 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Secure Semantic Communications in the Age of Generative and Agentic AI: Threats and Opportunities
Jan 06, 2026Semantic communication (SemCom) improves communication efficiency by transmitting task-relevant information instead of raw bits and is expected to be a key technology for 6G networks. Recent advances in generative AI (GenAI) further enhance SemCom by enabling robust semantic encoding and decoding under limited channel conditions. However, these efficiency gains also introduce new security and privacy vulnerabilities. Due to the broadcast nature of wireless channels, eavesdroppers can also use powerful GenAI-based semantic decoders to recover private information from intercepted signals. Moreover, rapid advances in agentic AI enable eavesdroppers to perform long-term and adaptive inference through the integration of memory, external knowledge, and reasoning capabilities. This allows eavesdroppers to further infer user private behavior and intent beyond the transmitted content. Motivated by these emerging challenges, this paper comprehensively rethinks the security and privacy of SemCom systems in the age of generative and agentic AI. We first present a systematic taxonomy of eavesdropping threat models in SemCom systems. Then, we provide insights into how GenAI and agentic AI can enhance eavesdropping threats. Meanwhile, we also highlight potential opportunities for leveraging GenAI and agentic AI to design privacy-preserving SemCom systems.
DeepGuard: Defending Deep Joint Source-Channel Coding Against Eavesdropping at Physical-Layer
Dec 21, 2025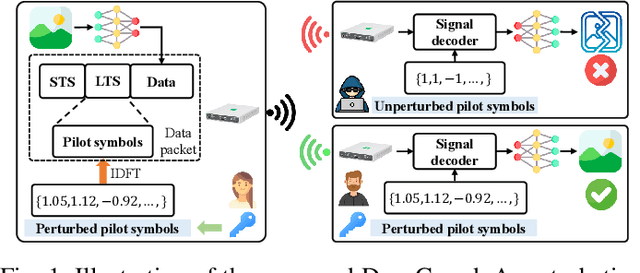
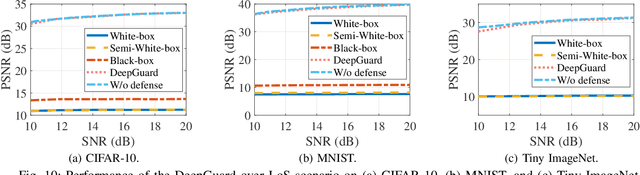
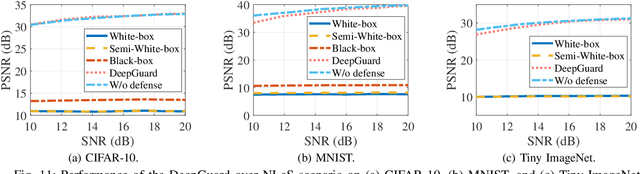

Deep joint source-channel coding (DeepJSCC) has emerged as a promising paradigm for efficient and robust information transmission. However, its intrinsic characteristics also pose new security challenges, notably an increased vulnerability to eavesdropping attacks. Existing studies on defending against eavesdropping attacks in DeepJSCC, while demonstrating certain effectiveness, often incur considerable computational overhead or introduce performance trade-offs that may adversely affect legitimate users. In this paper, we present DeepGuard, to the best of our knowledge, the first physical-layer defense framework for DeepJSCC against eavesdropping attacks, validated through over-the-air experiments using software-defined radios (SDRs). Considering that existing eavesdropping attacks against DeepJSCC are limited to simulation under ideal channels, we take a step further by identifying and implementing four representative types of attacks under various configurations in orthogonal frequency-division multiplexing systems. These attacks are evaluated over-the-air under diverse scenarios, allowing us to comprehensively characterize the real-world threat landscape. To mitigate these threats, DeepGuard introduces a novel preamble perturbation mechanism that modifies the preamble shared only between legitimate transceivers. To realize it, we first conduct a theoretical analysis of the perturbation's impact on the signals intercepted by the eavesdropper. Building upon this, we develop an end-to-end perturbation optimization algorithm that significantly degrades eavesdropping performance while preserving reliable communication for legitimate users. We prototype DeepGuard using SDRs and conduct extensive over-the-air experiments in practical scenarios. Extensive experiments demonstrate that DeepGuard effectively mitigates eavesdropping threats.
Dynamical Multimodal Fusion with Mixture-of-Experts for Localizations
Jul 02, 2025Multimodal fingerprinting is a crucial technique to sub-meter 6G integrated sensing and communications (ISAC) localization, but two hurdles block deployment: (i) the contribution each modality makes to the target position varies with the operating conditions such as carrier frequency, and (ii) spatial and fingerprint ambiguities markedly undermine localization accuracy, especially in non-line-of-sight (NLOS) scenarios. To solve these problems, we introduce SCADF-MoE, a spatial-context aware dynamic fusion network built on a soft mixture-of-experts backbone. SCADF-MoE first clusters neighboring points into short trajectories to inject explicit spatial context. Then, it adaptively fuses channel state information, angle of arrival profile, distance, and gain through its learnable MoE router, so that the most reliable cues dominate at each carrier band. The fused representation is fed to a modality-task MoE that simultaneously regresses the coordinates of every vertex in the trajectory and its centroid, thereby exploiting inter-point correlations. Finally, an auxiliary maximum-mean-discrepancy loss enforces expert diversity and mitigates gradient interference, stabilizing multi-task training. On three real urban layouts and three carrier bands (2.6, 6, 28 GHz), the model delivers consistent sub-meter MSE and halves unseen-NLOS error versus the best prior work. To our knowledge, this is the first work that leverages large-scale multimodal MoE for frequency-robust ISAC localization.
Semantic Exploration and Dense Mapping of Complex Environments using Ground Robots Equipped with LiDAR and Panoramic Camera
May 28, 2025This paper presents a system for autonomous semantic exploration and dense semantic target mapping of a complex unknown environment using a ground robot equipped with a LiDAR-panoramic camera suite. Existing approaches often struggle to balance collecting high-quality observations from multiple view angles and avoiding unnecessary repetitive traversal. To fill this gap, we propose a complete system combining mapping and planning. We first redefine the task as completing both geometric coverage and semantic viewpoint observation. We then manage semantic and geometric viewpoints separately and propose a novel Priority-driven Decoupled Local Sampler to generate local viewpoint sets. This enables explicit multi-view semantic inspection and voxel coverage without unnecessary repetition. Building on this, we develop a hierarchical planner to ensure efficient global coverage. In addition, we propose a Safe Aggressive Exploration State Machine, which allows aggressive exploration behavior while ensuring the robot's safety. Our system includes a plug-and-play semantic target mapping module that integrates seamlessly with state-of-the-art SLAM algorithms for pointcloud-level dense semantic target mapping. We validate our approach through extensive experiments in both realistic simulations and complex real-world environments. Simulation results show that our planner achieves faster exploration and shorter travel distances while guaranteeing a specified number of multi-view inspections. Real-world experiments further confirm the system's effectiveness in achieving accurate dense semantic object mapping of unstructured environments.
DGRAG: Distributed Graph-based Retrieval-Augmented Generation in Edge-Cloud Systems
May 26, 2025Retrieval-Augmented Generation (RAG) has emerged as a promising approach to enhance the capabilities of language models by integrating external knowledge. Due to the diversity of data sources and the constraints of memory and computing resources, real-world data is often scattered in multiple devices. Conventional RAGs that store massive amounts of scattered data centrally face increasing privacy concerns and high computational costs. Additionally, RAG in a central node raises latency issues when searching over a large-scale knowledge base. To address these challenges, we propose a distributed Knowledge Graph-based RAG approach, referred to as DGRAG, in an edge-cloud system, where each edge device maintains a local knowledge base without the need to share it with the cloud, instead sharing only summaries of its knowledge. Specifically, DGRAG has two main phases. In the Distributed Knowledge Construction phase, DGRAG organizes local knowledge using knowledge graphs, generating subgraph summaries and storing them in a summary database in the cloud as information sharing. In the Collaborative Retrieval and Generation phase, DGRAG first performs knowledge retrieval and answer generation locally, and a gate mechanism determines whether the query is beyond the scope of local knowledge or processing capabilities. For queries that exceed the local knowledge scope, the cloud retrieves knowledge from the most relevant edges based on the summaries and generates a more precise answer. Experimental results demonstrate the effectiveness of the proposed DGRAG approach in significantly improving the quality of question-answering tasks over baseline approaches.
Bridging the Modality Gap: Enhancing Channel Prediction with Semantically Aligned LLMs and Knowledge Distillation
May 19, 2025Accurate channel prediction is essential in massive multiple-input multiple-output (m-MIMO) systems to improve precoding effectiveness and reduce the overhead of channel state information (CSI) feedback. However, existing methods often suffer from accumulated prediction errors and poor generalization to dynamic wireless environments. Large language models (LLMs) have demonstrated remarkable modeling and generalization capabilities in tasks such as time series prediction, making them a promising solution. Nevertheless, a significant modality gap exists between the linguistic knowledge embedded in pretrained LLMs and the intrinsic characteristics of CSI, posing substantial challenges for their direct application to channel prediction. Moreover, the large parameter size of LLMs hinders their practical deployment in real-world communication systems with stringent latency constraints. To address these challenges, we propose a novel channel prediction framework based on semantically aligned large models, referred to as CSI-ALM, which bridges the modality gap between natural language and channel information. Specifically, we design a cross-modal fusion module that aligns CSI representations . Additionally, we maximize the cosine similarity between word embeddings and CSI embeddings to construct semantic cues. To reduce complexity and enable practical implementation, we further introduce a lightweight version of the proposed approach, called CSI-ALM-Light. This variant is derived via a knowledge distillation strategy based on attention matrices. Extensive experimental results demonstrate that CSI-ALM achieves a 1 dB gain over state-of-the-art deep learning methods. Moreover, under limited training data conditions, CSI-ALM-Light, with only 0.34M parameters, attains performance comparable to CSI-ALM and significantly outperforms conventional deep learning approaches.
Can Knowledge Improve Security? A Coding-Enhanced Jamming Approach for Semantic Communication
May 06, 2025As semantic communication (SemCom) attracts growing attention as a novel communication paradigm, ensuring the security of transmitted semantic information over open wireless channels has become a critical issue. However, traditional encryption methods often introduce significant additional communication overhead to maintain stability, and conventional learning-based secure SemCom methods typically rely on a channel capacity advantage for the legitimate receiver, which is challenging to guarantee in real-world scenarios. In this paper, we propose a coding-enhanced jamming method that eliminates the need to transmit a secret key by utilizing shared knowledge-potentially part of the training set of the SemCom system-between the legitimate receiver and the transmitter. Specifically, we leverage the shared private knowledge base to generate a set of private digital codebooks in advance using neural network (NN)-based encoders. For each transmission, we encode the transmitted data into digital sequence Y1 and associate Y1 with a sequence randomly picked from the private codebook, denoted as Y2, through superposition coding. Here, Y1 serves as the outer code and Y2 as the inner code. By optimizing the power allocation between the inner and outer codes, the legitimate receiver can reconstruct the transmitted data using successive decoding with the index of Y2 shared, while the eavesdropper' s decoding performance is severely degraded, potentially to the point of random guessing. Experimental results demonstrate that our method achieves comparable security to state-of-the-art approaches while significantly improving the reconstruction performance of the legitimate receiver by more than 1 dB across varying channel signal-to-noise ratios (SNRs) and compression ratios.
Enabling Training-Free Semantic Communication Systems with Generative Diffusion Models
May 05, 2025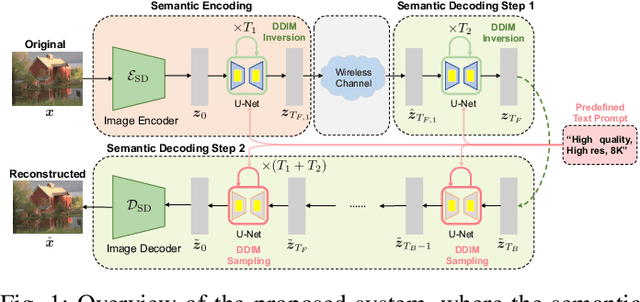
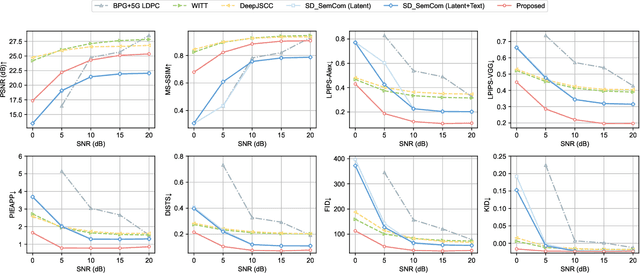


Semantic communication (SemCom) has recently emerged as a promising paradigm for next-generation wireless systems. Empowered by advanced artificial intelligence (AI) technologies, SemCom has achieved significant improvements in transmission quality and efficiency. However, existing SemCom systems either rely on training over large datasets and specific channel conditions or suffer from performance degradation under channel noise when operating in a training-free manner. To address these issues, we explore the use of generative diffusion models (GDMs) as training-free SemCom systems. Specifically, we design a semantic encoding and decoding method based on the inversion and sampling process of the denoising diffusion implicit model (DDIM), which introduces a two-stage forward diffusion process, split between the transmitter and receiver to enhance robustness against channel noise. Moreover, we optimize sampling steps to compensate for the increased noise level caused by channel noise. We also conduct a brief analysis to provide insights about this design. Simulations on the Kodak dataset validate that the proposed system outperforms the existing baseline SemCom systems across various metrics.
Empowering Agentic Video Analytics Systems with Video Language Models
May 02, 2025

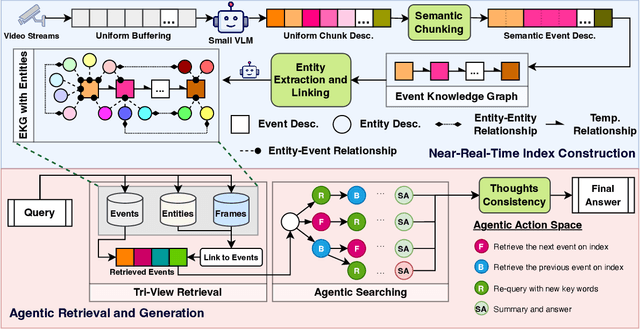
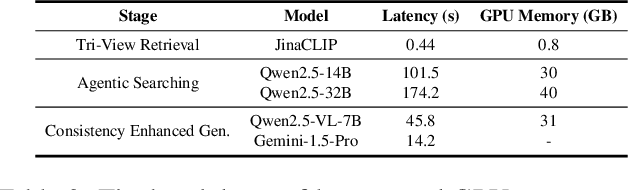
AI-driven video analytics has become increasingly pivotal across diverse domains. However, existing systems are often constrained to specific, predefined tasks, limiting their adaptability in open-ended analytical scenarios. The recent emergence of Video-Language Models (VLMs) as transformative technologies offers significant potential for enabling open-ended video understanding, reasoning, and analytics. Nevertheless, their limited context windows present challenges when processing ultra-long video content, which is prevalent in real-world applications. To address this, we introduce AVAS, a VLM-powered system designed for open-ended, advanced video analytics. AVAS incorporates two key innovations: (1) the near real-time construction of Event Knowledge Graphs (EKGs) for efficient indexing of long or continuous video streams, and (2) an agentic retrieval-generation mechanism that leverages EKGs to handle complex and diverse queries. Comprehensive evaluations on public benchmarks, LVBench and VideoMME-Long, demonstrate that AVAS achieves state-of-the-art performance, attaining 62.3% and 64.1% accuracy, respectively, significantly surpassing existing VLM and video Retrieval-Augmented Generation (RAG) systems. Furthermore, to evaluate video analytics in ultra-long and open-world video scenarios, we introduce a new benchmark, AVAS-100. This benchmark comprises 8 videos, each exceeding 10 hours in duration, along with 120 manually annotated, diverse, and complex question-answer pairs. On AVAS-100, AVAS achieves top-tier performance with an accuracy of 75.8%.
Enhancing the Security of Semantic Communication via Knowledge-Aided Coding and Jamming
May 01, 2025As semantic communication (SemCom) emerges as a promising communication paradigm, ensuring the security of semantic information over open wireless channels has become crucial. Traditional encryption methods introduce considerable communication overhead, while existing learning-based secure SemCom schemes often rely on a channel capacity advantage for the legitimate receiver, which is challenging to guarantee in practice. In this paper, we propose a coding-enhanced jamming approach that eliminates the need to transmit a secret key by utilizing shared knowledge between the legitimate receiver and the transmitter. We generate private codebooks with neural network (NN)-based encoders, using them to encode data into a sequence Y1, which is then superposed with a sequence Y2 drawn from the private codebook. By optimizing the power allocation between the two sequences, the legitimate receiver can successfully decode the data, while the eavesdropper' s performance is significantly degraded, potentially to the point of random guessing. Experimental results demonstrate that our method achieves comparable security to state-of-the-art approaches while significantly improving the reconstruction performance of the legitimate receiver by more than 1 dB across varying channel signal-to-noise ratios (SNRs) and compression ratios.