that random noise may result in degraded downstream performance. To address the potential adverse effects, we introduce a novel plug-and-play Local Gradient Matching loss, which explicitly enhances the denoising capability of the downstream task head by aligning the gradient of normal and perturbed features without requiring knowledge of the model's parameters. Additional experiments on 8 language and 14 vision benchmarks further validate its effectiveness.
VARGPT: Unified Understanding and Generation in a Visual Autoregressive Multimodal Large Language Model
Jan 21, 2025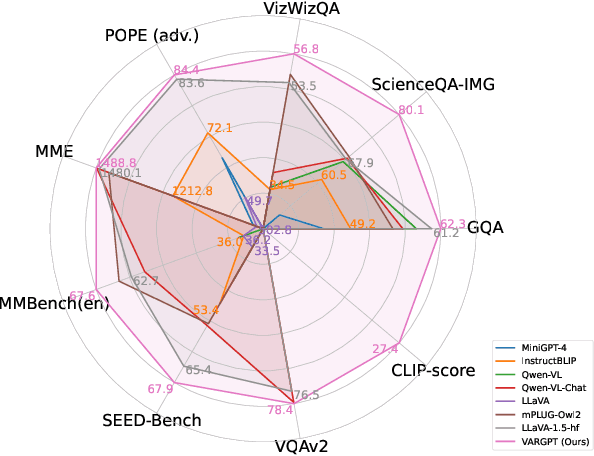
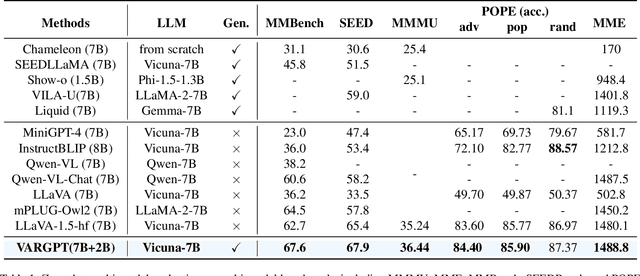

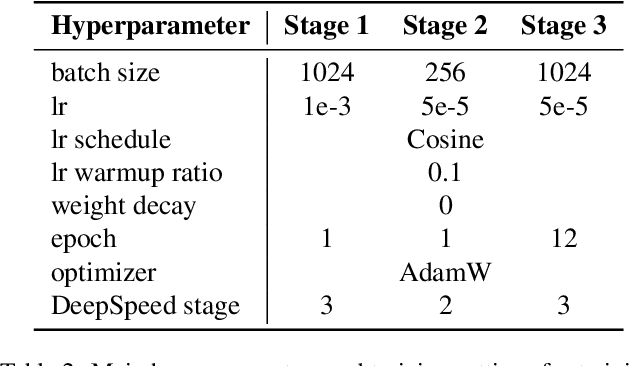
We present VARGPT, a novel multimodal large language model (MLLM) that unifies visual understanding and generation within a single autoregressive framework. VARGPT employs a next-token prediction paradigm for visual understanding and a next-scale prediction paradigm for visual autoregressive generation. VARGPT innovatively extends the LLaVA architecture, achieving efficient scale-wise autoregressive visual generation within MLLMs while seamlessly accommodating mixed-modal input and output within a single model framework. Our VARGPT undergoes a three-stage unified training process on specially curated datasets, comprising a pre-training phase and two mixed visual instruction-tuning phases. The unified training strategy are designed to achieve alignment between visual and textual features, enhance instruction following for both understanding and generation, and improve visual generation quality, respectively. Despite its LLAVA-based architecture for multimodel understanding, VARGPT significantly outperforms LLaVA-1.5 across various vision-centric benchmarks, such as visual question-answering and reasoning tasks. Notably, VARGPT naturally supports capabilities in autoregressive visual generation and instruction-to-image synthesis, showcasing its versatility in both visual understanding and generation tasks. Project page is at: \url{https://vargpt-1.github.io/}
VASparse: Towards Efficient Visual Hallucination Mitigation for Large Vision-Language Model via Visual-Aware Sparsification
Jan 11, 2025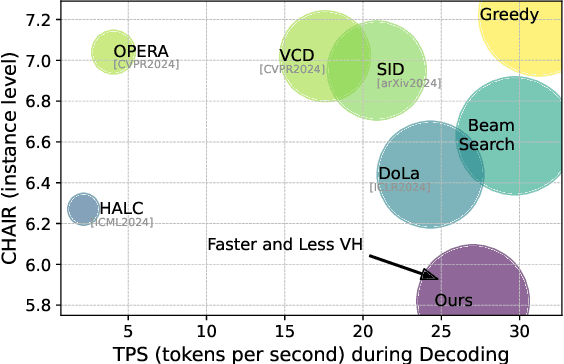



Large Vision-Language Models (LVLMs) may produce outputs that are unfaithful to reality, also known as visual hallucinations (VH), which significantly impedes their real-world usage. To alleviate VH, various decoding strategies have been proposed to enhance visual information. However, many of these methods may require secondary decoding and rollback, which significantly reduces inference speed. In this work, we propose an efficient plug-and-play decoding algorithm via Visual-Aware Sparsification (VASparse) from the perspective of token sparsity for mitigating VH. VASparse is inspired by empirical observations: (1) the sparse activation of attention in LVLMs, and (2) visual-agnostic tokens sparsification exacerbates VH. Based on these insights, we propose a novel token sparsification strategy that balances efficiency and trustworthiness. Specifically, VASparse implements a visual-aware token selection strategy during decoding to reduce redundant tokens while preserving visual context effectively. Additionally, we innovatively introduce a sparse-based visual contrastive decoding method to recalibrate the distribution of hallucinated outputs without the time overhead associated with secondary decoding. Subsequently, VASparse recalibrates attention scores to penalize attention sinking of LVLMs towards text tokens. Extensive experiments across four popular benchmarks confirm the effectiveness of VASparse in mitigating VH across different LVLM families without requiring additional training or post-processing. Impressively, VASparse achieves state-of-the-art performance for mitigating VH while maintaining competitive decoding speed. Code is available at https://github.com/mengchuang123/VASparse-github.
Uncertainty-aware sign language video retrieval with probability distribution modeling
May 30, 2024Sign language video retrieval plays a key role in facilitating information access for the deaf community. Despite significant advances in video-text retrieval, the complexity and inherent uncertainty of sign language preclude the direct application of these techniques. Previous methods achieve the mapping between sign language video and text through fine-grained modal alignment. However, due to the scarcity of fine-grained annotation, the uncertainty inherent in sign language video is underestimated, limiting the further development of sign language retrieval tasks. To address this challenge, we propose a novel Uncertainty-aware Probability Distribution Retrieval (UPRet), that conceptualizes the mapping process of sign language video and text in terms of probability distributions, explores their potential interrelationships, and enables flexible mappings. Experiments on three benchmarks demonstrate the effectiveness of our method, which achieves state-of-the-art results on How2Sign (59.1%), PHOENIX-2014T (72.0%), and CSL-Daily (78.4%).