 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-reality Location Privacy Protection in 6G-enabled Vehicular Metaverses: An LLM-enhanced Hybrid Generative Diffusion Model-based Approach
Jan 18, 2026The emergence of 6G-enabled vehicular metaverses enables Autonomous Vehicles (AVs) to operate across physical and virtual spaces through space-air-ground-sea integrated networks. The AVs can deploy AI agents powered by large AI models as personalized assistants, on edge servers to support intelligent driving decision making and enhanced on-board experiences. However, such cross-reality interactions may cause serious location privacy risks, as adversaries can infer AV trajectories by correlating the location reported when AVs request LBS in reality with the location of the edge servers on which their corresponding AI agents are deployed in virtuality. To address this challenge, we design a cross-reality location privacy protection framework based on hybrid actions, including continuous location perturbation in reality and discrete privacy-aware AI agent migration in virtuality. In this framework, a new privacy metric, termed cross-reality location entropy, is proposed to effectively quantify the privacy levels of AVs. Based on this metric, we formulate an optimization problem to optimize the hybrid action, focusing on achieving a balance between location protection, service latency reduction, and quality of service maintenance. To solve the complex mixed-integer problem, we develop a novel LLM-enhanced Hybrid Diffusion Proximal Policy Optimization (LHDPPO) algorithm, which integrates LLM-driven informative reward design to enhance environment understanding with double Generative Diffusion Models-based policy exploration to handle high-dimensional action spaces, thereby enabling reliable determination of optimal hybrid actions. Extensive experiments on real-world datasets demonstrate that the proposed framework effectively mitigates cross-reality location privacy leakage for AVs while maintaining strong user immersion within 6G-enabled vehicular metaverse scenarios.
State Backdoor: Towards Stealthy Real-world Poisoning Attack on Vision-Language-Action Model in State Space
Jan 07, 2026Vision-Language-Action (VLA) models are widely deployed in safety-critical embodied AI applications such as robotics. However, their complex multimodal interactions also expose new security vulnerabilities. In this paper, we investigate a backdoor threat in VLA models, where malicious inputs cause targeted misbehavior while preserving performance on clean data. Existing backdoor methods predominantly rely on inserting visible triggers into visual modality, which suffer from poor robustness and low insusceptibility in real-world settings due to environmental variability. To overcome these limitations, we introduce the State Backdoor, a novel and practical backdoor attack that leverages the robot arm's initial state as the trigger. To optimize trigger for insusceptibility and effectiveness, we design a Preference-guided Genetic Algorithm (PGA) that efficiently searches the state space for minimal yet potent triggers. Extensive experiments on five representative VLA models and five real-world tasks show that our method achieves over 90% attack success rate without affecting benign task performance, revealing an underexplored vulnerability in embodied AI systems.
Rethinking Secure Semantic Communications in the Age of Generative and Agentic AI: Threats and Opportunities
Jan 06, 2026Semantic communication (SemCom) improves communication efficiency by transmitting task-relevant information instead of raw bits and is expected to be a key technology for 6G networks. Recent advances in generative AI (GenAI) further enhance SemCom by enabling robust semantic encoding and decoding under limited channel conditions. However, these efficiency gains also introduce new security and privacy vulnerabilities. Due to the broadcast nature of wireless channels, eavesdroppers can also use powerful GenAI-based semantic decoders to recover private information from intercepted signals. Moreover, rapid advances in agentic AI enable eavesdroppers to perform long-term and adaptive inference through the integration of memory, external knowledge, and reasoning capabilities. This allows eavesdroppers to further infer user private behavior and intent beyond the transmitted content. Motivated by these emerging challenges, this paper comprehensively rethinks the security and privacy of SemCom systems in the age of generative and agentic AI. We first present a systematic taxonomy of eavesdropping threat models in SemCom systems. Then, we provide insights into how GenAI and agentic AI can enhance eavesdropping threats. Meanwhile, we also highlight potential opportunities for leveraging GenAI and agentic AI to design privacy-preserving SemCom systems.
Agentic AI for Integrated Sensing and Communication: Analysis, Framework, and Case Study
Dec 17, 2025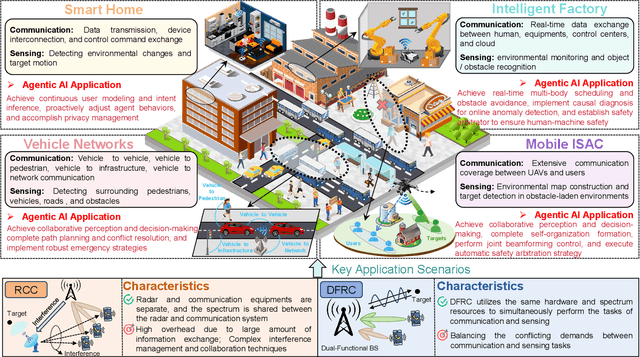
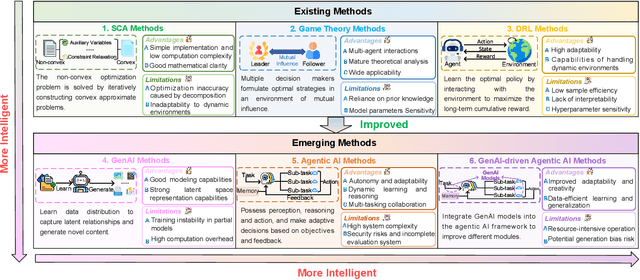
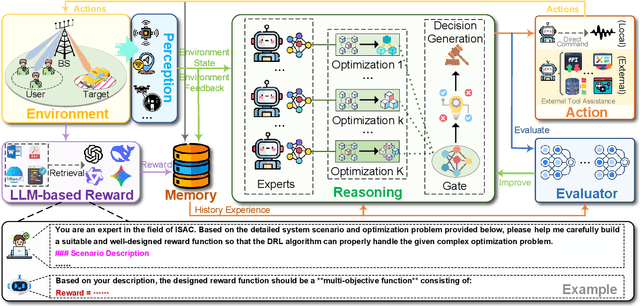
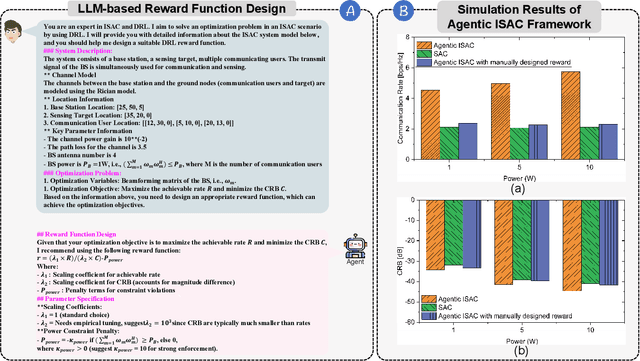
Integrated sensing and communication (ISAC) has emerged as a key development direction in the sixth-generation (6G) era, which provides essential support for the collaborative sensing and communication of future intelligent networks. However, as wireless environments become increasingly dynamic and complex, ISAC systems require more intelligent processing and more autonomous operation to maintain efficiency and adaptability. Meanwhile, agentic artificial intelligence (AI) offers a feasible solution to address these challenges by enabling continuous perception-reasoning-action loops in dynamic environments to support intelligent, autonomous, and efficient operation for ISAC systems. As such, we delve into the application value and prospects of agentic AI in ISAC systems in this work. Firstly, we provide a comprehensive review of agentic AI and ISAC systems to demonstrate their key characteristics. Secondly, we show several common optimization approaches for ISAC systems and highlight the significant advantages of generative artificial intelligence (GenAI)-based agentic AI. Thirdly, we propose a novel agentic ISAC framework and prensent a case study to verify its superiority in optimizing ISAC performance. Finally, we clarify future research directions for agentic AI-based ISAC systems.
Agentic Graph Neural Networks for Wireless Communications and Networking Towards Edge General Intelligence: A Survey
Aug 12, 2025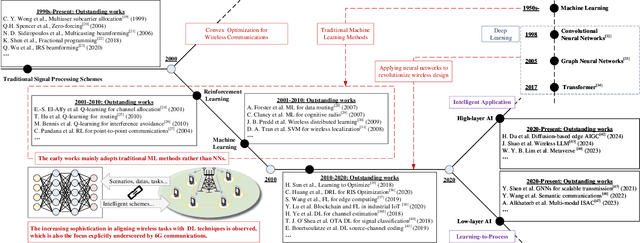
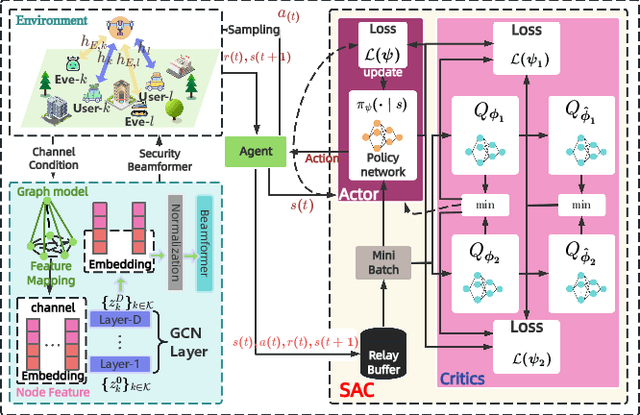
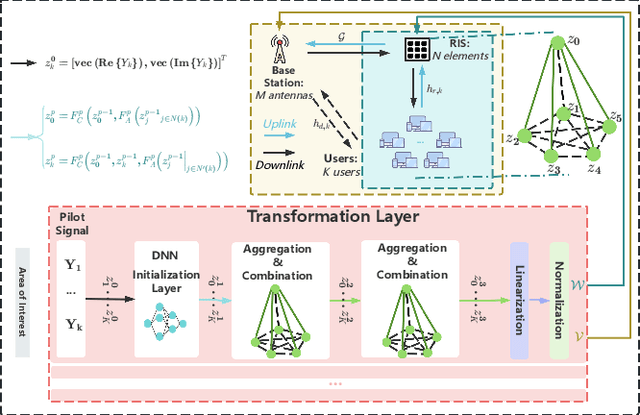
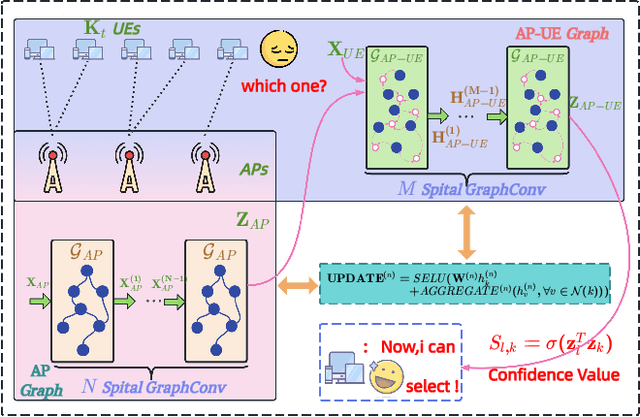
The rapid advancement of communication technologies has driven the evolution of communication networks towards both high-dimensional resource utilization and multifunctional integration. This evolving complexity poses significant challenges in designing communication networks to satisfy the growing quality-of-service and time sensitivity of mobile applications in dynamic environments. Graph neural networks (GNNs) have emerged as fundamental deep learning (DL) models for complex communication networks. GNNs not only augment the extraction of features over network topologies but also enhance scalability and facilitate distributed computation. However, most existing GNNs follow a traditional passive learning framework, which may fail to meet the needs of increasingly diverse wireless systems. This survey proposes the employment of agentic artificial intelligence (AI) to organize and integrate GNNs, enabling scenario- and task-aware implementation towards edge general intelligence. To comprehend the full capability of GNNs, we holistically review recent applications of GNNs in wireless communications and networking. Specifically, we focus on the alignment between graph representations and network topologies, and between neural architectures and wireless tasks. We first provide an overview of GNNs based on prominent neural architectures, followed by the concept of agentic GNNs. Then, we summarize and compare GNN applications for conventional systems and emerging technologies, including physical, MAC, and network layer designs, integrated sensing and communication (ISAC), reconfigurable intelligent surface (RIS) and cell-free network architecture. We further propose a large language model (LLM) framework as an intelligent question-answering agent, leveraging this survey as a local knowledge base to enable GNN-related responses tailored to wireless communication research.
SparseC-AFM: a deep learning method for fast and accurate characterization of MoS$_2$ with C-AFM
Jul 17, 2025The increasing use of two-dimensional (2D) materials in nanoelectronics demands robust metrology techniques for electrical characterization, especially for large-scale production. While atomic force microscopy (AFM) techniques like conductive AFM (C-AFM) offer high accuracy, they suffer from slow data acquisition speeds due to the raster scanning process. To address this, we introduce SparseC-AFM, a deep learning model that rapidly and accurately reconstructs conductivity maps of 2D materials like MoS$_2$ from sparse C-AFM scans. Our approach is robust across various scanning modes, substrates, and experimental conditions. We report a comparison between (a) classic flow implementation, where a high pixel density C-AFM image (e.g., 15 minutes to collect) is manually parsed to extract relevant material parameters, and (b) our SparseC-AFM method, which achieves the same operation using data that requires substantially less acquisition time (e.g., under 5 minutes). SparseC-AFM enables efficient extraction of critical material parameters in MoS$_2$, including film coverage, defect density, and identification of crystalline island boundaries, edges, and cracks. We achieve over 11x reduction in acquisition time compared to manual extraction from a full-resolution C-AFM image. Moreover, we demonstrate that our model-predicted samples exhibit remarkably similar electrical properties to full-resolution data gathered using classic-flow scanning. This work represents a significant step toward translating AI-assisted 2D material characterization from laboratory research to industrial fabrication. Code and model weights are available at github.com/UNITES-Lab/sparse-cafm.
The Quest for Efficient Reasoning: A Data-Centric Benchmark to CoT Distillation
May 24, 2025Data-centric distillation, including data augmentation, selection, and mixing, offers a promising path to creating smaller, more efficient student Large Language Models (LLMs) that retain strong reasoning abilities. However, there still lacks a comprehensive benchmark to systematically assess the effect of each distillation approach. This paper introduces DC-CoT, the first data-centric benchmark that investigates data manipulation in chain-of-thought (CoT) distillation from method, model and data perspectives. Utilizing various teacher models (e.g., o4-mini, Gemini-Pro, Claude-3.5) and student architectures (e.g., 3B, 7B parameters), we rigorously evaluate the impact of these data manipulations on student model performance across multiple reasoning datasets, with a focus on in-distribution (IID) and out-of-distribution (OOD) generalization, and cross-domain transfer. Our findings aim to provide actionable insights and establish best practices for optimizing CoT distillation through data-centric techniques, ultimately facilitating the development of more accessible and capable reasoning models. The dataset can be found at https://huggingface.co/datasets/rana-shahroz/DC-COT, while our code is shared in https://anonymous.4open.science/r/DC-COT-FF4C/.
Temporal Spectrum Cartography in Low-Altitude Economy Networks: A Generative AI Framework with Multi-Agent Learning
May 21, 2025This paper introduces a two-stage generative AI (GenAI) framework tailored for temporal spectrum cartography in low-altitude economy networks (LAENets). LAENets, characterized by diverse aerial devices such as UAVs, rely heavily on wireless communication technologies while facing challenges, including spectrum congestion and dynamic environmental interference. Traditional spectrum cartography methods have limitations in handling the temporal and spatial complexities inherent to these networks. Addressing these challenges, the proposed framework first employs a Reconstructive Masked Autoencoder (RecMAE) capable of accurately reconstructing spectrum maps from sparse and temporally varying sensor data using a novel dual-mask mechanism. This approach significantly enhances the precision of reconstructed radio frequency (RF) power maps. In the second stage, the Multi-agent Diffusion Policy (MADP) method integrates diffusion-based reinforcement learning to optimize the trajectories of dynamic UAV sensors. By leveraging temporal-attention encoding, this method effectively manages spatial exploration and exploitation to minimize cumulative reconstruction errors. Extensive numerical experiments validate that this integrated GenAI framework outperforms traditional interpolation methods and deep learning baselines by achieving 57.35% and 88.68% reconstruction error reduction, respectively. The proposed trajectory planner substantially improves spectrum map accuracy, reconstruction stability, and sensor deployment efficiency in dynamically evolving low-altitude environments.
LAMeTA: Intent-Aware Agentic Network Optimization via a Large AI Model-Empowered Two-Stage Approach
May 18, 2025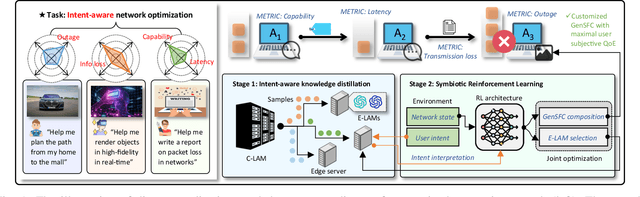
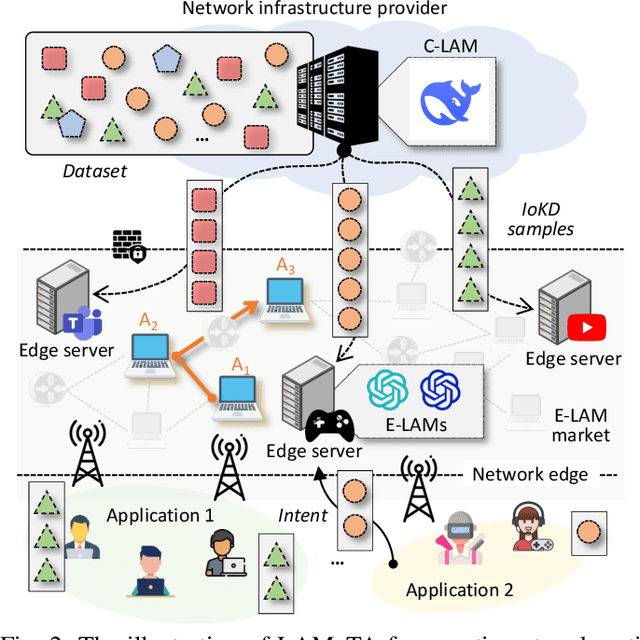
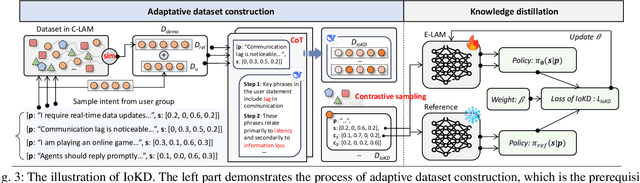
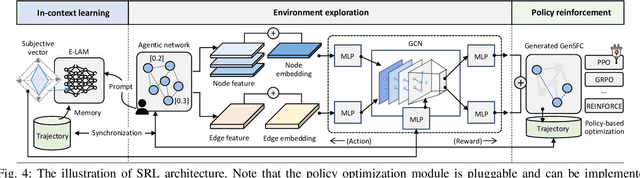
Nowadays, Generative AI (GenAI) reshapes numerous domains by enabling machines to create content across modalities. As GenAI evolves into autonomous agents capable of reasoning, collaboration, and interaction, they are increasingly deployed on network infrastructures to serve humans automatically. This emerging paradigm, known as the agentic network, presents new optimization challenges due to the demand to incorporate subjective intents of human users expressed in natural language. Traditional generic Deep Reinforcement Learning (DRL) struggles to capture intent semantics and adjust policies dynamically, thus leading to suboptimality. In this paper, we present LAMeTA, a Large AI Model (LAM)-empowered Two-stage Approach for intent-aware agentic network optimization. First, we propose Intent-oriented Knowledge Distillation (IoKD), which efficiently distills intent-understanding capabilities from resource-intensive LAMs to lightweight edge LAMs (E-LAMs) to serve end users. Second, we develop Symbiotic Reinforcement Learning (SRL), integrating E-LAMs with a policy-based DRL framework. In SRL, E-LAMs translate natural language user intents into structured preference vectors that guide both state representation and reward design. The DRL, in turn, optimizes the generative service function chain composition and E-LAM selection based on real-time network conditions, thus optimizing the subjective Quality-of-Experience (QoE). Extensive experiments conducted in an agentic network with 81 agents demonstrate that IoKD reduces mean squared error in intent prediction by up to 22.5%, while SRL outperforms conventional generic DRL by up to 23.5% in maximizing intent-aware QoE.
LLM-guided DRL for Multi-tier LEO Satellite Networks with Hybrid FSO/RF Links
May 17, 2025



Despite significant advancements in terrestrial networks, inherent limitations persist in providing reliable coverage to remote areas and maintaining resilience during natural disasters. Multi-tier networks with low Earth orbit (LEO) satellites and high-altitude platforms (HAPs) offer promising solutions, but face challenges from high mobility and dynamic channel conditions that cause unstable connections and frequent handovers. In this paper, we design a three-tier network architecture that integrates LEO satellites, HAPs, and ground terminals with hybrid free-space optical (FSO) and radio frequency (RF) links to maximize coverage while maintaining connectivity reliability. This hybrid approach leverages the high bandwidth of FSO for satellite-to-HAP links and the weather resilience of RF for HAP-to-ground links. We formulate a joint optimization problem to simultaneously balance downlink transmission rate and handover frequency by optimizing network configuration and satellite handover decisions. The problem is highly dynamic and non-convex with time-coupled constraints. To address these challenges, we propose a novel large language model (LLM)-guided truncated quantile critics algorithm with dynamic action masking (LTQC-DAM) that utilizes dynamic action masking to eliminate unnecessary exploration and employs LLMs to adaptively tune hyperparameters. Simulation results demonstrate that the proposed LTQC-DAM algorithm outperforms baseline algorithms in terms of convergence, downlink transmission rate, and handover frequency. We also reveal that compared to other state-of-the-art LLMs, DeepSeek delivers the best performance through gradual, contextually-aware parameter adjustments.