 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResolving the bias-precision paradox with stochastic causal representation learning for personalized medicine
May 07, 2026Estimating individualized treatment effects from longitudinal observational data is central to data-driven medicine, yet existing methods face a fundamental limitation: reducing confounding bias often suppresses clinically informative heterogeneity, degrading patient-specific predictions. Here, we identify this tension as a bias-precision paradox in causal representation learning and introduce sampling-based maximum mean discrepancy (sMMD), a stochastic alignment strategy that replaces global adversarial balancing with subset-level matching. We instantiate this approach in a framework for counterfactual outcome prediction with attribution-grounded interpretability. Across two large-scale ICU cohorts (n = 27,783), our framework improves accuracy under distribution shift, reducing error by up to 11.5% and substantially increasing recall in high-risk tasks. Mechanistic analyses show that sMMD selectively preserves clinically decisive variables. In human-AI evaluation, our method outperforms clinicians-in-training and large language models, and improves clinician accuracy by 14.7% while reducing decision time, enabling interpretable, real-time clinical decision support.
CodeEvolve: LLM-Driven Evolutionary Optimization with Runtime-Enriched Target Selection for Multi-Language Code Enhancement
May 06, 2026We present CodeEvolve, an evolutionary framework for improving program performance and code quality with Large Language Models (LLMs). CodeEvolve extends OpenEvolve with runtime-guided target selection, Monte Carlo Tree Search (MCTS), automated code refinement, and language-specific evaluation pipelines for Java and Salesforce Apex. The system uses Java Flight Recorder (JFR) profiles to build weighted component graphs and select optimization targets that account for most execution cost, reducing reliance on manual bottleneck identification. For each target, CodeEvolve generates candidate edits, evaluates them through build validation, unit tests, performance checks, static analysis, and LLM-based review, and retains only variants that preserve functional correctness. Across real-world optimization tasks, CodeEvolve improves performance and code metrics while maintaining correctness. On a large enterprise Java codebase, it achieves an average speedup of 15.22$\times$ across seven hotspot functions and outperforms single-pass LLM optimization on five of them. An ablation study on Apex optimization shows that the full MCTS-augmented configuration produces 19.5 valid programs out of 20 on average, indicating that search, filtering, and refinement each contribute to more reliable optimization.
GPA: Learning GUI Process Automation from Demonstrations
Apr 02, 2026GUI Process Automation (GPA) is a lightweight but general vision-based Robotic Process Automation (RPA), which enables fast and stable process replay with only a single demo. Addressing the fragility of traditional RPA and the non-deterministic risks of current vision language model-based GUI agents, GPA introduces three core benefits: (1) Robustness via Sequential Monte Carlo-based localization to handle rescaling and detection uncertainty; (2) Deterministic and Reliability safeguarded by readiness calibration; and (3) Privacy through fast, fully local execution. This approach delivers the adaptability, robustness, and security required for enterprise workflows. It can also be used as an MCP/CLI tool by other agents with coding capabilities so that the agent only reasons and orchestrates while GPA handles the GUI execution. We conducted a pilot experiment to compare GPA with Gemini 3 Pro (with CUA tools) and found that GPA achieves higher success rate with 10 times faster execution speed in finishing long-horizon GUI tasks.
Improving Methodologies for LLM Evaluations Across Global Languages
Jan 22, 2026As frontier AI models are deployed globally, it is essential that their behaviour remains safe and reliable across diverse linguistic and cultural contexts. To examine how current model safeguards hold up in such settings, participants from the International Network for Advanced AI Measurement, Evaluation and Science, including representatives from Singapore, Japan, Australia, Canada, the EU, France, Kenya, South Korea and the UK conducted a joint multilingual evaluation exercise. Led by Singapore AISI, two open-weight models were tested across ten languages spanning high and low resourced groups: Cantonese English, Farsi, French, Japanese, Korean, Kiswahili, Malay, Mandarin Chinese and Telugu. Over 6,000 newly translated prompts were evaluated across five harm categories (privacy, non-violent crime, violent crime, intellectual property and jailbreak robustness), using both LLM-as-a-judge and human annotation. The exercise shows how safety behaviours can vary across languages. These include differences in safeguard robustness across languages and harm types and variation in evaluator reliability (LLM-as-judge vs. human review). Further, it also generated methodological insights for improving multilingual safety evaluations, such as the need for culturally contextualised translations, stress-tested evaluator prompts and clearer human annotation guidelines. This work represents an initial step toward a shared framework for multilingual safety testing of advanced AI systems and calls for continued collaboration with the wider research community and industry.
MCP-Universe: Benchmarking Large Language Models with Real-World Model Context Protocol Servers
Aug 20, 2025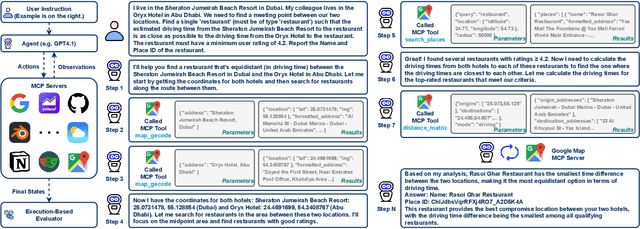
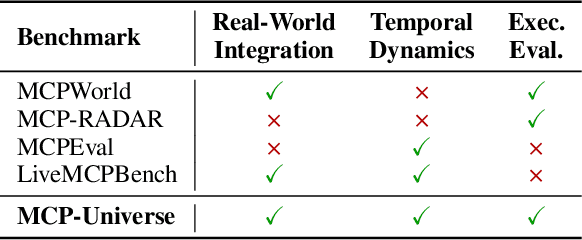
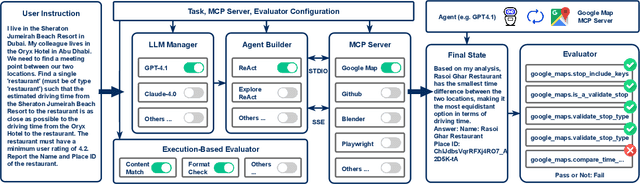
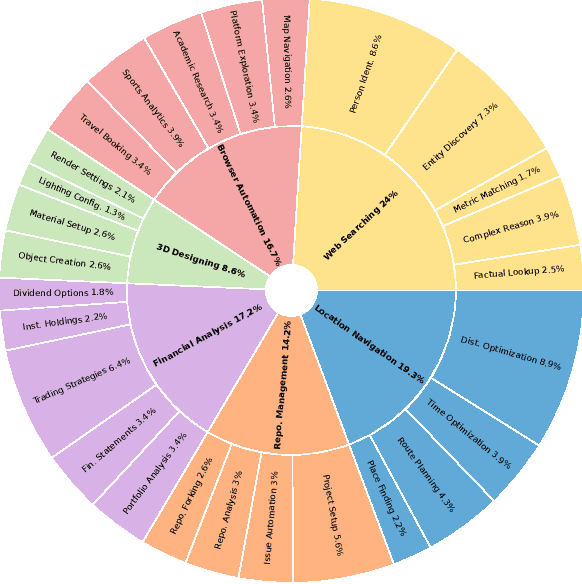
The Model Context Protocol has emerged as a transformative standard for connecting large language models to external data sources and tools, rapidly gaining adoption across major AI providers and development platforms. However, existing benchmarks are overly simplistic and fail to capture real application challenges such as long-horizon reasoning and large, unfamiliar tool spaces. To address this critical gap, we introduce MCP-Universe, the first comprehensive benchmark specifically designed to evaluate LLMs in realistic and hard tasks through interaction with real-world MCP servers. Our benchmark encompasses 6 core domains spanning 11 different MCP servers: Location Navigation, Repository Management, Financial Analysis, 3D Design, Browser Automation, and Web Searching. To ensure rigorous evaluation, we implement execution-based evaluators, including format evaluators for agent format compliance, static evaluators for time-invariant content matching, and dynamic evaluators that automatically retrieve real-time ground truth for temporally sensitive tasks. Through extensive evaluation of leading LLMs, we find that even SOTA models such as GPT-5 (43.72%), Grok-4 (33.33%) and Claude-4.0-Sonnet (29.44%) exhibit significant performance limitations. In addition, our benchmark poses a significant long-context challenge for LLM agents, as the number of input tokens increases rapidly with the number of interaction steps. Moreover, it introduces an unknown-tools challenge, as LLM agents often lack familiarity with the precise usage of the MCP servers. Notably, enterprise-level agents like Cursor cannot achieve better performance than standard ReAct frameworks. Beyond evaluation, we open-source our extensible evaluation framework with UI support, enabling researchers and practitioners to seamlessly integrate new agents and MCP servers while fostering innovation in the rapidly evolving MCP ecosystem.
Deep Learning Approaches for Anti-Money Laundering on Mobile Transactions: Review, Framework, and Directions
Mar 13, 2025Money laundering is a financial crime that obscures the origin of illicit funds, necessitating the development and enforcement of anti-money laundering (AML) policies by governments and organizations. The proliferation of mobile payment platforms and smart IoT devices has significantly complicated AML investigations. As payment networks become more interconnected, there is an increasing need for efficient real-time detection to process large volumes of transaction data on heterogeneous payment systems by different operators such as digital currencies, cryptocurrencies and account-based payments. Most of these mobile payment networks are supported by connected devices, many of which are considered loT devices in the FinTech space that constantly generate data. Furthermore, the growing complexity and unpredictability of transaction patterns across these networks contribute to a higher incidence of false positives. While machine learning solutions have the potential to enhance detection efficiency, their application in AML faces unique challenges, such as addressing privacy concerns tied to sensitive financial data and managing the real-world constraint of limited data availability due to data regulations. Existing surveys in the AML literature broadly review machine learning approaches for money laundering detection, but they often lack an in-depth exploration of advanced deep learning techniques - an emerging field with significant potential. To address this gap, this paper conducts a comprehensive review of deep learning solutions and the challenges associated with their use in AML. Additionally, we propose a novel framework that applies the least-privilege principle by integrating machine learning techniques, codifying AML red flags, and employing account profiling to provide context for predictions and enable effective fraud detection under limited data availability....
Efficient Dataset Distillation through Alignment with Smooth and High-Quality Expert Trajectories
Oct 16, 2023Training a large and state-of-the-art machine learning model typically necessitates the use of large-scale datasets, which, in turn, makes the training and parameter-tuning process expensive and time-consuming. Some researchers opt to distil information from real-world datasets into tiny and compact synthetic datasets while maintaining their ability to train a well-performing model, hence proposing a data-efficient method known as Dataset Distillation (DD). Despite recent progress in this field, existing methods still underperform and cannot effectively replace large datasets. In this paper, unlike previous methods that focus solely on improving the efficacy of student distillation, we are the first to recognize the important interplay between expert and student. We argue the significant impact of expert smoothness when employing more potent expert trajectories in subsequent dataset distillation. Based on this, we introduce the integration of clipping loss and gradient penalty to regulate the rate of parameter changes in expert trajectories. Furthermore, in response to the sensitivity exhibited towards randomly initialized variables during distillation, we propose representative initialization for synthetic dataset and balanced inner-loop loss. Finally, we present two enhancement strategies, namely intermediate matching loss and weight perturbation, to mitigate the potential occurrence of cumulative errors. We conduct extensive experiments on datasets of different scales, sizes, and resolutions. The results demonstrate that the proposed method significantly outperforms prior methods.
PyRCA: A Library for Metric-based Root Cause Analysis
Jun 20, 2023We introduce PyRCA, an open-source Python machine learning library of Root Cause Analysis (RCA) for Artificial Intelligence for IT Operations (AIOps). It provides a holistic framework to uncover the complicated metric causal dependencies and automatically locate root causes of incidents. It offers a unified interface for multiple commonly used RCA models, encompassing both graph construction and scoring tasks. This library aims to provide IT operations staff, data scientists, and researchers a one-step solution to rapid model development, model evaluation and deployment to online applications. In particular, our library includes various causal discovery methods to support causal graph construction, and multiple types of root cause scoring methods inspired by Bayesian analysis, graph analysis and causal analysis, etc. Our GUI dashboard offers practitioners an intuitive point-and-click interface, empowering them to easily inject expert knowledge through human interaction. With the ability to visualize causal graphs and the root cause of incidents, practitioners can quickly gain insights and improve their workflow efficiency. This technical report introduces PyRCA's architecture and major functionalities, while also presenting benchmark performance numbers in comparison to various baseline models. Additionally, we demonstrate PyRCA's capabilities through several example use cases.
AI for IT Operations on Cloud Platforms: Reviews, Opportunities and Challenges
Apr 10, 2023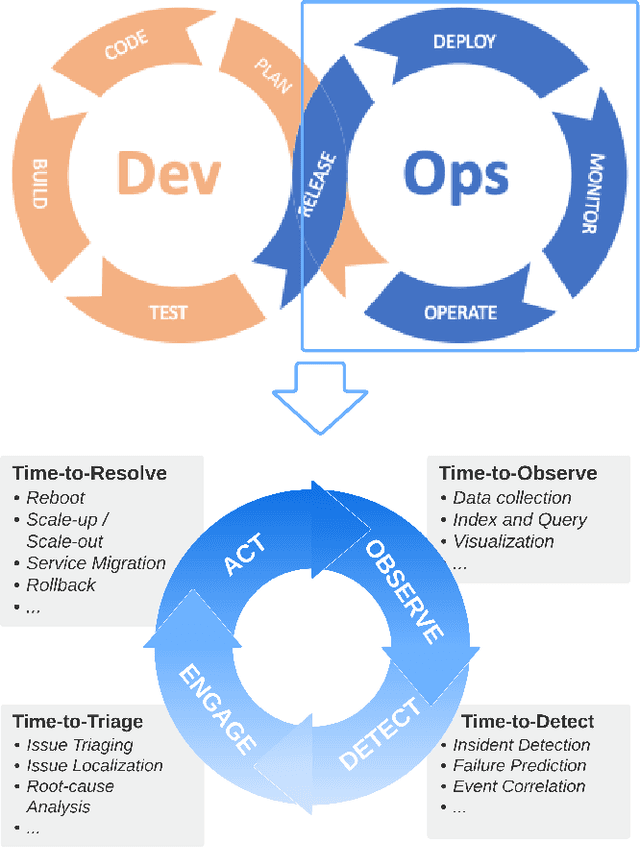
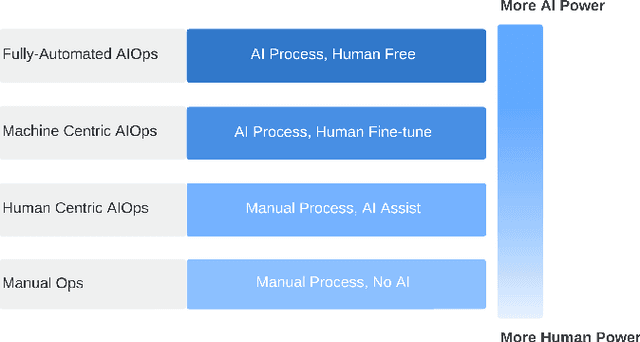
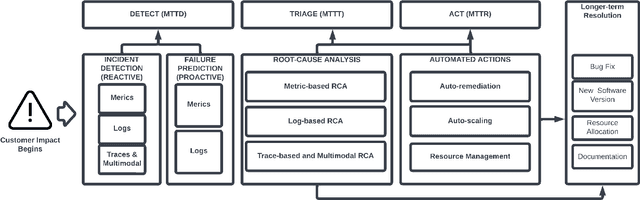
Artificial Intelligence for IT operations (AIOps) aims to combine the power of AI with the big data generated by IT Operations processes, particularly in cloud infrastructures, to provide actionable insights with the primary goal of maximizing availability. There are a wide variety of problems to address, and multiple use-cases, where AI capabilities can be leveraged to enhance operational efficiency. Here we provide a review of the AIOps vision, trends challenges and opportunities, specifically focusing on the underlying AI techniques. We discuss in depth the key types of data emitted by IT Operations activities, the scale and challenges in analyzing them, and where they can be helpful. We categorize the key AIOps tasks as - incident detection, failure prediction, root cause analysis and automated actions. We discuss the problem formulation for each task, and then present a taxonomy of techniques to solve these problems. We also identify relatively under explored topics, especially those that could significantly benefit from advances in AI literature. We also provide insights into the trends in this field, and what are the key investment opportunities.
LogAI: A Library for Log Analytics and Intelligence
Jan 31, 2023

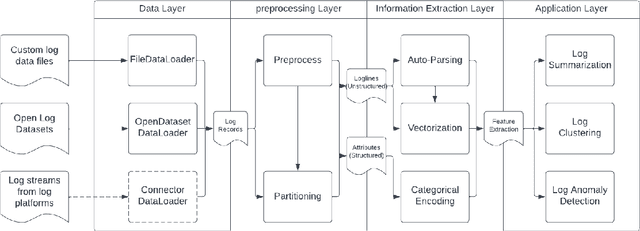
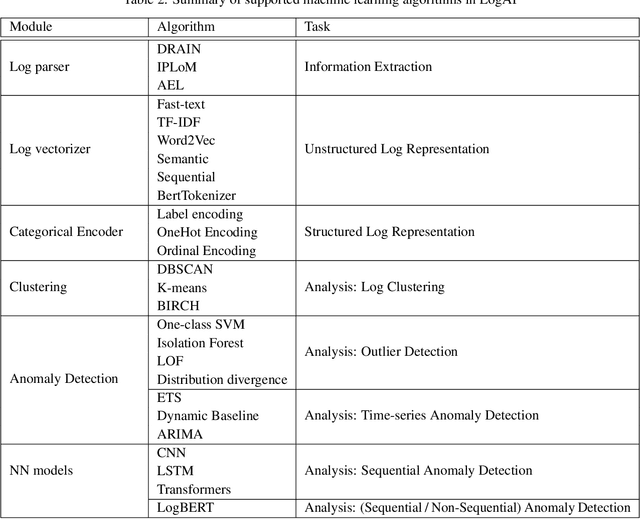
Software and System logs record runtime information about processes executing within a system. These logs have become the most critical and ubiquitous forms of observability data that help developers understand system behavior, monitor system health and resolve issues. However, the volume of logs generated can be humongous (of the order of petabytes per day) especially for complex distributed systems, such as cloud, search engine, social media, etc. This has propelled a lot of research on developing AI-based log based analytics and intelligence solutions that can process huge volume of raw logs and generate insights. In order to enable users to perform multiple types of AI-based log analysis tasks in a uniform manner, we introduce LogAI (https://github.com/salesforce/logai), a one-stop open source library for log analytics and intelligence. LogAI supports tasks such as log summarization, log clustering and log anomaly detection. It adopts the OpenTelemetry data model, to enable compatibility with different log management platforms. LogAI provides a unified model interface and provides popular time-series, statistical learning and deep learning models. Alongside this, LogAI also provides an out-of-the-box GUI for users to conduct interactive analysis. With LogAI, we can also easily benchmark popular deep learning algorithms for log anomaly detection without putting in redundant effort to process the logs. We have opensourced LogAI to cater to a wide range of applications benefiting both academic research and industrial prototyping.