 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject-Attribute-Relation Representation based Video Semantic Communication
Jun 15, 2024



With the rapid growth of multimedia data volume, there is an increasing need for efficient video transmission in applications such as virtual reality and future video streaming services. Semantic communication is emerging as a vital technique for ensuring efficient and reliable transmission in low-bandwidth, high-noise settings. However, most current approaches focus on joint source-channel coding (JSCC) that depends on end-to-end training. These methods often lack an interpretable semantic representation and struggle with adaptability to various downstream tasks. In this paper, we introduce the use of object-attribute-relation (OAR) as a semantic framework for videos to facilitate low bit-rate coding and enhance the JSCC process for more effective video transmission. We utilize OAR sequences for both low bit-rate representation and generative video reconstruction. Additionally, we incorporate OAR into the image JSCC model to prioritize communication resources for areas more critical to downstream tasks. Our experiments on traffic surveillance video datasets assess the effectiveness of our approach in terms of video transmission performance. The empirical findings demonstrate that our OAR-based video coding method not only outperforms H.265 coding at lower bit-rates but also synergizes with JSCC to deliver robust and efficient video transmission.
Resource Allocation for Capacity Optimization in Joint Source-Channel Coding Systems
Nov 21, 2022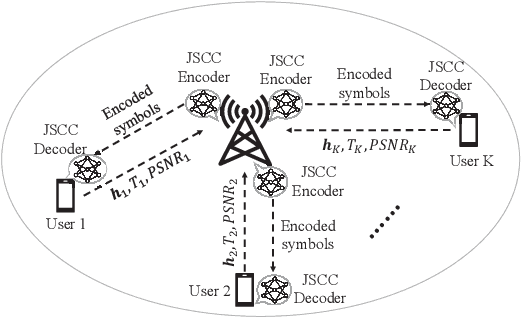
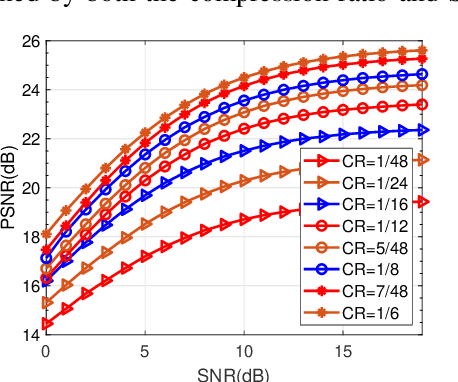
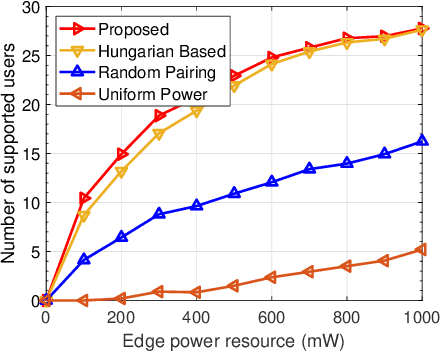
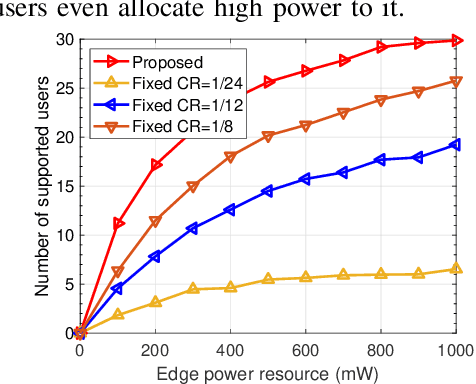
Benefited from the advances of deep learning (DL) techniques, deep joint source-channel coding (JSCC) has shown its great potential to improve the performance of wireless transmission. However, most of the existing works focus on the DL-based transceiver design of the JSCC model, while ignoring the resource allocation problem in wireless systems. In this paper, we consider a downlink resource allocation problem, where a base station (BS) jointly optimizes the compression ratio (CR) and power allocation as well as resource block (RB) assignment of each user according to the latency and performance constraints to maximize the number of users that successfully receive their requested content with desired quality. To solve this problem, we first decompose it into two subproblems without loss of optimality. The first subproblem is to minimize the required transmission power for each user under given RB allocation. We derive the closed-form expression of the optimal transmit power by searching the maximum feasible compression ratio. The second one aims at maximizing the number of supported users through optimal user-RB pairing, which we solve by utilizing bisection search as well as Karmarka' s algorithm. Simulation results validate the effectiveness of the proposed resource allocation method in terms of the number of satisfied users with given resources.
Generative Model Based Highly Efficient Semantic Communication Approach for Image Transmission
Nov 18, 2022

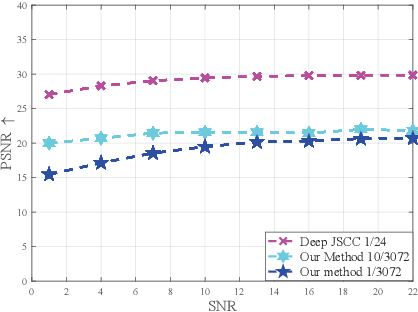
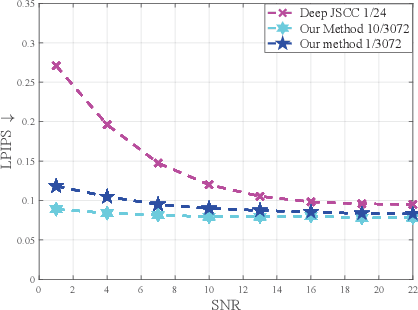
Deep learning (DL) based semantic communication methods have been explored to transmit images efficiently in recent years. In this paper, we propose a generative model based semantic communication to further improve the efficiency of image transmission and protect private information. In particular, the transmitter extracts the interpretable latent representation from the original image by a generative model exploiting the GAN inversion method. We also employ a privacy filter and a knowledge base to erase private information and replace it with natural features in the knowledge base. The simulation results indicate that our proposed method achieves comparable quality of received images while significantly reducing communication costs compared to the existing methods.
Perceptual Image Restoration with High-Quality Priori and Degradation Learning
Mar 04, 2021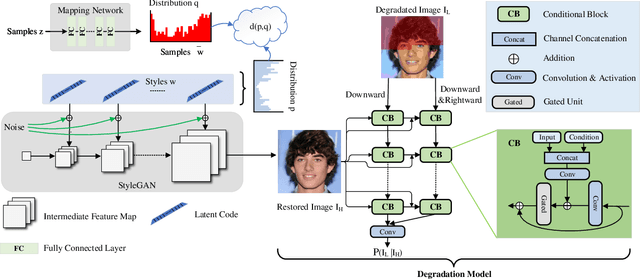

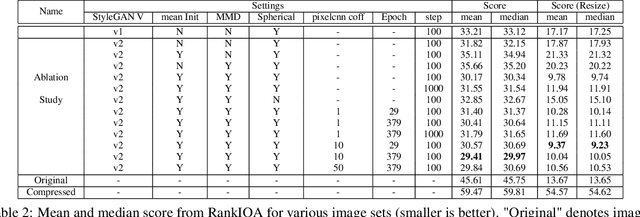
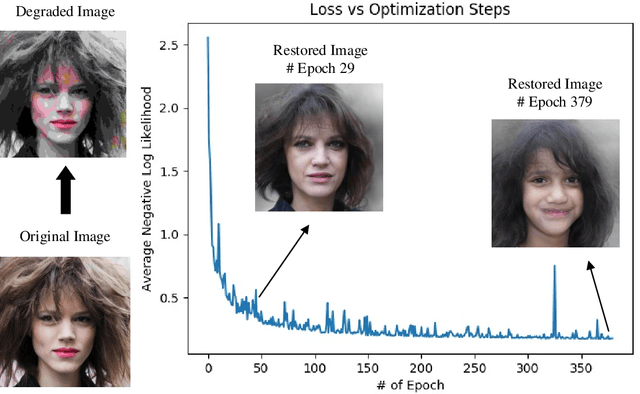
Perceptual image restoration seeks for high-fidelity images that most likely degrade to given images. For better visual quality, previous work proposed to search for solutions within the natural image manifold, by exploiting the latent space of a generative model. However, the quality of generated images are only guaranteed when latent embedding lies close to the prior distribution. In this work, we propose to restrict the feasible region within the prior manifold. This is accomplished with a non-parametric metric for two distributions: the Maximum Mean Discrepancy (MMD). Moreover, we model the degradation process directly as a conditional distribution. We show that our model performs well in measuring the similarity between restored and degraded images. Instead of optimizing the long criticized pixel-wise distance over degraded images, we rely on such model to find visual pleasing images with high probability. Our simultaneous restoration and enhancement framework generalizes well to real-world complicated degradation types. The experimental results on perceptual quality and no-reference image quality assessment (NR-IQA) demonstrate the superior performance of our method.
Saliency Prediction on Omnidirectional Images with Generative Adversarial Imitation Learning
Apr 15, 2019
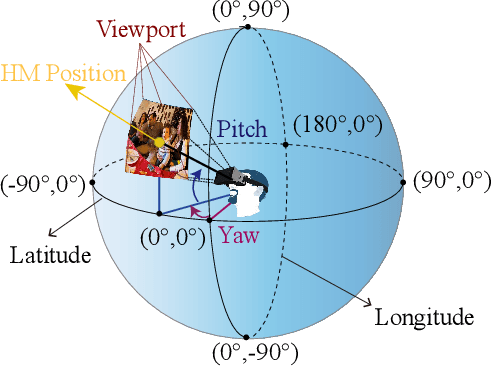


When watching omnidirectional images (ODIs), subjects can access different viewports by moving their heads. Therefore, it is necessary to predict subjects' head fixations on ODIs. Inspired by generative adversarial imitation learning (GAIL), this paper proposes a novel approach to predict saliency of head fixations on ODIs, named SalGAIL. First, we establish a dataset for attention on ODIs (AOI). In contrast to traditional datasets, our AOI dataset is large-scale, which contains the head fixations of 30 subjects viewing 600 ODIs. Next, we mine our AOI dataset and determine three findings: (1) The consistency of head fixations are consistent among subjects, and it grows alongside the increased subject number; (2) The head fixations exist with a front center bias (FCB); and (3) The magnitude of head movement is similar across subjects. According to these findings, our SalGAIL approach applies deep reinforcement learning (DRL) to predict the head fixations of one subject, in which GAIL learns the reward of DRL, rather than the traditional human-designed reward. Then, multi-stream DRL is developed to yield the head fixations of different subjects, and the saliency map of an ODI is generated via convoluting predicted head fixations. Finally, experiments validate the effectiveness of our approach in predicting saliency maps of ODIs, significantly better than 10 state-of-the-art approaches.