 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Scale Spatial-Temporal Network for Wireless Video Transmission
Paper and Code
Nov 15, 2024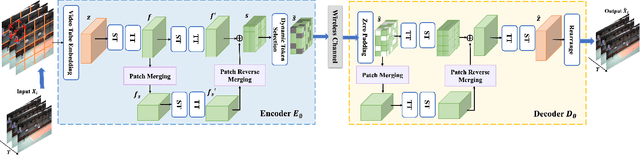
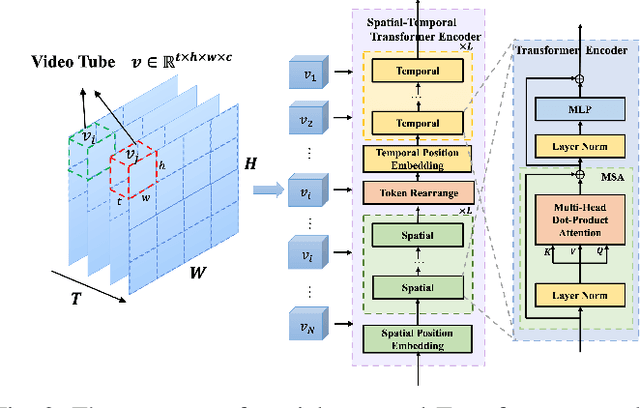
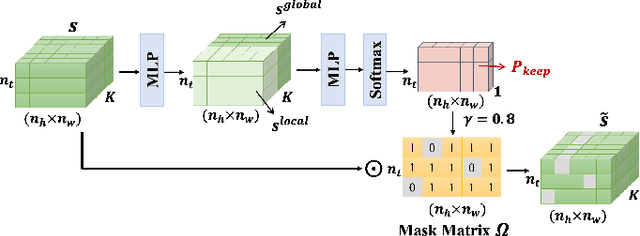
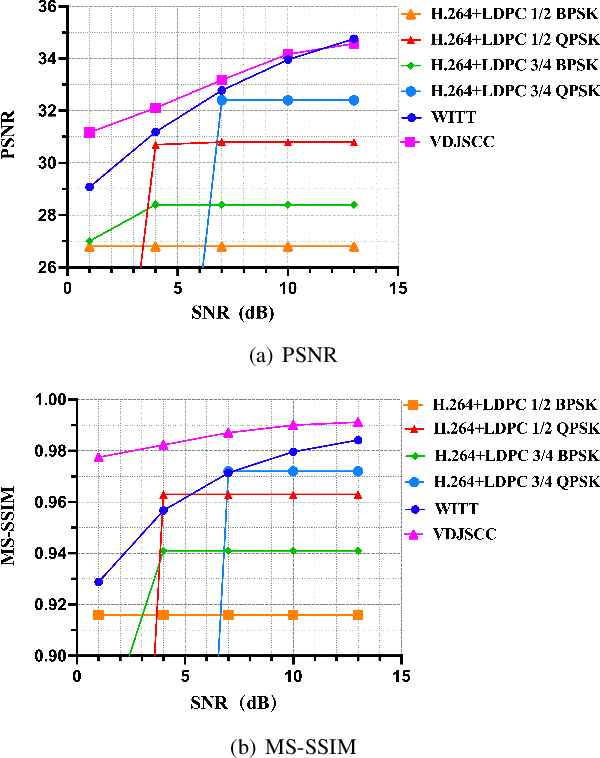
Deep joint source-channel coding (DeepJSCC) has shown promise in wireless transmission of text, speech, and images within the realm of semantic communication. However, wireless video transmission presents greater challenges due to the difficulty of extracting and compactly representing both spatial and temporal features, as well as its significant bandwidth and computational resource requirements. In response, we propose a novel video DeepJSCC (VDJSCC) approach to enable end-to-end video transmission over a wireless channel. Our approach involves the design of a multi-scale vision Transformer encoder and decoder to effectively capture spatial-temporal representations over long-term frames. Additionally, we propose a dynamic token selection module to mask less semantically important tokens from spatial or temporal dimensions, allowing for content-adaptive variable-length video coding by adjusting the token keep ratio. Experimental results demonstrate the effectiveness of our VDJSCC approach compared to digital schemes that use separate source and channel codes, as well as other DeepJSCC schemes, in terms of reconstruction quality and bandwidth reduction.