 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConan-embedding-v3: Fusing Modality-Specific Models for Omni-Modal Embedding
Jun 08, 2026Omni-modal retrieval promises a single embedding space for text, image, video, document, and audio inputs, but building such a unified retriever is difficult since these modalities differ in data distribution, architecture, and optimization dynamics. In this work, we present Conan-embedding-v3, a decouple--fuse--recover framework for omni-modal retrieval. Conan-embedding-v3 first trains modality specialists independently and fuses their task vectors into a single dense backbone, a strategy we call Decoupled Specialist Fusion. We show that this fusion composes visual, video, and document retrieval capabilities, but also exposes a failure mode for projector-based modalities: when audio is attached through an external encoder and projector, fusing the backbone leaves the projector calibrated to the audio-specialist backbone, causing a large audio retrieval regression despite copying all audio-specific modules unchanged. We call this failure Projector Drift. To repair it, Conan-embedding-v3 applies Projector Recovery (i.e., full-parameter fine-tuning of the projector while keeping the backbone frozen) followed by balanced multi-modal rehearsal. The resulting model supports these retrieval pathways in one backbone, achieving 74.9 scores on MMEB while obtaining 55.61 on the 30-task MAEB audio suite.
APEX: Autonomous Policy Exploration for Self-Evolving LLM Agents
May 20, 2026LLM agents have shown strong performance across a wide range of complex tasks, including interactive environments that require long-horizon decision making. But these agents cannot learn on the fly at test time. Self-evolving agents address this by accumulating memory and reflection across episodes rather than requiring model-weight updates. However, these agents often suffer from exploration collapse: as memory grows, behavior concentrates around familiar high-reward routines, reducing the chance of discovering better alternatives. To address this problem, we propose Autonomous Policy EXploration (APEX), which builds and maintains an explicit strategy space through a strategy map-a directed acyclic graph of milestones with prerequisite dependency edges. In APEX, Fork Discovery expands the map with evidence-grounded unexplored directions, while Policy Selection balances exploration and exploitation during planning. Evaluated on nine Jericho text-adventure games and WebArena, a realistic web interaction benchmark, APEX outperforms all baselines. Extensive ablations validate each component's contribution and demonstrate robustness across diverse settings, demonstrating APEX's effectiveness for sustained exploration in self-evolving agents.
KLong: Training LLM Agent for Extremely Long-horizon Tasks
Feb 19, 2026This paper introduces KLong, an open-source LLM agent trained to solve extremely long-horizon tasks. The principle is to first cold-start the model via trajectory-splitting SFT, then scale it via progressive RL training. Specifically, we first activate basic agentic abilities of a base model with a comprehensive SFT recipe. Then, we introduce Research-Factory, an automated pipeline that generates high-quality training data by collecting research papers and constructing evaluation rubrics. Using this pipeline, we build thousands of long-horizon trajectories distilled from Claude 4.5 Sonnet (Thinking). To train with these extremely long trajectories, we propose a new trajectory-splitting SFT, which preserves early context, progressively truncates later context, and maintains overlap between sub-trajectories. In addition, to further improve long-horizon task-solving capability, we propose a novel progressive RL, which schedules training into multiple stages with progressively extended timeouts. Experiments demonstrate the superiority and generalization of KLong, as shown in Figure 1. Notably, our proposed KLong (106B) surpasses Kimi K2 Thinking (1T) by 11.28% on PaperBench, and the performance improvement generalizes to other coding benchmarks like SWE-bench Verified and MLE-bench.
EvoClinician: A Self-Evolving Agent for Multi-Turn Medical Diagnosis via Test-Time Evolutionary Learning
Jan 30, 2026Prevailing medical AI operates on an unrealistic ''one-shot'' model, diagnosing from a complete patient file. However, real-world diagnosis is an iterative inquiry where Clinicians sequentially ask questions and order tests to strategically gather information while managing cost and time. To address this, we first propose Med-Inquire, a new benchmark designed to evaluate an agent's ability to perform multi-turn diagnosis. Built upon a dataset of real-world clinical cases, Med-Inquire simulates the diagnostic process by hiding a complete patient file behind specialized Patient and Examination agents. They force the agent to proactively ask questions and order tests to gather information piece by piece. To tackle the challenges posed by Med-Inquire, we then introduce EvoClinician, a self-evolving agent that learns efficient diagnostic strategies at test time. Its core is a ''Diagnose-Grade-Evolve'' loop: an Actor agent attempts a diagnosis; a Process Grader agent performs credit assignment by evaluating each action for both clinical yield and resource efficiency; finally, an Evolver agent uses this feedback to update the Actor's strategy by evolving its prompt and memory. Our experiments show EvoClinician outperforms continual learning baselines and other self-evolving agents like memory agents. The code is available at https://github.com/yf-he/EvoClinician
Collaborative Multi-Agent Test-Time Reinforcement Learning for Reasoning
Jan 15, 2026Multi-agent systems have evolved into practical LLM-driven collaborators for many applications, gaining robustness from diversity and cross-checking. However, multi-agent RL (MARL) training is resource-intensive and unstable: co-adapting teammates induce non-stationarity, and rewards are often sparse and high-variance. Therefore, we introduce \textbf{Multi-Agent Test-Time Reinforcement Learning (MATTRL)}, a framework that injects structured textual experience into multi-agent deliberation at inference time. MATTRL forms a multi-expert team of specialists for multi-turn discussions, retrieves and integrates test-time experiences, and reaches consensus for final decision-making. We also study credit assignment for constructing a turn-level experience pool, then reinjecting it into the dialogue. Across challenging benchmarks in medicine, math, and education, MATTRL improves accuracy by an average of 3.67\% over a multi-agent baseline, and by 8.67\% over comparable single-agent baselines. Ablation studies examine different credit-assignment schemes and provide a detailed comparison of how they affect training outcomes. MATTRL offers a stable, effective and efficient path to distribution-shift-robust multi-agent reasoning without tuning.
Rewarding the Rare: Uniqueness-Aware RL for Creative Problem Solving in LLMs
Jan 13, 2026Reinforcement learning (RL) has become a central paradigm for post-training large language models (LLMs), particularly for complex reasoning tasks, yet it often suffers from exploration collapse: policies prematurely concentrate on a small set of dominant reasoning patterns, improving pass@1 while limiting rollout-level diversity and gains in pass@k. We argue that this failure stems from regularizing local token behavior rather than diversity over sets of solutions. To address this, we propose Uniqueness-Aware Reinforcement Learning, a rollout-level objective that explicitly rewards correct solutions that exhibit rare high-level strategies. Our method uses an LLM-based judge to cluster rollouts for the same problem according to their high-level solution strategies, ignoring superficial variations, and reweights policy advantages inversely with cluster size. As a result, correct but novel strategies receive higher rewards than redundant ones. Across mathematics, physics, and medical reasoning benchmarks, our approach consistently improves pass@$k$ across large sampling budgets and increases the area under the pass@$k$ curve (AUC@$K$) without sacrificing pass@1, while sustaining exploration and uncovering more diverse solution strategies at scale.
Image Aesthetic Reasoning via HCM-GRPO: Empowering Compact Model for Superior Performance
Nov 13, 2025The performance of image generation has been significantly improved in recent years. However, the study of image screening is rare and its performance with Multimodal Large Language Models (MLLMs) is unsatisfactory due to the lack of data and the weak image aesthetic reasoning ability in MLLMs. In this work, we propose a complete solution to address these problems in terms of data and methodology. For data, we collect a comprehensive image screening dataset with over 128k samples, about 640k images. Each sample consists of an original image, four generated images. The dataset evaluates the image aesthetic reasoning ability under four aspects: appearance deformation, physical shadow, placement layout, and extension rationality. Regarding data annotation, we investigate multiple approaches, including purely manual, fully automated, and answer-driven annotations, to acquire high-quality chains of thought (CoT) data in the most cost-effective manner. Methodologically, we introduce a Hard Cases Mining (HCM) strategy with a Dynamic Proportional Accuracy (DPA) reward into the Group Relative Policy Optimization (GRPO) framework, called HCM-GRPO. This enhanced method demonstrates superior image aesthetic reasoning capabilities compared to the original GRPO. Our experimental results reveal that even state-of-the-art closed-source MLLMs, such as GPT4o and Qwen-VL-Max, exhibit performance akin to random guessing in image aesthetic reasoning. In contrast, by leveraging the HCM-GRPO, we are able to surpass the scores of both large-scale open-source and leading closed-source models with a much smaller model.
Undersampled Phase Retrieval with Image Priors
Sep 18, 2025Phase retrieval seeks to recover a complex signal from amplitude-only measurements, a challenging nonlinear inverse problem. Current theory and algorithms often ignore signal priors. By contrast, we evaluate here a variety of image priors in the context of severe undersampling with structured random Fourier measurements. Our results show that those priors significantly improve reconstruction, allowing accurate reconstruction even below the weak recovery threshold.
Not All Tokens and Heads Are Equally Important: Dual-Level Attention Intervention for Hallucination Mitigation
Jun 14, 2025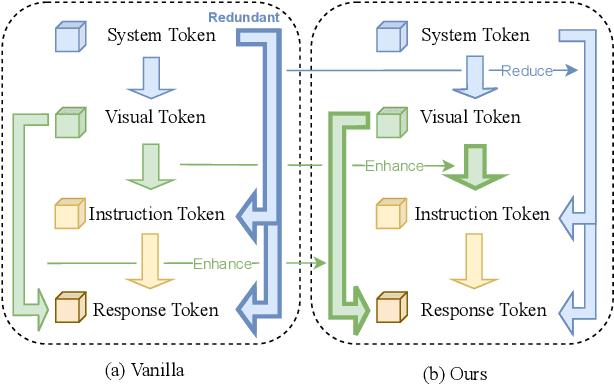
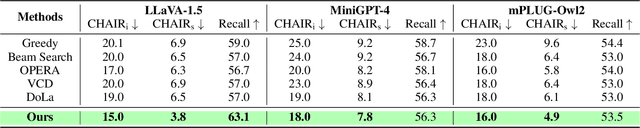
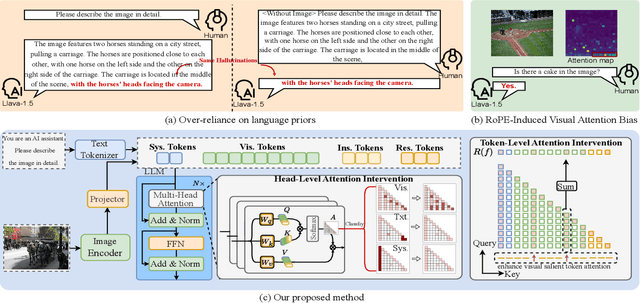

Large vision-language models (LVLMs) have shown remarkable capabilities across a wide range of multimodal tasks. However, they remain prone to visual hallucination (VH), often producing confident but incorrect descriptions of visual content. We present VisFlow, an efficient and training-free framework designed to mitigate VH by directly manipulating attention patterns during inference. Through systematic analysis, we identify three key pathological attention behaviors in LVLMs: (1) weak visual grounding, where attention to visual tokens is insufficient or misallocated, over-focusing on uninformative regions; (2) language prior dominance, where excessive attention to prior response tokens reinforces autoregressive patterns and impairs multimodal alignment; (3) prompt redundancy, where many attention heads fixate on system prompt tokens, disrupting the integration of image, instruction, and response content. To address these issues, we introduce two inference-time interventions: token-level attention intervention (TAI), which enhances focus on salient visual content, and head-level attention intervention (HAI), which suppresses over-attention to prompt and nearby text tokens. VisFlow operates without additional training or model modifications. Extensive experiments across models and benchmarks show that VisFlow effectively reduces hallucinations and improves visual factuality, with negligible computational cost.
BehaviorSFT: Behavioral Token Conditioning for Clinical Agents Across the Proactivity Spectrum
May 27, 2025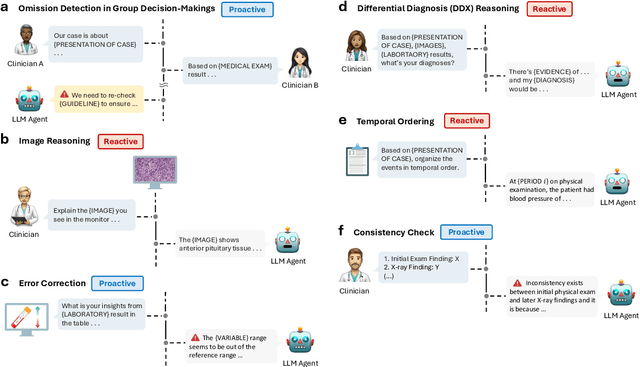
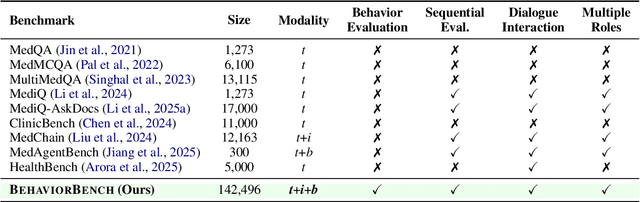
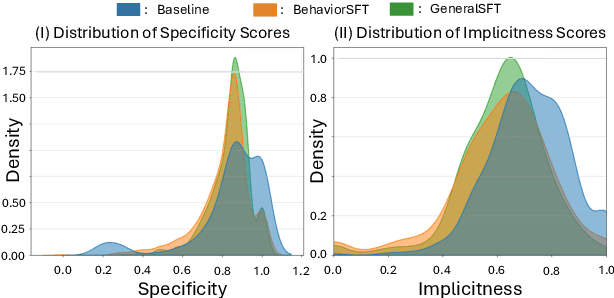
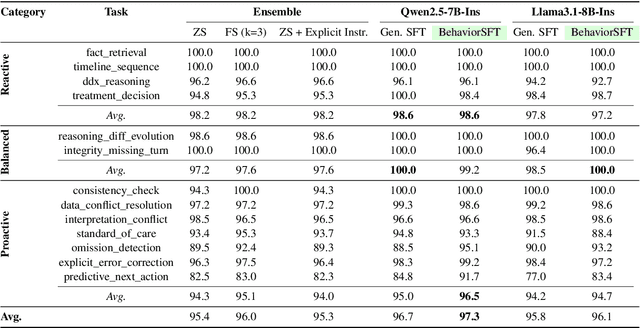
Large Language Models (LLMs) as clinical agents require careful behavioral adaptation. While adept at reactive tasks (e.g., diagnosis reasoning), LLMs often struggle with proactive engagement, like unprompted identification of critical missing information or risks. We introduce BehaviorBench, a comprehensive dataset to evaluate agent behaviors across a clinical assistance spectrum, ranging from reactive query responses to proactive interventions (e.g., clarifying ambiguities, flagging overlooked critical data). Our BehaviorBench experiments reveal LLMs' inconsistent proactivity. To address this, we propose BehaviorSFT, a novel training strategy using behavioral tokens to explicitly condition LLMs for dynamic behavioral selection along this spectrum. BehaviorSFT boosts performance, achieving up to 97.3% overall Macro F1 on BehaviorBench and improving proactive task scores (e.g., from 95.0% to 96.5% for Qwen2.5-7B-Ins). Crucially, blind clinician evaluations confirmed BehaviorSFT-trained agents exhibit more realistic clinical behavior, striking a superior balance between helpful proactivity (e.g., timely, relevant suggestions) and necessary restraint (e.g., avoiding over-intervention) versus standard fine-tuning or explicit instructed agents.