 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatic-Dynamic Class-level Perception Consistency in Video Semantic Segmentation
Dec 11, 2024



Video semantic segmentation(VSS) has been widely employed in lots of fields, such as simultaneous localization and mapping, autonomous driving and surveillance. Its core challenge is how to leverage temporal information to achieve better segmentation. Previous efforts have primarily focused on pixel-level static-dynamic contexts matching, utilizing techniques such as optical flow and attention mechanisms. Instead, this paper rethinks static-dynamic contexts at the class level and proposes a novel static-dynamic class-level perceptual consistency (SD-CPC) framework. In this framework, we propose multivariate class prototype with contrastive learning and a static-dynamic semantic alignment module. The former provides class-level constraints for the model, obtaining personalized inter-class features and diversified intra-class features. The latter first establishes intra-frame spatial multi-scale and multi-level correlations to achieve static semantic alignment. Then, based on cross-frame static perceptual differences, it performs two-stage cross-frame selective aggregation to achieve dynamic semantic alignment. Meanwhile, we propose a window-based attention map calculation method that leverages the sparsity of attention points during cross-frame aggregation to reduce computation cost. Extensive experiments on VSPW and Cityscapes datasets show that the proposed approach outperforms state-of-the-art methods. Our implementation will be open-sourced on GitHub.
A Multi-Scale Spatial-Temporal Network for Wireless Video Transmission
Nov 15, 2024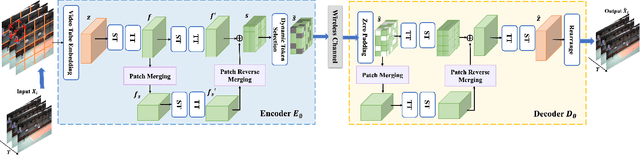
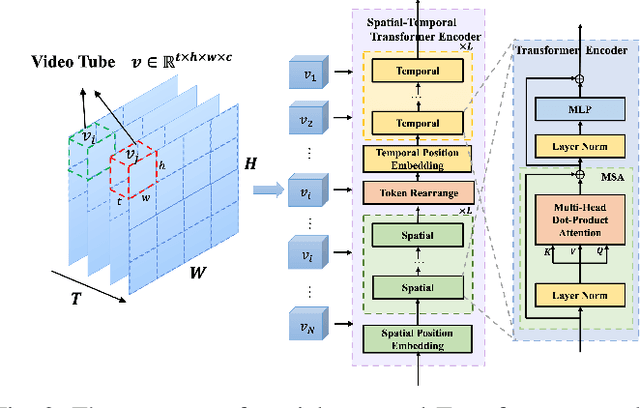
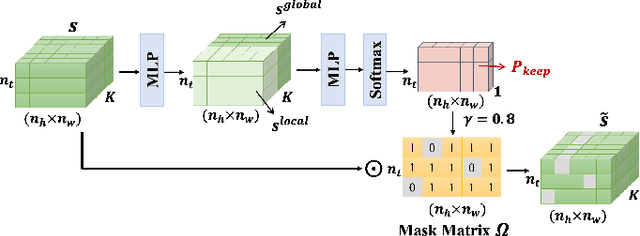
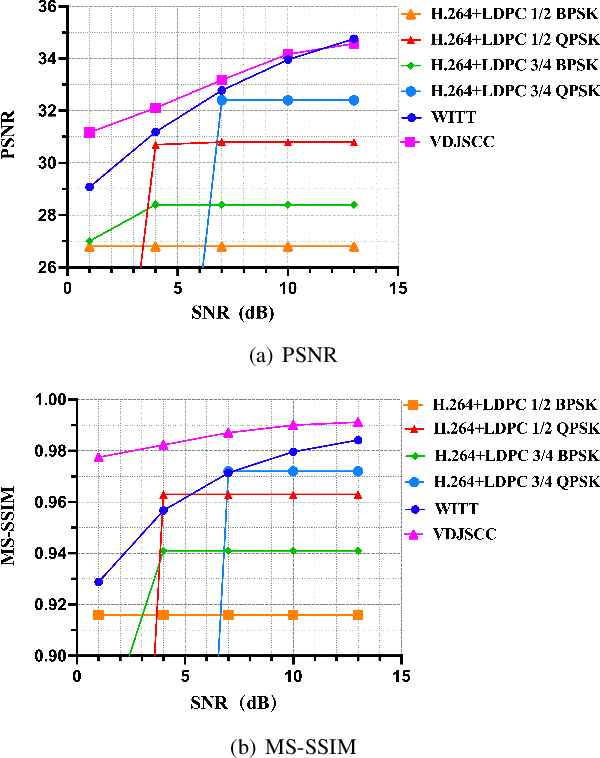
Deep joint source-channel coding (DeepJSCC) has shown promise in wireless transmission of text, speech, and images within the realm of semantic communication. However, wireless video transmission presents greater challenges due to the difficulty of extracting and compactly representing both spatial and temporal features, as well as its significant bandwidth and computational resource requirements. In response, we propose a novel video DeepJSCC (VDJSCC) approach to enable end-to-end video transmission over a wireless channel. Our approach involves the design of a multi-scale vision Transformer encoder and decoder to effectively capture spatial-temporal representations over long-term frames. Additionally, we propose a dynamic token selection module to mask less semantically important tokens from spatial or temporal dimensions, allowing for content-adaptive variable-length video coding by adjusting the token keep ratio. Experimental results demonstrate the effectiveness of our VDJSCC approach compared to digital schemes that use separate source and channel codes, as well as other DeepJSCC schemes, in terms of reconstruction quality and bandwidth reduction.
Channel-Adaptive Wireless Image Semantic Transmission with Learnable Prompts
Nov 15, 2024



Recent developments in Deep learning based Joint Source-Channel Coding (DeepJSCC) have demonstrated impressive capabilities within wireless semantic communications system. However, existing DeepJSCC methodologies exhibit limited generalization ability across varying channel conditions, necessitating the preparation of multiple models. Optimal performance is only attained when the channel status during testing aligns precisely with the training channel status, which is very inconvenient for real-life applications. In this paper, we introduce a novel DeepJSCC framework, termed Prompt JSCC (PJSCC), which incorporates a learnable prompt to implicitly integrate the physical channel state into the transmission system. Specifically, the Channel State Prompt (CSP) module is devised to generate prompts based on diverse SNR and channel distribution models. Through the interaction of latent image features with channel features derived from the CSP module, the DeepJSCC process dynamically adapts to varying channel conditions without necessitating retraining. Comparative analyses against leading DeepJSCC methodologies and traditional separate coding approaches reveal that the proposed PJSCC achieves optimal image reconstruction performance across different SNR settings and various channel models, as assessed by Peak Signal-to-Noise Ratio (PSNR) and Learning-based Perceptual Image Patch Similarity (LPIPS) metrics. Furthermore, in real-world scenarios, PJSCC shows excellent memory efficiency and scalability, rendering it readily deployable on resource-constrained platforms to facilitate semantic communications.
Towards Semantic Communications: Deep Learning-Based Image Semantic Coding
Aug 08, 2022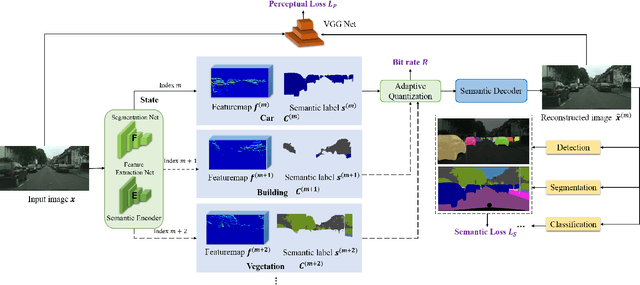

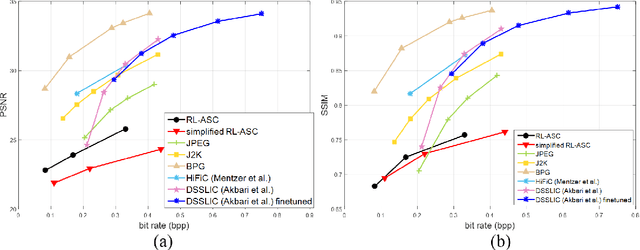
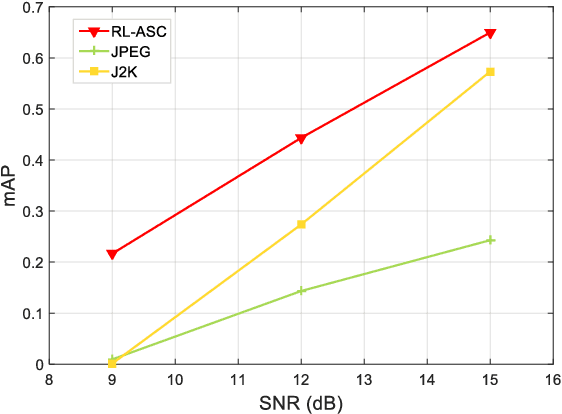
Semantic communications has received growing interest since it can remarkably reduce the amount of data to be transmitted without missing critical information. Most existing works explore the semantic encoding and transmission for text and apply techniques in Natural Language Processing (NLP) to interpret the meaning of the text. In this paper, we conceive the semantic communications for image data that is much more richer in semantics and bandwidth sensitive. We propose an reinforcement learning based adaptive semantic coding (RL-ASC) approach that encodes images beyond pixel level. Firstly, we define the semantic concept of image data that includes the category, spatial arrangement, and visual feature as the representation unit, and propose a convolutional semantic encoder to extract semantic concepts. Secondly, we propose the image reconstruction criterion that evolves from the traditional pixel similarity to semantic similarity and perceptual performance. Thirdly, we design a novel RL-based semantic bit allocation model, whose reward is the increase in rate-semantic-perceptual performance after encoding a certain semantic concept with adaptive quantization level. Thus, the task-related information is preserved and reconstructed properly while less important data is discarded. Finally, we propose the Generative Adversarial Nets (GANs) based semantic decoder that fuses both locally and globally features via an attention module. Experimental results demonstrate that the proposed RL-ASC is noise robust and could reconstruct visually pleasant and semantic consistent image, and saves times of bit cost compared to standard codecs and other deep learning-based image codecs.
A Robust Deep Learning Enabled Semantic Communication System for Text
Jun 06, 2022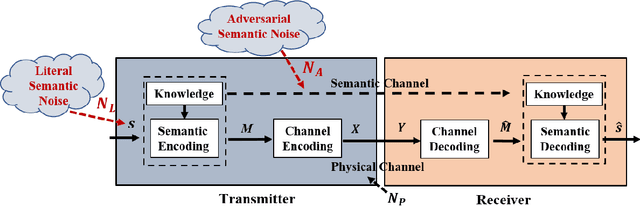
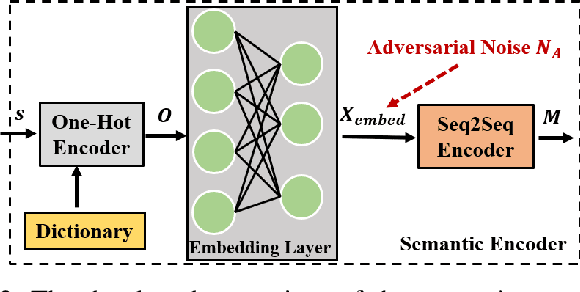
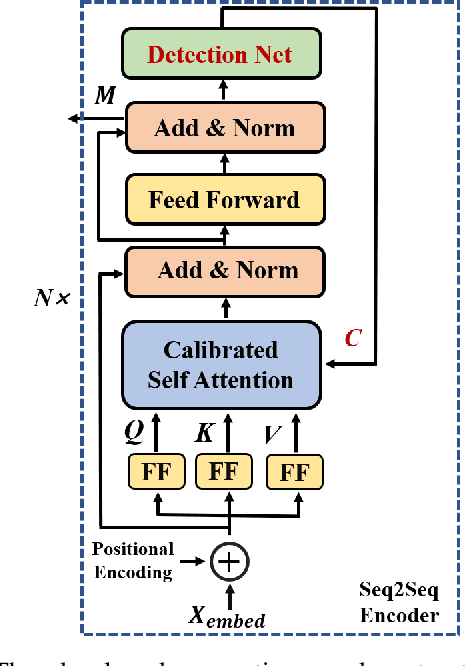

With the advent of the 6G era, the concept of semantic communication has attracted increasing attention. Compared with conventional communication systems, semantic communication systems are not only affected by physical noise existing in the wireless communication environment, e.g., additional white Gaussian noise, but also by semantic noise due to the source and the nature of deep learning-based systems. In this paper, we elaborate on the mechanism of semantic noise. In particular, we categorize semantic noise into two categories: literal semantic noise and adversarial semantic noise. The former is caused by written errors or expression ambiguity, while the latter is caused by perturbations or attacks added to the embedding layer via the semantic channel. To prevent semantic noise from influencing semantic communication systems, we present a robust deep learning enabled semantic communication system (R-DeepSC) that leverages a calibrated self-attention mechanism and adversarial training to tackle semantic noise. Compared with baseline models that only consider physical noise for text transmission, the proposed R-DeepSC achieves remarkable performance in dealing with semantic noise under different signal-to-noise ratios.
Get away from Style: Category-Guided Domain Adaptation for Semantic Segmentation
Mar 29, 2021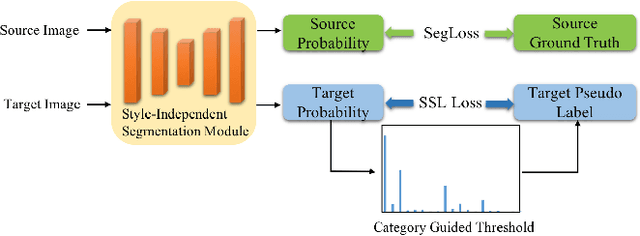
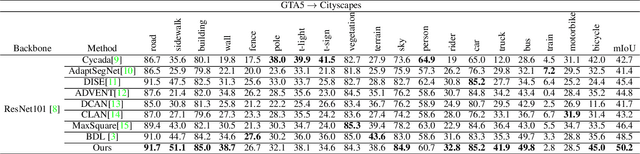
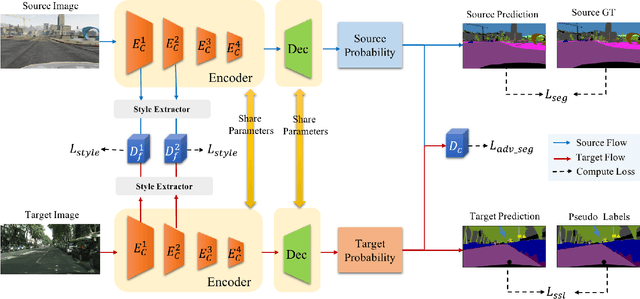

Unsupervised domain adaptation (UDA) becomes more and more popular in tackling real-world problems without ground truth of the target domain. Though a mass of tedious annotation work is not needed, UDA unavoidably faces the problem how to narrow the domain discrepancy to boost the transferring performance. In this paper, we focus on UDA for semantic segmentation task. Firstly, we propose a style-independent content feature extraction mechanism to keep the style information of extracted features in the similar space, since the style information plays a extremely slight role for semantic segmentation compared with the content part. Secondly, to keep the balance of pseudo labels on each category, we propose a category-guided threshold mechanism to choose category-wise pseudo labels for self-supervised learning. The experiments are conducted using GTA5 as the source domain, Cityscapes as the target domain. The results show that our model outperforms the state-of-the-arts with a noticeable gain on cross-domain adaptation tasks.