 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCP-Universe: Benchmarking Large Language Models with Real-World Model Context Protocol Servers
Aug 20, 2025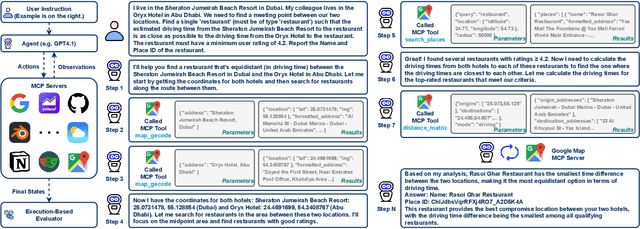
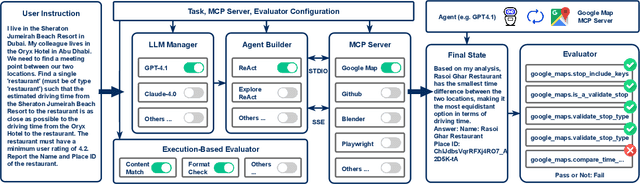
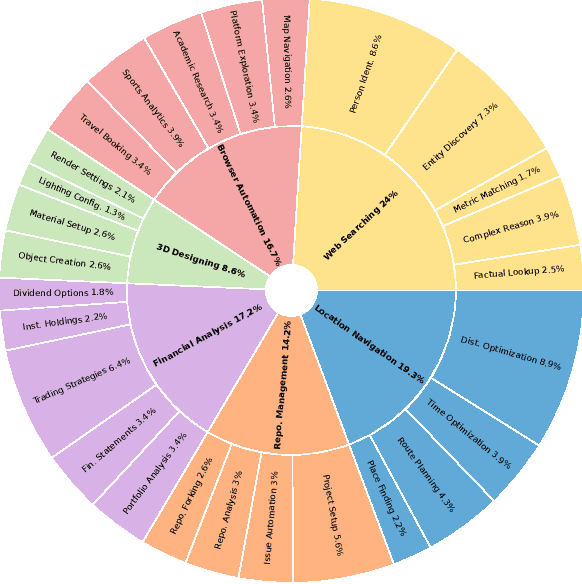
The Model Context Protocol has emerged as a transformative standard for connecting large language models to external data sources and tools, rapidly gaining adoption across major AI providers and development platforms. However, existing benchmarks are overly simplistic and fail to capture real application challenges such as long-horizon reasoning and large, unfamiliar tool spaces. To address this critical gap, we introduce MCP-Universe, the first comprehensive benchmark specifically designed to evaluate LLMs in realistic and hard tasks through interaction with real-world MCP servers. Our benchmark encompasses 6 core domains spanning 11 different MCP servers: Location Navigation, Repository Management, Financial Analysis, 3D Design, Browser Automation, and Web Searching. To ensure rigorous evaluation, we implement execution-based evaluators, including format evaluators for agent format compliance, static evaluators for time-invariant content matching, and dynamic evaluators that automatically retrieve real-time ground truth for temporally sensitive tasks. Through extensive evaluation of leading LLMs, we find that even SOTA models such as GPT-5 (43.72%), Grok-4 (33.33%) and Claude-4.0-Sonnet (29.44%) exhibit significant performance limitations. In addition, our benchmark poses a significant long-context challenge for LLM agents, as the number of input tokens increases rapidly with the number of interaction steps. Moreover, it introduces an unknown-tools challenge, as LLM agents often lack familiarity with the precise usage of the MCP servers. Notably, enterprise-level agents like Cursor cannot achieve better performance than standard ReAct frameworks. Beyond evaluation, we open-source our extensible evaluation framework with UI support, enabling researchers and practitioners to seamlessly integrate new agents and MCP servers while fostering innovation in the rapidly evolving MCP ecosystem.
Beyond 'Aha!': Toward Systematic Meta-Abilities Alignment in Large Reasoning Models
May 15, 2025Large reasoning models (LRMs) already possess a latent capacity for long chain-of-thought reasoning. Prior work has shown that outcome-based reinforcement learning (RL) can incidentally elicit advanced reasoning behaviors such as self-correction, backtracking, and verification phenomena often referred to as the model's "aha moment". However, the timing and consistency of these emergent behaviors remain unpredictable and uncontrollable, limiting the scalability and reliability of LRMs' reasoning capabilities. To address these limitations, we move beyond reliance on prompts and coincidental "aha moments". Instead, we explicitly align models with three meta-abilities: deduction, induction, and abduction, using automatically generated, self-verifiable tasks. Our three stage-pipeline individual alignment, parameter-space merging, and domain-specific reinforcement learning, boosting performance by over 10\% relative to instruction-tuned baselines. Furthermore, domain-specific RL from the aligned checkpoint yields an additional 2\% average gain in the performance ceiling across math, coding, and science benchmarks, demonstrating that explicit meta-ability alignment offers a scalable and dependable foundation for reasoning. Code is available at: https://github.com/zhiyuanhubj/Meta-Ability-Alignment
Aguvis: Unified Pure Vision Agents for Autonomous GUI Interaction
Dec 05, 2024



Graphical User Interfaces (GUIs) are critical to human-computer interaction, yet automating GUI tasks remains challenging due to the complexity and variability of visual environments. Existing approaches often rely on textual representations of GUIs, which introduce limitations in generalization, efficiency, and scalability. In this paper, we introduce Aguvis, a unified pure vision-based framework for autonomous GUI agents that operates across various platforms. Our approach leverages image-based observations, and grounding instructions in natural language to visual elements, and employs a consistent action space to ensure cross-platform generalization. To address the limitations of previous work, we integrate explicit planning and reasoning within the model, enhancing its ability to autonomously navigate and interact with complex digital environments. We construct a large-scale dataset of GUI agent trajectories, incorporating multimodal reasoning and grounding, and employ a two-stage training pipeline that first focuses on general GUI grounding, followed by planning and reasoning. Through comprehensive experiments, we demonstrate that Aguvis surpasses previous state-of-the-art methods in both offline and real-world online scenarios, achieving, to our knowledge, the first fully autonomous pure vision GUI agent capable of performing tasks independently without collaboration with external closed-source models. We open-sourced all datasets, models, and training recipes to facilitate future research at https://aguvis-project.github.io/.
XForecast: Evaluating Natural Language Explanations for Time Series Forecasting
Oct 21, 2024
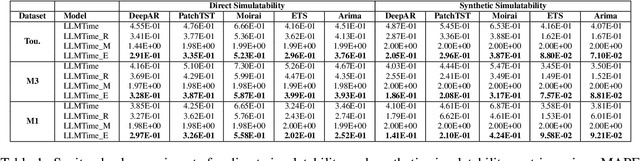
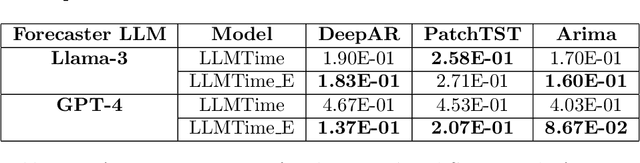
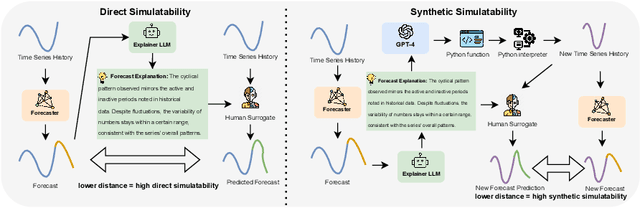
Time series forecasting aids decision-making, especially for stakeholders who rely on accurate predictions, making it very important to understand and explain these models to ensure informed decisions. Traditional explainable AI (XAI) methods, which underline feature or temporal importance, often require expert knowledge. In contrast, natural language explanations (NLEs) are more accessible to laypeople. However, evaluating forecast NLEs is difficult due to the complex causal relationships in time series data. To address this, we introduce two new performance metrics based on simulatability, assessing how well a human surrogate can predict model forecasts using the explanations. Experiments show these metrics differentiate good from poor explanations and align with human judgments. Utilizing these metrics, we further evaluate the ability of state-of-the-art large language models (LLMs) to generate explanations for time series data, finding that numerical reasoning, rather than model size, is the main factor influencing explanation quality.
Automatic Curriculum Expert Iteration for Reliable LLM Reasoning
Oct 10, 2024



Hallucinations (i.e., generating plausible but inaccurate content) and laziness (i.e. excessive refusals or defaulting to "I don't know") persist as major challenges in LLM reasoning. Current efforts to reduce hallucinations primarily focus on factual errors in knowledge-grounded tasks, often neglecting hallucinations related to faulty reasoning. Meanwhile, some approaches render LLMs overly conservative, limiting their problem-solving capabilities. To mitigate hallucination and laziness in reasoning tasks, we propose Automatic Curriculum Expert Iteration (Auto-CEI) to enhance LLM reasoning and align responses to the model's capabilities--assertively answering within its limits and declining when tasks exceed them. In our method, Expert Iteration explores the reasoning trajectories near the LLM policy, guiding incorrect paths back on track to reduce compounding errors and improve robustness; it also promotes appropriate "I don't know" responses after sufficient reasoning attempts. The curriculum automatically adjusts rewards, incentivizing extended reasoning before acknowledging incapability, thereby pushing the limits of LLM reasoning and aligning its behaviour with these limits. We compare Auto-CEI with various SOTA baselines across logical reasoning, mathematics, and planning tasks, where Auto-CEI achieves superior alignment by effectively balancing assertiveness and conservativeness.
MathHay: An Automated Benchmark for Long-Context Mathematical Reasoning in LLMs
Oct 07, 2024



Recent large language models (LLMs) have demonstrated versatile capabilities in long-context scenarios. Although some recent benchmarks have been developed to evaluate the long-context capabilities of LLMs, there is a lack of benchmarks evaluating the mathematical reasoning abilities of LLMs over long contexts, which is crucial for LLMs' application in real-world scenarios. In this paper, we introduce MathHay, an automated benchmark designed to assess the long-context mathematical reasoning capabilities of LLMs. Unlike previous benchmarks like Needle in a Haystack, which focus primarily on information retrieval within long texts, MathHay demands models with both information-seeking and complex mathematical reasoning abilities. We conduct extensive experiments on MathHay to assess the long-context mathematical reasoning abilities of eight top-performing LLMs. Even the best-performing model, Gemini-1.5-Pro-002, still struggles with mathematical reasoning over long contexts, achieving only 51.26% accuracy at 128K tokens. This highlights the significant room for improvement on the MathHay benchmark.
ThinK: Thinner Key Cache by Query-Driven Pruning
Jul 30, 2024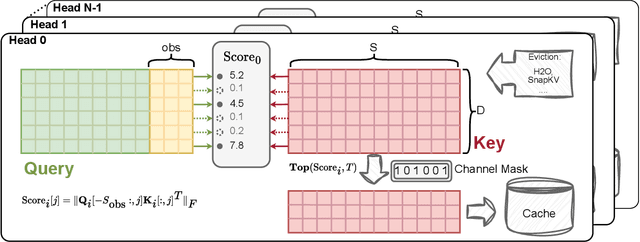
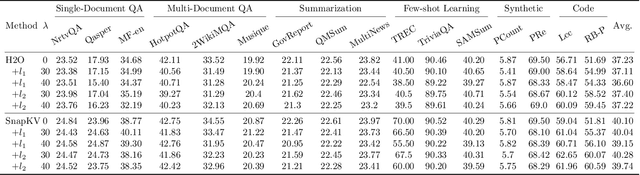
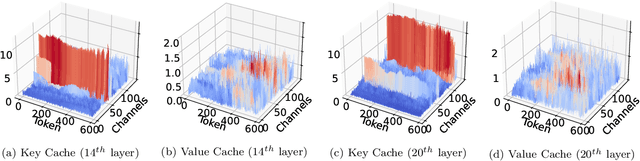
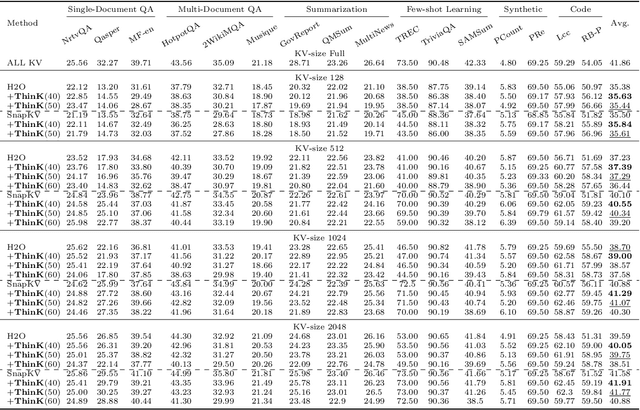
Large Language Models (LLMs) have revolutionized the field of natural language processing, achieving unprecedented performance across a variety of applications by leveraging increased model sizes and sequence lengths. However, the associated rise in computational and memory costs poses significant challenges, particularly in managing long sequences due to the quadratic complexity of the transformer attention mechanism. This paper focuses on the long-context scenario, addressing the inefficiencies in KV cache memory consumption during inference. Unlike existing approaches that optimize the memory based on the sequence lengths, we uncover that the channel dimension of the KV cache exhibits significant redundancy, characterized by unbalanced magnitude distribution and low-rank structure in attention weights. Based on these observations, we propose ThinK, a novel query-dependent KV cache pruning method designed to minimize attention weight loss while selectively pruning the least significant channels. Our approach not only maintains or enhances model accuracy but also achieves a reduction in memory costs by over 20% compared with vanilla KV cache eviction methods. Extensive evaluations on the LLaMA3 and Mistral models across various long-sequence datasets confirm the efficacy of ThinK, setting a new precedent for efficient LLM deployment without compromising performance. We also outline the potential of extending our method to value cache pruning, demonstrating ThinK's versatility and broad applicability in reducing both memory and computational overheads.
Personalised Distillation: Empowering Open-Sourced LLMs with Adaptive Learning for Code Generation
Oct 28, 2023



With the rise of powerful closed-sourced LLMs (ChatGPT, GPT-4), there are increasing interests in distilling the capabilies of close-sourced LLMs to smaller open-sourced LLMs. Previous distillation methods usually prompt ChatGPT to generate a set of instructions and answers, for the student model to learn. However, such standard distillation approach neglects the merits and conditions of the student model. Inspired by modern teaching principles, we design a personalised distillation process, in which the student attempts to solve a task first, then the teacher provides an adaptive refinement for the student to improve. Instead of feeding the student with teacher's prior, personalised distillation enables personalised learning for the student model, as it only learns on examples it makes mistakes upon and learns to improve its own solution. On code generation, personalised distillation consistently outperforms standard distillation with only one third of the data. With only 2.5-3K personalised examples that incur a data-collection cost of 4-6$, we boost CodeGen-mono-16B by 7% to achieve 36.4% pass@1 and StarCoder by 12.2% to achieve 45.8% pass@1 on HumanEval.
CodeChain: Towards Modular Code Generation Through Chain of Self-revisions with Representative Sub-modules
Oct 13, 2023Large Language Models (LLMs) have already become quite proficient at solving simpler programming tasks like those in HumanEval or MBPP benchmarks. However, solving more complex and competitive programming tasks is still quite challenging for these models - possibly due to their tendency to generate solutions as monolithic code blocks instead of decomposing them into logical sub-tasks and sub-modules. On the other hand, experienced programmers instinctively write modularized code with abstraction for solving complex tasks, often reusing previously developed modules. To address this gap, we propose CodeChain, a novel framework for inference that elicits modularized code generation through a chain of self-revisions, each being guided by some representative sub-modules generated in previous iterations. Concretely, CodeChain first instructs the LLM to generate modularized codes through chain-of-thought prompting. Then it applies a chain of self-revisions by iterating the two steps: 1) extracting and clustering the generated sub-modules and selecting the cluster representatives as the more generic and re-usable implementations, and 2) augmenting the original chain-of-thought prompt with these selected module-implementations and instructing the LLM to re-generate new modularized solutions. We find that by naturally encouraging the LLM to reuse the previously developed and verified sub-modules, CodeChain can significantly boost both modularity as well as correctness of the generated solutions, achieving relative pass@1 improvements of 35% on APPS and 76% on CodeContests. It is shown to be effective on both OpenAI LLMs as well as open-sourced LLMs like WizardCoder. We also conduct comprehensive ablation studies with different methods of prompting, number of clusters, model sizes, program qualities, etc., to provide useful insights that underpin CodeChain's success.
AI for IT Operations on Cloud Platforms: Reviews, Opportunities and Challenges
Apr 10, 2023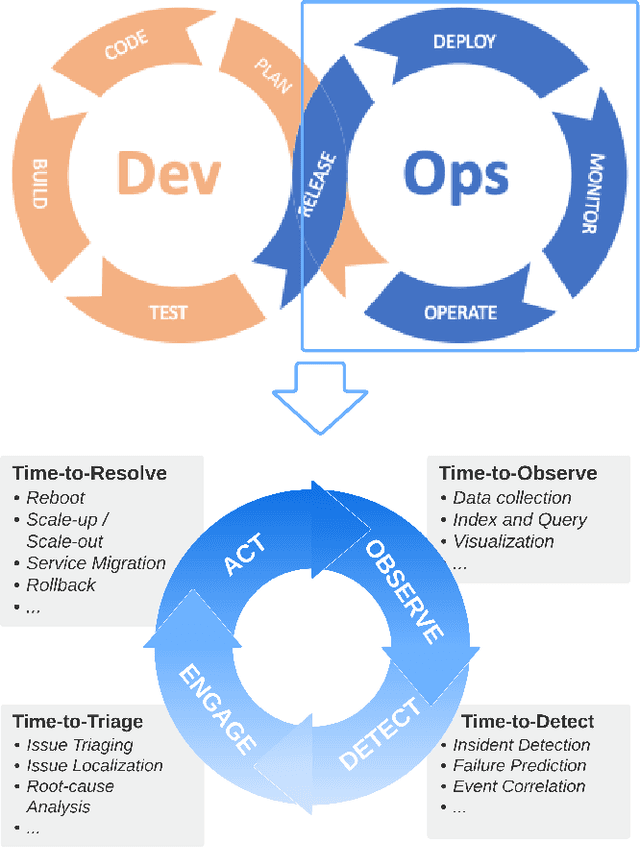
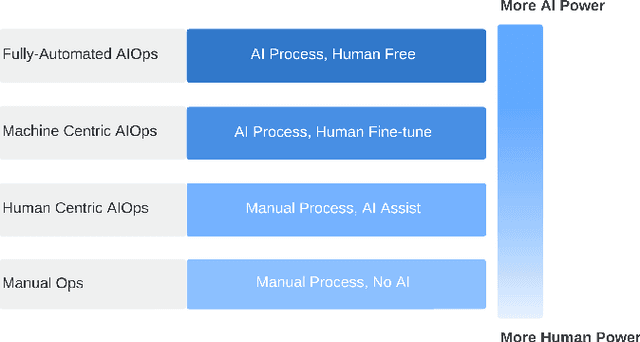
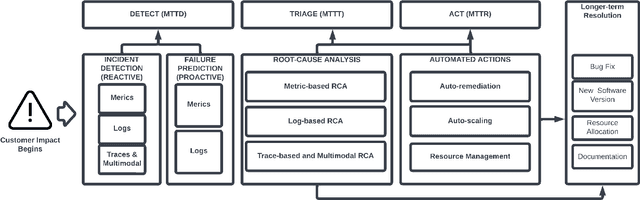
Artificial Intelligence for IT operations (AIOps) aims to combine the power of AI with the big data generated by IT Operations processes, particularly in cloud infrastructures, to provide actionable insights with the primary goal of maximizing availability. There are a wide variety of problems to address, and multiple use-cases, where AI capabilities can be leveraged to enhance operational efficiency. Here we provide a review of the AIOps vision, trends challenges and opportunities, specifically focusing on the underlying AI techniques. We discuss in depth the key types of data emitted by IT Operations activities, the scale and challenges in analyzing them, and where they can be helpful. We categorize the key AIOps tasks as - incident detection, failure prediction, root cause analysis and automated actions. We discuss the problem formulation for each task, and then present a taxonomy of techniques to solve these problems. We also identify relatively under explored topics, especially those that could significantly benefit from advances in AI literature. We also provide insights into the trends in this field, and what are the key investment opportunities.