 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject-Attribute-Relation Representation based Video Semantic Communication
Jun 15, 2024



With the rapid growth of multimedia data volume, there is an increasing need for efficient video transmission in applications such as virtual reality and future video streaming services. Semantic communication is emerging as a vital technique for ensuring efficient and reliable transmission in low-bandwidth, high-noise settings. However, most current approaches focus on joint source-channel coding (JSCC) that depends on end-to-end training. These methods often lack an interpretable semantic representation and struggle with adaptability to various downstream tasks. In this paper, we introduce the use of object-attribute-relation (OAR) as a semantic framework for videos to facilitate low bit-rate coding and enhance the JSCC process for more effective video transmission. We utilize OAR sequences for both low bit-rate representation and generative video reconstruction. Additionally, we incorporate OAR into the image JSCC model to prioritize communication resources for areas more critical to downstream tasks. Our experiments on traffic surveillance video datasets assess the effectiveness of our approach in terms of video transmission performance. The empirical findings demonstrate that our OAR-based video coding method not only outperforms H.265 coding at lower bit-rates but also synergizes with JSCC to deliver robust and efficient video transmission.
Towards Semantic Communications: Deep Learning-Based Image Semantic Coding
Aug 08, 2022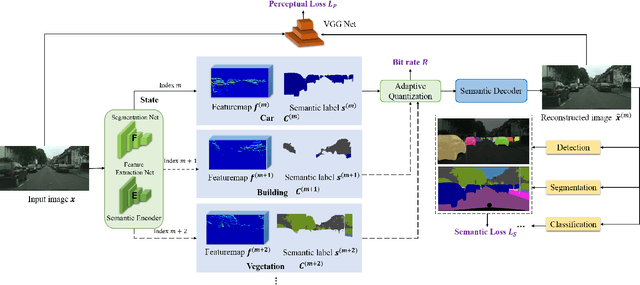

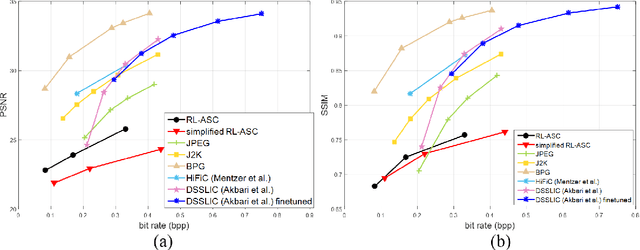
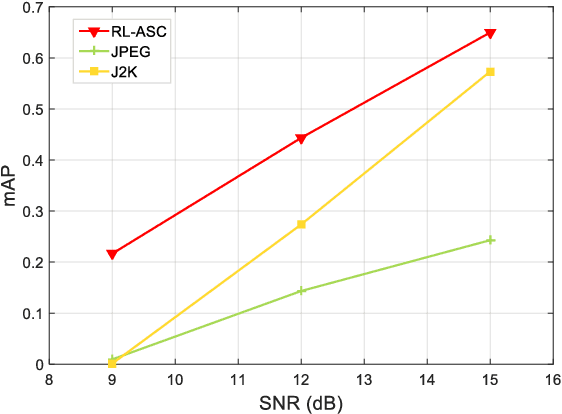
Semantic communications has received growing interest since it can remarkably reduce the amount of data to be transmitted without missing critical information. Most existing works explore the semantic encoding and transmission for text and apply techniques in Natural Language Processing (NLP) to interpret the meaning of the text. In this paper, we conceive the semantic communications for image data that is much more richer in semantics and bandwidth sensitive. We propose an reinforcement learning based adaptive semantic coding (RL-ASC) approach that encodes images beyond pixel level. Firstly, we define the semantic concept of image data that includes the category, spatial arrangement, and visual feature as the representation unit, and propose a convolutional semantic encoder to extract semantic concepts. Secondly, we propose the image reconstruction criterion that evolves from the traditional pixel similarity to semantic similarity and perceptual performance. Thirdly, we design a novel RL-based semantic bit allocation model, whose reward is the increase in rate-semantic-perceptual performance after encoding a certain semantic concept with adaptive quantization level. Thus, the task-related information is preserved and reconstructed properly while less important data is discarded. Finally, we propose the Generative Adversarial Nets (GANs) based semantic decoder that fuses both locally and globally features via an attention module. Experimental results demonstrate that the proposed RL-ASC is noise robust and could reconstruct visually pleasant and semantic consistent image, and saves times of bit cost compared to standard codecs and other deep learning-based image codecs.