 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiveMathematicianBench: A Live Benchmark for Mathematician-Level Reasoning with Proof Sketches
Apr 02, 2026Mathematical reasoning is a hallmark of human intelligence, and whether large language models (LLMs) can meaningfully perform it remains a central question in artificial intelligence and cognitive science. As LLMs are increasingly integrated into scientific workflows, rigorous evaluation of their mathematical capabilities becomes a practical necessity. Existing benchmarks are limited by synthetic settings and data contamination. We present LiveMathematicianBench, a dynamic multiple-choice benchmark for research-level mathematical reasoning built from recent arXiv papers published after model training cutoffs. By grounding evaluation in newly published theorems, it provides a realistic testbed beyond memorized patterns. The benchmark introduces a thirteen-category logical taxonomy of theorem types (e.g., implication, equivalence, existence, uniqueness), enabling fine-grained evaluation across reasoning forms. It employs a proof-sketch-guided distractor pipeline that uses high-level proof strategies to construct plausible but invalid answer choices reflecting misleading proof directions, increasing sensitivity to genuine understanding over surface-level matching. We also introduce a substitution-resistant mechanism to distinguish answer recognition from substantive reasoning. Evaluation shows the benchmark is far from saturated: Gemini-3.1-pro-preview, the best model, achieves only 43.5%. Under substitution-resistant evaluation, accuracy drops sharply: GPT-5.4 scores highest at 30.6%, while Gemini-3.1-pro-preview falls to 17.6%, below the 20% random baseline. A dual-mode protocol reveals that proof-sketch access yields consistent accuracy gains, suggesting models can leverage high-level proof strategies for reasoning. Overall, LiveMathematicianBench offers a scalable, contamination-resistant testbed for studying research-level mathematical reasoning in LLMs.
Self-Hinting Language Models Enhance Reinforcement Learning
Feb 03, 2026Group Relative Policy Optimization (GRPO) has recently emerged as a practical recipe for aligning large language models with verifiable objectives. However, under sparse terminal rewards, GRPO often stalls because rollouts within a group frequently receive identical rewards, causing relative advantages to collapse and updates to vanish. We propose self-hint aligned GRPO with privileged supervision (SAGE), an on-policy reinforcement learning framework that injects privileged hints during training to reshape the rollout distribution under the same terminal verifier reward. For each prompt $x$, the model samples a compact hint $h$ (e.g., a plan or decomposition) and then generates a solution $τ$ conditioned on $(x,h)$. Crucially, the task reward $R(x,τ)$ is unchanged; hints only increase within-group outcome diversity under finite sampling, preventing GRPO advantages from collapsing under sparse rewards. At test time, we set $h=\varnothing$ and deploy the no-hint policy without any privileged information. Moreover, sampling diverse self-hints serves as an adaptive curriculum that tracks the learner's bottlenecks more effectively than fixed hints from an initial policy or a stronger external model. Experiments over 6 benchmarks with 3 LLMs show that SAGE consistently outperforms GRPO, on average +2.0 on Llama-3.2-3B-Instruct, +1.2 on Qwen2.5-7B-Instruct and +1.3 on Qwen3-4B-Instruct. The code is available at https://github.com/BaohaoLiao/SAGE.
Reinforce-Ada: An Adaptive Sampling Framework for Reinforce-Style LLM Training
Oct 06, 2025Reinforcement learning applied to large language models (LLMs) for reasoning tasks is often bottlenecked by unstable gradient estimates due to fixed and uniform sampling of responses across prompts. Prior work such as GVM-RAFT addresses this by dynamically allocating inference budget per prompt to minimize stochastic gradient variance under a budget constraint. Inspired by this insight, we propose Reinforce-Ada, an adaptive sampling framework for online RL post-training of LLMs that continuously reallocates sampling effort to the prompts with the greatest uncertainty or learning potential. Unlike conventional two-stage allocation methods, Reinforce-Ada interleaves estimation and sampling in an online successive elimination process, and automatically stops sampling for a prompt once sufficient signal is collected. To stabilize updates, we form fixed-size groups with enforced reward diversity and compute advantage baselines using global statistics aggregated over the adaptive sampling phase. Empirical results across multiple model architectures and reasoning benchmarks show that Reinforce-Ada accelerates convergence and improves final performance compared to GRPO, especially when using the balanced sampling variant. Our work highlights the central role of variance-aware, adaptive data curation in enabling efficient and reliable reinforcement learning for reasoning-capable LLMs. Code is available at https://github.com/RLHFlow/Reinforce-Ada.
Almost Linear Convergence under Minimal Score Assumptions: Quantized Transition Diffusion
May 28, 2025Continuous diffusion models have demonstrated remarkable performance in data generation across various domains, yet their efficiency remains constrained by two critical limitations: (1) the local adjacency structure of the forward Markov process, which restricts long-range transitions in the data space, and (2) inherent biases introduced during the simulation of time-inhomogeneous reverse denoising processes. To address these challenges, we propose Quantized Transition Diffusion (QTD), a novel approach that integrates data quantization with discrete diffusion dynamics. Our method first transforms the continuous data distribution $p_*$ into a discrete one $q_*$ via histogram approximation and binary encoding, enabling efficient representation in a structured discrete latent space. We then design a continuous-time Markov chain (CTMC) with Hamming distance-based transitions as the forward process, which inherently supports long-range movements in the original data space. For reverse-time sampling, we introduce a \textit{truncated uniformization} technique to simulate the reverse CTMC, which can provably provide unbiased generation from $q_*$ under minimal score assumptions. Through a novel KL dynamic analysis of the reverse CTMC, we prove that QTD can generate samples with $O(d\ln^2(d/\epsilon))$ score evaluations in expectation to approximate the $d$--dimensional target distribution $p_*$ within an $\epsilon$ error tolerance. Our method not only establishes state-of-the-art inference efficiency but also advances the theoretical foundations of diffusion-based generative modeling by unifying discrete and continuous diffusion paradigms.
Fractured Chain-of-Thought Reasoning
May 19, 2025Inference-time scaling techniques have significantly bolstered the reasoning capabilities of large language models (LLMs) by harnessing additional computational effort at inference without retraining. Similarly, Chain-of-Thought (CoT) prompting and its extension, Long CoT, improve accuracy by generating rich intermediate reasoning trajectories, but these approaches incur substantial token costs that impede their deployment in latency-sensitive settings. In this work, we first show that truncated CoT, which stops reasoning before completion and directly generates the final answer, often matches full CoT sampling while using dramatically fewer tokens. Building on this insight, we introduce Fractured Sampling, a unified inference-time strategy that interpolates between full CoT and solution-only sampling along three orthogonal axes: (1) the number of reasoning trajectories, (2) the number of final solutions per trajectory, and (3) the depth at which reasoning traces are truncated. Through extensive experiments on five diverse reasoning benchmarks and several model scales, we demonstrate that Fractured Sampling consistently achieves superior accuracy-cost trade-offs, yielding steep log-linear scaling gains in Pass@k versus token budget. Our analysis reveals how to allocate computation across these dimensions to maximize performance, paving the way for more efficient and scalable LLM reasoning.
Beyond 'Aha!': Toward Systematic Meta-Abilities Alignment in Large Reasoning Models
May 15, 2025Large reasoning models (LRMs) already possess a latent capacity for long chain-of-thought reasoning. Prior work has shown that outcome-based reinforcement learning (RL) can incidentally elicit advanced reasoning behaviors such as self-correction, backtracking, and verification phenomena often referred to as the model's "aha moment". However, the timing and consistency of these emergent behaviors remain unpredictable and uncontrollable, limiting the scalability and reliability of LRMs' reasoning capabilities. To address these limitations, we move beyond reliance on prompts and coincidental "aha moments". Instead, we explicitly align models with three meta-abilities: deduction, induction, and abduction, using automatically generated, self-verifiable tasks. Our three stage-pipeline individual alignment, parameter-space merging, and domain-specific reinforcement learning, boosting performance by over 10\% relative to instruction-tuned baselines. Furthermore, domain-specific RL from the aligned checkpoint yields an additional 2\% average gain in the performance ceiling across math, coding, and science benchmarks, demonstrating that explicit meta-ability alignment offers a scalable and dependable foundation for reasoning. Code is available at: https://github.com/zhiyuanhubj/Meta-Ability-Alignment
Scalable Chain of Thoughts via Elastic Reasoning
May 08, 2025Large reasoning models (LRMs) have achieved remarkable progress on complex tasks by generating extended chains of thought (CoT). However, their uncontrolled output lengths pose significant challenges for real-world deployment, where inference-time budgets on tokens, latency, or compute are strictly constrained. We propose Elastic Reasoning, a novel framework for scalable chain of thoughts that explicitly separates reasoning into two phases--thinking and solution--with independently allocated budgets. At test time, Elastic Reasoning prioritize that completeness of solution segments, significantly improving reliability under tight resource constraints. To train models that are robust to truncated thinking, we introduce a lightweight budget-constrained rollout strategy, integrated into GRPO, which teaches the model to reason adaptively when the thinking process is cut short and generalizes effectively to unseen budget constraints without additional training. Empirical results on mathematical (AIME, MATH500) and programming (LiveCodeBench, Codeforces) benchmarks demonstrate that Elastic Reasoning performs robustly under strict budget constraints, while incurring significantly lower training cost than baseline methods. Remarkably, our approach also produces more concise and efficient reasoning even in unconstrained settings. Elastic Reasoning offers a principled and practical solution to the pressing challenge of controllable reasoning at scale.
Optimizing Chain-of-Thought Reasoners via Gradient Variance Minimization in Rejection Sampling and RL
May 05, 2025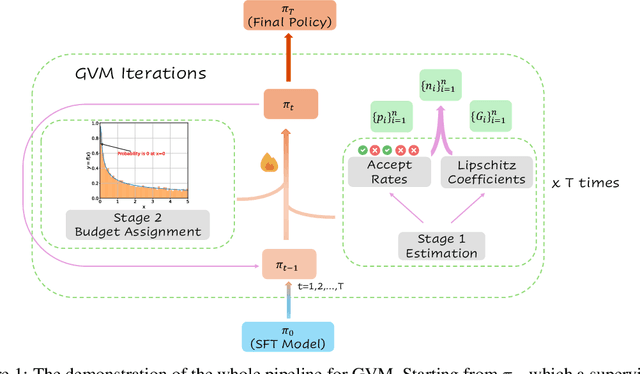
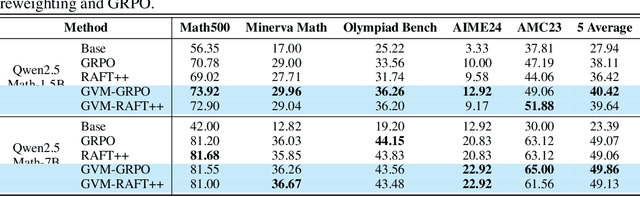
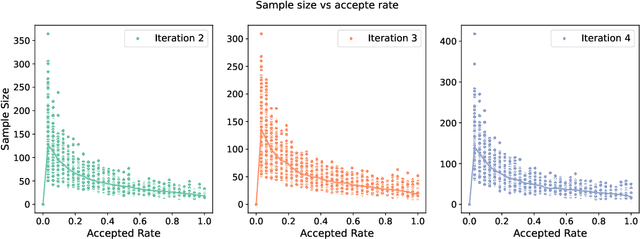
Chain-of-thought (CoT) reasoning in large language models (LLMs) can be formalized as a latent variable problem, where the model needs to generate intermediate reasoning steps. While prior approaches such as iterative reward-ranked fine-tuning (RAFT) have relied on such formulations, they typically apply uniform inference budgets across prompts, which fails to account for variability in difficulty and convergence behavior. This work identifies the main bottleneck in CoT training as inefficient stochastic gradient estimation due to static sampling strategies. We propose GVM-RAFT, a prompt-specific Dynamic Sample Allocation Strategy designed to minimize stochastic gradient variance under a computational budget constraint. The method dynamically allocates computational resources by monitoring prompt acceptance rates and stochastic gradient norms, ensuring that the resulting gradient variance is minimized. Our theoretical analysis shows that the proposed dynamic sampling strategy leads to accelerated convergence guarantees under suitable conditions. Experiments on mathematical reasoning show that GVM-RAFT achieves a 2-4x speedup and considerable accuracy improvements over vanilla RAFT. The proposed dynamic sampling strategy is general and can be incorporated into other reinforcement learning algorithms, such as GRPO, leading to similar improvements in convergence and test accuracy. Our code is available at https://github.com/RLHFlow/GVM.
A Minimalist Approach to LLM Reasoning: from Rejection Sampling to Reinforce
Apr 15, 2025



Reinforcement learning (RL) has become a prevailing approach for fine-tuning large language models (LLMs) on complex reasoning tasks. Among recent methods, GRPO stands out for its empirical success in training models such as DeepSeek-R1, yet the sources of its effectiveness remain poorly understood. In this work, we revisit GRPO from a reinforce-like algorithm perspective and analyze its core components. Surprisingly, we find that a simple rejection sampling baseline, RAFT, which trains only on positively rewarded samples, yields competitive performance than GRPO and PPO. Our ablation studies reveal that GRPO's main advantage arises from discarding prompts with entirely incorrect responses, rather than from its reward normalization. Motivated by this insight, we propose Reinforce-Rej, a minimal extension of policy gradient that filters both entirely incorrect and entirely correct samples. Reinforce-Rej improves KL efficiency and stability, serving as a lightweight yet effective alternative to more complex RL algorithms. We advocate RAFT as a robust and interpretable baseline, and suggest that future advances should focus on more principled designs for incorporating negative samples, rather than relying on them indiscriminately. Our findings provide guidance for future work in reward-based LLM post-training.
Reward Models Identify Consistency, Not Causality
Feb 20, 2025Reward models (RMs) play a crucial role in aligning large language models (LLMs) with human preferences and enhancing reasoning quality. Traditionally, RMs are trained to rank candidate outputs based on their correctness and coherence. However, in this work, we present several surprising findings that challenge common assumptions about RM behavior. Our analysis reveals that state-of-the-art reward models prioritize structural consistency over causal correctness. Specifically, removing the problem statement has minimal impact on reward scores, whereas altering numerical values or disrupting the reasoning flow significantly affects RM outputs. Furthermore, RMs exhibit a strong dependence on complete reasoning trajectories truncated or incomplete steps lead to significant variations in reward assignments, indicating that RMs primarily rely on learned reasoning patterns rather than explicit problem comprehension. These findings hold across multiple architectures, datasets, and tasks, leading to three key insights: (1) RMs primarily assess coherence rather than true reasoning quality; (2) The role of explicit problem comprehension in reward assignment is overstated; (3) Current RMs may be more effective at ranking responses than verifying logical validity. Our results suggest a fundamental limitation in existing reward modeling approaches, emphasizing the need for a shift toward causality-aware reward models that go beyond consistency-driven evaluation.