 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Comprehensive Argument Analysis in Education: Dataset, Tasks, and Method
May 17, 2025



Argument mining has garnered increasing attention over the years, with the recent advancement of Large Language Models (LLMs) further propelling this trend. However, current argument relations remain relatively simplistic and foundational, struggling to capture the full scope of argument information, particularly when it comes to representing complex argument structures in real-world scenarios. To address this limitation, we propose 14 fine-grained relation types from both vertical and horizontal dimensions, thereby capturing the intricate interplay between argument components for a thorough understanding of argument structure. On this basis, we conducted extensive experiments on three tasks: argument component detection, relation prediction, and automated essay grading. Additionally, we explored the impact of writing quality on argument component detection and relation prediction, as well as the connections between discourse relations and argumentative features. The findings highlight the importance of fine-grained argumentative annotations for argumentative writing quality assessment and encourage multi-dimensional argument analysis.
DeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
Assessing the Impact of Conspiracy Theories Using Large Language Models
Dec 09, 2024Measuring the relative impact of CTs is important for prioritizing responses and allocating resources effectively, especially during crises. However, assessing the actual impact of CTs on the public poses unique challenges. It requires not only the collection of CT-specific knowledge but also diverse information from social, psychological, and cultural dimensions. Recent advancements in large language models (LLMs) suggest their potential utility in this context, not only due to their extensive knowledge from large training corpora but also because they can be harnessed for complex reasoning. In this work, we develop datasets of popular CTs with human-annotated impacts. Borrowing insights from human impact assessment processes, we then design tailored strategies to leverage LLMs for performing human-like CT impact assessments. Through rigorous experiments, we textit{discover that an impact assessment mode using multi-step reasoning to analyze more CT-related evidence critically produces accurate results; and most LLMs demonstrate strong bias, such as assigning higher impacts to CTs presented earlier in the prompt, while generating less accurate impact assessments for emotionally charged and verbose CTs.
Channel-Adaptive Wireless Image Semantic Transmission with Learnable Prompts
Nov 15, 2024



Recent developments in Deep learning based Joint Source-Channel Coding (DeepJSCC) have demonstrated impressive capabilities within wireless semantic communications system. However, existing DeepJSCC methodologies exhibit limited generalization ability across varying channel conditions, necessitating the preparation of multiple models. Optimal performance is only attained when the channel status during testing aligns precisely with the training channel status, which is very inconvenient for real-life applications. In this paper, we introduce a novel DeepJSCC framework, termed Prompt JSCC (PJSCC), which incorporates a learnable prompt to implicitly integrate the physical channel state into the transmission system. Specifically, the Channel State Prompt (CSP) module is devised to generate prompts based on diverse SNR and channel distribution models. Through the interaction of latent image features with channel features derived from the CSP module, the DeepJSCC process dynamically adapts to varying channel conditions without necessitating retraining. Comparative analyses against leading DeepJSCC methodologies and traditional separate coding approaches reveal that the proposed PJSCC achieves optimal image reconstruction performance across different SNR settings and various channel models, as assessed by Peak Signal-to-Noise Ratio (PSNR) and Learning-based Perceptual Image Patch Similarity (LPIPS) metrics. Furthermore, in real-world scenarios, PJSCC shows excellent memory efficiency and scalability, rendering it readily deployable on resource-constrained platforms to facilitate semantic communications.
A Multi-Scale Spatial-Temporal Network for Wireless Video Transmission
Nov 15, 2024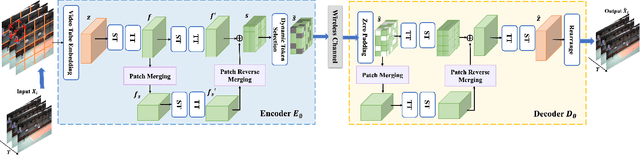
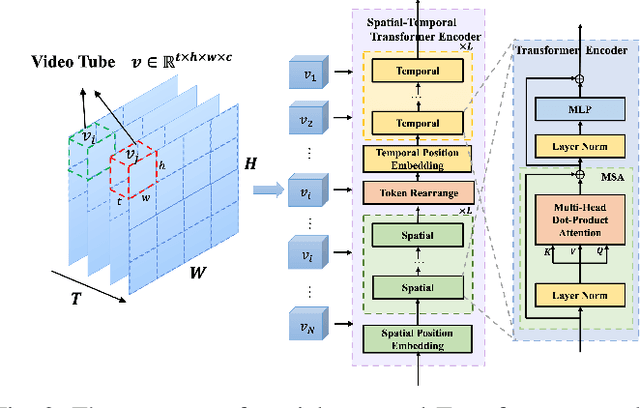
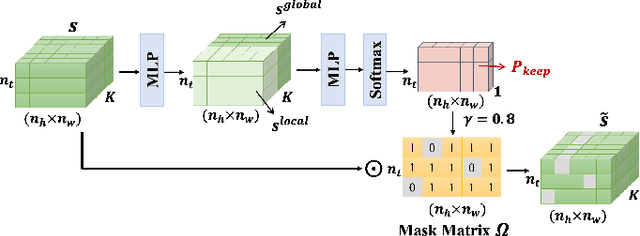
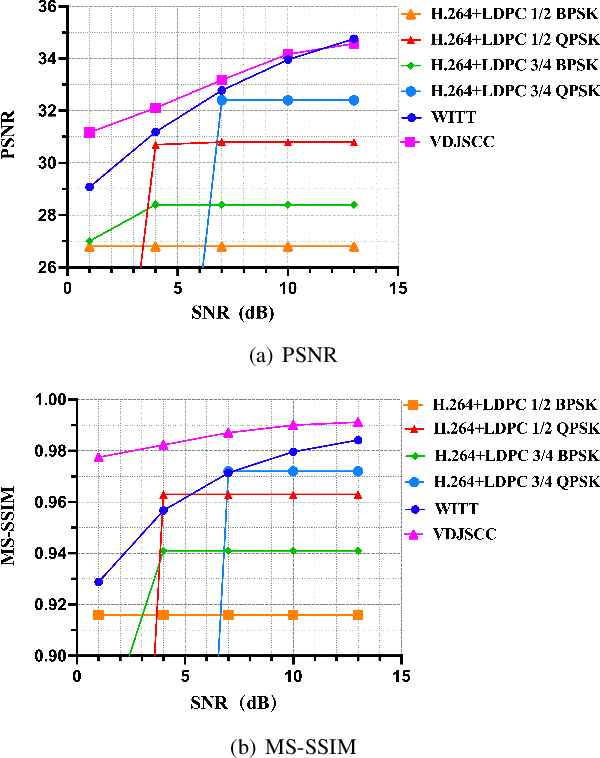
Deep joint source-channel coding (DeepJSCC) has shown promise in wireless transmission of text, speech, and images within the realm of semantic communication. However, wireless video transmission presents greater challenges due to the difficulty of extracting and compactly representing both spatial and temporal features, as well as its significant bandwidth and computational resource requirements. In response, we propose a novel video DeepJSCC (VDJSCC) approach to enable end-to-end video transmission over a wireless channel. Our approach involves the design of a multi-scale vision Transformer encoder and decoder to effectively capture spatial-temporal representations over long-term frames. Additionally, we propose a dynamic token selection module to mask less semantically important tokens from spatial or temporal dimensions, allowing for content-adaptive variable-length video coding by adjusting the token keep ratio. Experimental results demonstrate the effectiveness of our VDJSCC approach compared to digital schemes that use separate source and channel codes, as well as other DeepJSCC schemes, in terms of reconstruction quality and bandwidth reduction.
SeaDAG: Semi-autoregressive Diffusion for Conditional Directed Acyclic Graph Generation
Oct 21, 2024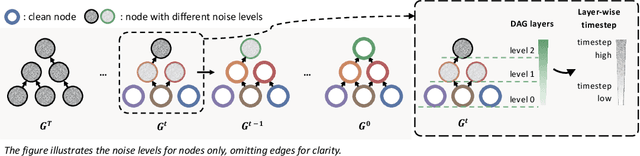
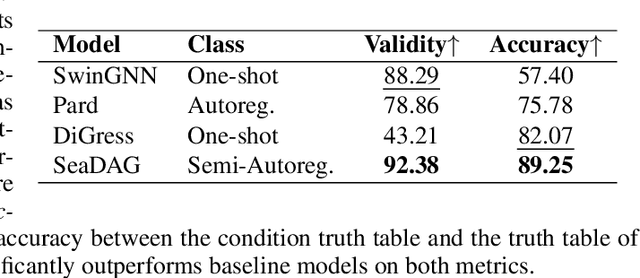
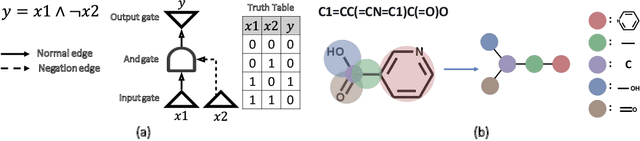
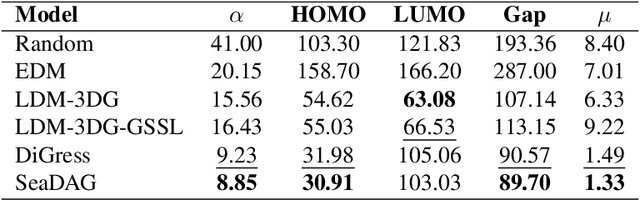
We introduce SeaDAG, a semi-autoregressive diffusion model for conditional generation of Directed Acyclic Graphs (DAGs). Considering their inherent layer-wise structure, we simulate layer-wise autoregressive generation by designing different denoising speed for different layers. Unlike conventional autoregressive generation that lacks a global graph structure view, our method maintains a complete graph structure at each diffusion step, enabling operations such as property control that require the full graph structure. Leveraging this capability, we evaluate the DAG properties during training by employing a graph property decoder. We explicitly train the model to learn graph conditioning with a condition loss, which enhances the diffusion model's capacity to generate graphs that are both realistic and aligned with specified properties. We evaluate our method on two representative conditional DAG generation tasks: (1) circuit generation from truth tables, where precise DAG structures are crucial for realizing circuit functionality, and (2) molecule generation based on quantum properties. Our approach demonstrates promising results, generating high-quality and realistic DAGs that closely align with given conditions.
Correcting misinformation on social media with a large language model
Mar 17, 2024


Misinformation undermines public trust in science and democracy, particularly on social media where inaccuracies can spread rapidly. Experts and laypeople have shown to be effective in correcting misinformation by manually identifying and explaining inaccuracies. Nevertheless, this approach is difficult to scale, a concern as technologies like large language models (LLMs) make misinformation easier to produce. LLMs also have versatile capabilities that could accelerate misinformation correction; however, they struggle due to a lack of recent information, a tendency to produce plausible but false content and references, and limitations in addressing multimodal information. To address these issues, we propose MUSE, an LLM augmented with access to and credibility evaluation of up-to-date information. By retrieving contextual evidence and refutations, MUSE can provide accurate and trustworthy explanations and references. It also describes visuals and conducts multimodal searches for correcting multimodal misinformation. We recruit fact-checking and journalism experts to evaluate corrections to real social media posts across 13 dimensions, ranging from the factuality of explanation to the relevance of references. The results demonstrate MUSE's ability to correct misinformation promptly after appearing on social media; overall, MUSE outperforms GPT-4 by 37% and even high-quality corrections from laypeople by 29%. This work underscores the potential of LLMs to combat real-world misinformation effectively and efficiently.
3D-Printed Hydraulic Fluidic Logic Circuitry for Soft Robots
Jan 30, 2024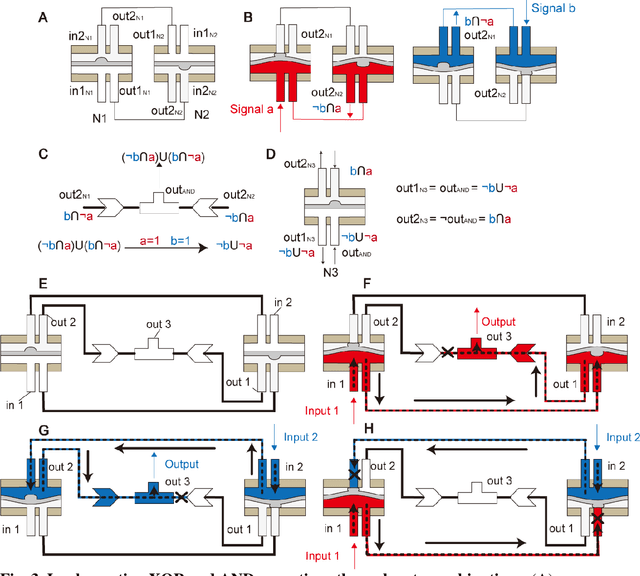
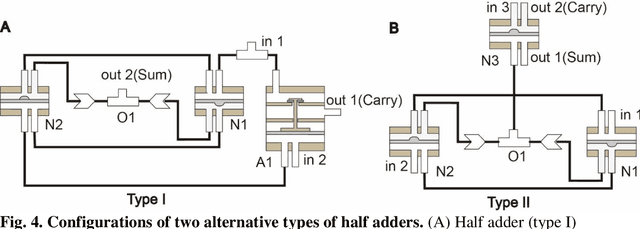
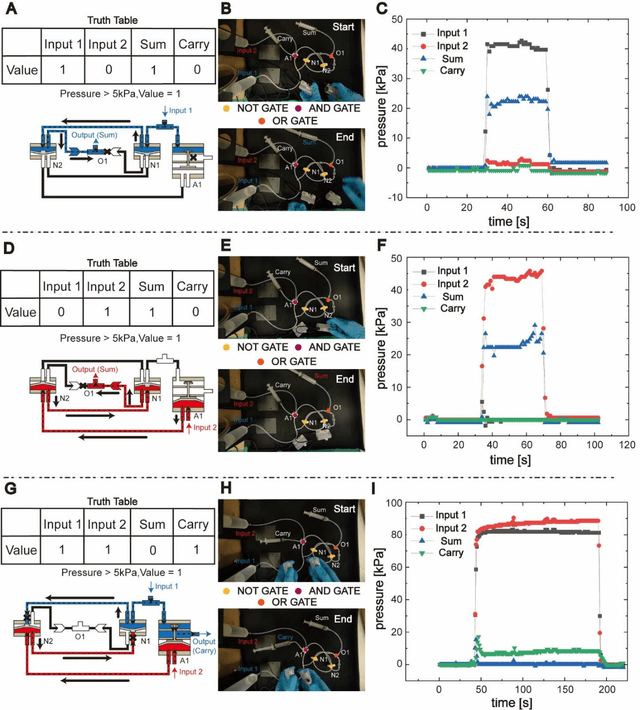
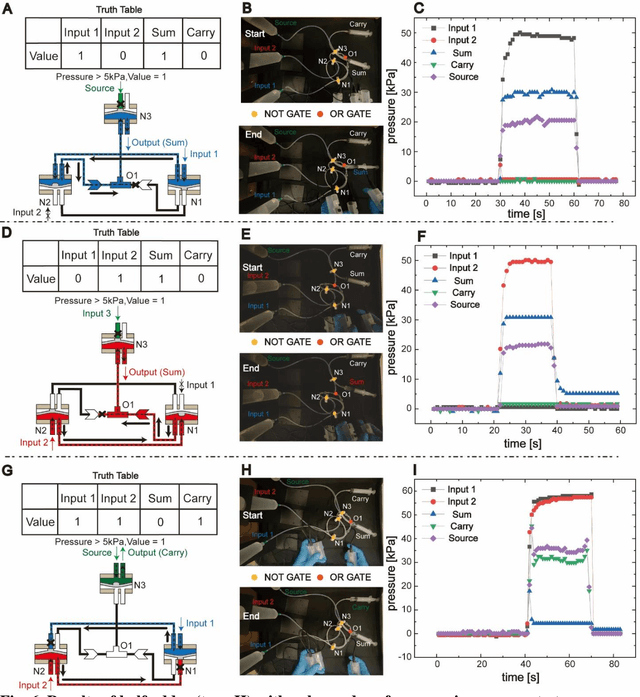
Fluidic logic circuitry analogous to its electric counterpart could potentially provide soft robots with machine intelligence due to its supreme adaptability, dexterity, and seamless compatibility using state-of-the-art additive manufacturing processes. However, conventional microfluidic channel based circuitry suffers from limited driving force, while macroscopic pneumatic logic lacks timely responsivity and desirable accuracy. Producing heavy duty, highly responsive and integrated fluidic soft robotic circuitry for control and actuation purposes for biomedical applications has yet to be accomplished in a hydraulic manner. Here, we present a 3D printed hydraulic fluidic half-adder system, composing of three basic hydraulic fluidic logic building blocks: AND, OR, and NOT gates. Furthermore, a hydraulic soft robotic half-adder system is implemented using an XOR operation and modified dual NOT gate system based on an electrical oscillator structure. This half-adder system possesses binary arithmetic capability as a key component of arithmetic logic unit in modern computers. With slight modifications, it can realize the control over three different directions of deformation of a three degree-of-freedom soft actuation mechanism solely by changing the states of the two fluidic inputs. This hydraulic fluidic system utilizing a small number of inputs to control multiple distinct outputs, can alter the internal state of the circuit solely based on external inputs, holding significant promises for the development of microfluidics, fluidic logic, and intricate internal systems of untethered soft robots with machine intelligence.
ChatGPT is a Potential Zero-Shot Dependency Parser
Oct 25, 2023
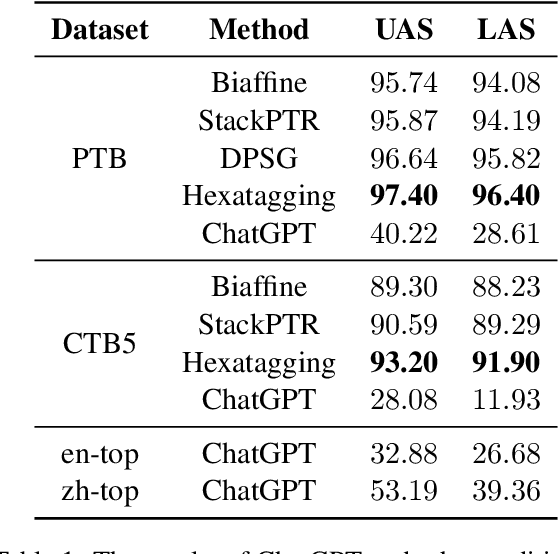
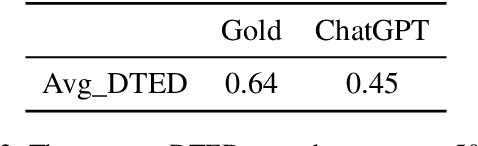

Pre-trained language models have been widely used in dependency parsing task and have achieved significant improvements in parser performance. However, it remains an understudied question whether pre-trained language models can spontaneously exhibit the ability of dependency parsing without introducing additional parser structure in the zero-shot scenario. In this paper, we propose to explore the dependency parsing ability of large language models such as ChatGPT and conduct linguistic analysis. The experimental results demonstrate that ChatGPT is a potential zero-shot dependency parser, and the linguistic analysis also shows some unique preferences in parsing outputs.
Temporal Interest Network for Click-Through Rate Prediction
Aug 15, 2023



The history of user behaviors constitutes one of the most significant characteristics in predicting the click-through rate (CTR), owing to their strong semantic and temporal correlation with the target item. While the literature has individually examined each of these correlations, research has yet to analyze them in combination, that is, the quadruple correlation of (behavior semantics, target semantics, behavior temporal, and target temporal). The effect of this correlation on performance and the extent to which existing methods learn it remain unknown. To address this gap, we empirically measure the quadruple correlation and observe intuitive yet robust quadruple patterns. We measure the learned correlation of several representative user behavior methods, but to our surprise, none of them learn such a pattern, especially the temporal one. In this paper, we propose the Temporal Interest Network (TIN) to capture the quadruple semantic and temporal correlation between behaviors and the target. We achieve this by incorporating target-aware temporal encoding, in addition to semantic embedding, to represent behaviors and the target. Furthermore, we deploy target-aware attention, along with target-aware representation, to explicitly conduct the 4-way interaction. We performed comprehensive evaluations on the Amazon and Alibaba datasets. Our proposed TIN outperforms the best-performing baselines by 0.43\% and 0.29\% on two datasets, respectively. Comprehensive analysis and visualization show that TIN is indeed capable of learning the quadruple correlation effectively, while all existing methods fail to do so. We provide our implementation of TIN in Tensorflow.