 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Gradient Bayesian Filtering: Geometry-Aware Filter for Dynamical Systems
May 04, 2026Bayesian filtering is a cornerstone of state estimation in complex systems such as aerospace systems, yet exact solutions are available only for linear Gaussian models. In practice,nonlinear systems are handled through tractable approximations,with Gaussian filters such as the extended and unscented Kalman filters being among the most widely used methods. This tutorial revisits Gaussian filtering from an information-geometric perspective, viewing the prediction and measurement update steps as inference procedures over state distributions. Within this framework, we introduce a geometry-aware Gaussian filtering approach that leverages natural gradient descent on the statistical manifold of Gaussian distributions. The resulting Natural Gradient Gaussian Approximation (NANO) filter iteratively refines the posterior mean and covariance while respecting the intrinsic geometry of the Gaussian family and preserving the positive definiteness of the covariance matrix. We further highlight fundamental connections to the classical Kalman filtering, showing that a single natural-gradient step exactly recovers the Kalman measurement update in the linear-Gaussian case. The practical implications of the proposed framework are illustrated through case studies in representative nonlinear estimation problems,including satellite attitude estimation, simultaneous localization and mapping, and state estimation for robotic systems including quadruped and humanoid robots.
Natural Gradient Gaussian Approximation Filter on Lie Groups for Robot State Estimation
Apr 11, 2026Accurate state estimation for robotic systems evolving on Lie group manifolds, such as legged robots, is a prerequisite for achieving agile control. However, this task is challenged by nonlinear observation models defined on curved manifolds, where existing filters rely on local linearization in the tangent space to handle such nonlinearity, leading to accumulated estimation errors. To address this limitation, we reformulate manifold filtering as a parameter optimization problem over a Gaussian-distributed increment variable, thereby avoiding linearization. Under this formulation, the increment can be mapped to the Lie group through the exponential operator, where it acts multiplicatively on the prior estimate to yield the posterior state. We further propose a natural gradient optimization scheme for solving this problem, whose iteration process leverages the Fisher information matrix of the increment variable to account for the curvature of the tangent space. This results in an iterative algorithm named the Natural Gradient Gaussian Approximation on Lie Groups (NANO-L) filter. Leveraging the perturbation model in Lie derivative, we prove that for the invariant observation model widely adopted in robotic localization tasks, the covariance update in NANO-L admits an exact closed-form solution, eliminating the need for iterative updates thus improving computational efficiency. Hardware experiments on a Unitree GO2 legged robot operating across different terrains demonstrate that NANO-L achieves approximately 40% lower estimation error than commonly used filters at a comparable computational cost.
MARS-Dragonfly: Agile and Robust Flight Control of Modular Aerial Robot Systems
Apr 07, 2026Modular Aerial Robot Systems (MARS) comprise multiple drone units with reconfigurable connected formations, providing high adaptability to diverse mission scenarios, fault conditions, and payload capacities. However, existing control algorithms for MARS rely on simplified quasi-static models and rule-based allocation, which generate discontinuous and unbounded motor commands. This leads to attitude error accumulation as the number of drone units scales, ultimately causing severe oscillations during docking, separation, and waypoint tracking. To address these limitations, we first design a compact mechanical system that enables passive docking, detection-free passive locking, and magnetic-assisted separation using a single micro servo. Second, we introduce a force-torque-equivalent and polytope-constraint virtual quadrotor that explicitly models feasible wrench sets. Together, these abstractions capture the full MARS dynamics and enable existing quadrotor controllers to be applied across different configurations. We further optimize the yaw angle that maximizes control authority to enhance agility. Third, building on this abstraction, we design a two-stage predictive-allocation pipeline: a constrained predictive tracker computes virtual inputs while respecting force/torque bounds, and a dynamic allocator maps these inputs to individual modules with balanced objectives to produce smooth, trackable motor commands. Simulations across over 10 configurations and real-world experiments demonstrate stable docking, locking, and separation, as well as effective control performance. To our knowledge, this is the first real-world demonstration of MARS achieving agile flight and transport with 40 deg peak pitch while maintaining an average position error of 0.0896 m. The video is available at: https://youtu.be/yqjccrIpz5o
One-Step Sampler for Boltzmann Distributions via Drifting
Mar 18, 2026We present a drifting-based framework for amortized sampling of Boltzmann distributions defined by energy functions. The method trains a one-step neural generator by projecting samples along a Gaussian-smoothed score field from the current model distribution toward the target Boltzmann distribution. For targets specified only up to an unknown normalization constant, we derive a practical target-side drift from a smoothed energy and use two estimators: a local importance-sampling mean-shift estimator and a second-order curvature-corrected approximation. Combined with a mini-batch Gaussian mean-shift estimate of the sampler-side smoothed score, this yields a simple stop-gradient objective for stable one-step training. On a four-mode Gaussian-mixture Boltzmann target, our sampler achieves mean error $0.0754$, covariance error $0.0425$, and RBF MMD $0.0020$. Additional double-well and banana targets show that the same formulation also handles nonconvex and curved low-energy geometries. Overall, the results support drifting as an effective way to amortize iterative sampling from Boltzmann distributions into a single forward pass at test time.
CoINS: Counterfactual Interactive Navigation via Skill-Aware VLM
Jan 07, 2026Recent Vision-Language Models (VLMs) have demonstrated significant potential in robotic planning. However, they typically function as semantic reasoners, lacking an intrinsic understanding of the specific robot's physical capabilities. This limitation is particularly critical in interactive navigation, where robots must actively modify cluttered environments to create traversable paths. Existing VLM-based navigators are predominantly confined to passive obstacle avoidance, failing to reason about when and how to interact with objects to clear blocked paths. To bridge this gap, we propose Counterfactual Interactive Navigation via Skill-aware VLM (CoINS), a hierarchical framework that integrates skill-aware reasoning and robust low-level execution. Specifically, we fine-tune a VLM, named InterNav-VLM, which incorporates skill affordance and concrete constraint parameters into the input context and grounds them into a metric-scale environmental representation. By internalizing the logic of counterfactual reasoning through fine-tuning on the proposed InterNav dataset, the model learns to implicitly evaluate the causal effects of object removal on navigation connectivity, thereby determining interaction necessity and target selection. To execute the generated high-level plans, we develop a comprehensive skill library through reinforcement learning, specifically introducing traversability-oriented strategies to manipulate diverse objects for path clearance. A systematic benchmark in Isaac Sim is proposed to evaluate both the reasoning and execution aspects of interactive navigation. Extensive simulations and real-world experiments demonstrate that CoINS significantly outperforms representative baselines, achieving a 17\% higher overall success rate and over 80\% improvement in complex long-horizon scenarios compared to the best-performing baseline
NANO-SLAM : Natural Gradient Gaussian Approximation for Vehicle SLAM
Apr 27, 2025



Accurate localization is a challenging task for autonomous vehicles, particularly in GPS-denied environments such as urban canyons and tunnels. In these scenarios, simultaneous localization and mapping (SLAM) offers a more robust alternative to GPS-based positioning, enabling vehicles to determine their position using onboard sensors and surrounding environment's landmarks. Among various vehicle SLAM approaches, Rao-Blackwellized particle filter (RBPF) stands out as one of the most widely adopted methods due to its efficient solution with logarithmic complexity relative to the map size. RBPF approximates the posterior distribution of the vehicle pose using a set of Monte Carlo particles through two main steps: sampling and importance weighting. The key to effective sampling lies in solving a distribution that closely approximates the posterior, known as the sampling distribution, to accelerate convergence. Existing methods typically derive this distribution via linearization, which introduces significant approximation errors due to the inherent nonlinearity of the system. To address this limitation, we propose a novel vehicle SLAM method called \textit{N}atural Gr\textit{a}dient Gaussia\textit{n} Appr\textit{o}ximation (NANO)-SLAM, which avoids linearization errors by modeling the sampling distribution as the solution to an optimization problem over Gaussian parameters and solving it using natural gradient descent. This approach improves the accuracy of the sampling distribution and consequently enhances localization performance. Experimental results on the long-distance Sydney Victoria Park vehicle SLAM dataset show that NANO-SLAM achieves over 50\% improvement in localization accuracy compared to the most widely used vehicle SLAM algorithms, with minimal additional computational cost.
Robust State Estimation for Legged Robots with Dual Beta Kalman Filter
Nov 18, 2024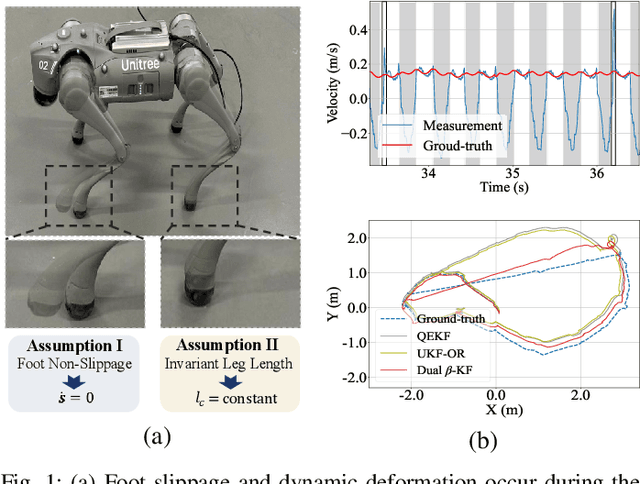
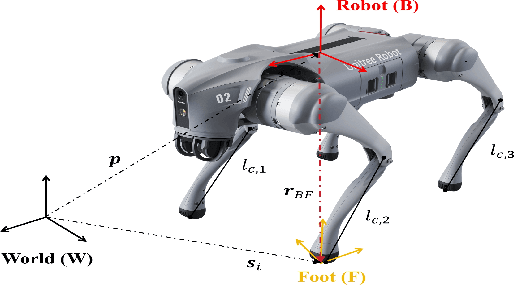
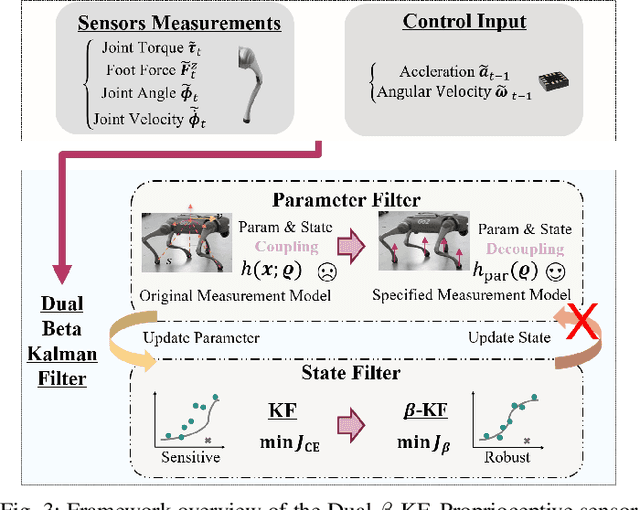

Existing state estimation algorithms for legged robots that rely on proprioceptive sensors often overlook foot slippage and leg deformation in the physical world, leading to large estimation errors. To address this limitation, we propose a comprehensive measurement model that accounts for both foot slippage and variable leg length by analyzing the relative motion between foot contact points and the robot's body center. We show that leg length is an observable quantity, meaning that its value can be explicitly inferred by designing an auxiliary filter. To this end, we introduce a dual estimation framework that iteratively employs a parameter filter to estimate the leg length parameters and a state filter to estimate the robot's state. To prevent error accumulation in this iterative framework, we construct a partial measurement model for the parameter filter using the leg static equation. This approach ensures that leg length estimation relies solely on joint torques and foot contact forces, avoiding the influence of state estimation errors on the parameter estimation. Unlike leg length which can be directly estimated, foot slippage cannot be measured directly with the current sensor configuration. However, since foot slippage occurs at a low frequency, it can be treated as outliers in the measurement data. To mitigate the impact of these outliers, we propose the beta Kalman filter (beta KF), which redefines the estimation loss in canonical Kalman filtering using beta divergence. This divergence can assign low weights to outliers in an adaptive manner, thereby enhancing the robustness of the estimation algorithm. These techniques together form the dual beta-Kalman filter (Dual beta KF), a novel algorithm for robust state estimation in legged robots. Experimental results on the Unitree GO2 robot demonstrate that the Dual beta KF significantly outperforms state-of-the-art methods.
Collecting Larg-Scale Robotic Datasets on a High-Speed Mobile Platform
Aug 01, 2024Mobile robotics datasets are essential for research on robotics, for example for research on Simultaneous Localization and Mapping (SLAM). Therefore the ShanghaiTech Mapping Robot was constructed, that features a multitude high-performance sensors and a 16-node cluster to collect all this data. That robot is based on a Clearpath Husky mobile base with a maximum speed of 1 meter per second. This is fine for indoor datasets, but to collect large-scale outdoor datasets a faster platform is needed. This system paper introduces our high-speed mobile platform for data collection. The mapping robot is secured on the rear-steered flatbed car with maximum field of view. Additionally two encoders collect odometry data from two of the car wheels and an external sensor plate houses a downlooking RGB and event camera. With this setup a dataset of more than 10km in the underground parking garage and the outside of our campus was collected and is published with this paper.
Convolutional Unscented Kalman Filter for Multi-Object Tracking with Outliers
Jun 03, 2024
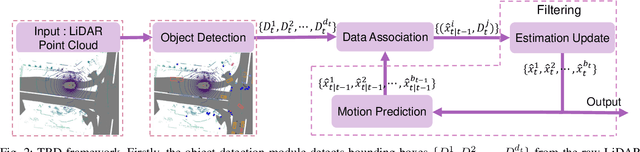
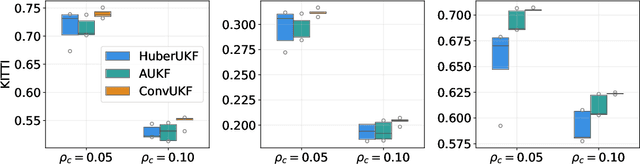
Multi-object tracking (MOT) is an essential technique for navigation in autonomous driving. In tracking-by-detection systems, biases, false positives, and misses, which are referred to as outliers, are inevitable due to complex traffic scenarios. Recent tracking methods are based on filtering algorithms that overlook these outliers, leading to reduced tracking accuracy or even loss of the objects trajectory. To handle this challenge, we adopt a probabilistic perspective, regarding the generation of outliers as misspecification between the actual distribution of measurement data and the nominal measurement model used for filtering. We further demonstrate that, by designing a convolutional operation, we can mitigate this misspecification. Incorporating this operation into the widely used unscented Kalman filter (UKF) in commonly adopted tracking algorithms, we derive a variant of the UKF that is robust to outliers, called the convolutional UKF (ConvUKF). We show that ConvUKF maintains the Gaussian conjugate property, thus allowing for real-time tracking. We also prove that ConvUKF has a bounded tracking error in the presence of outliers, which implies robust stability. The experimental results on the KITTI and nuScenes datasets show improved accuracy compared to representative baseline algorithms for MOT tasks.
Convolutional Bayesian Filtering
Mar 30, 2024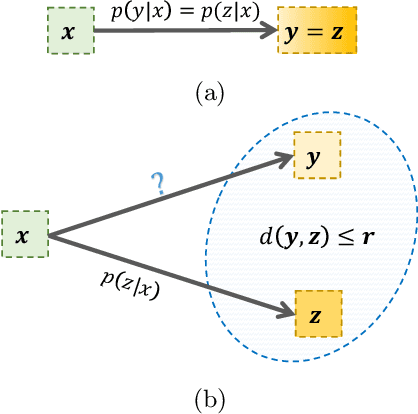
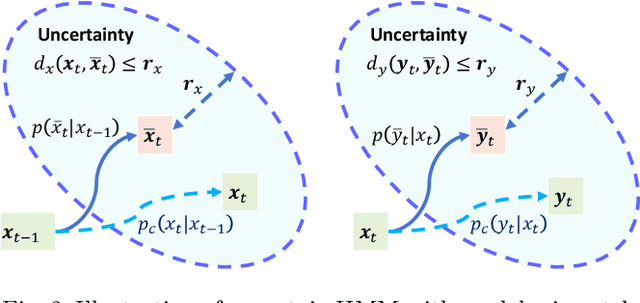
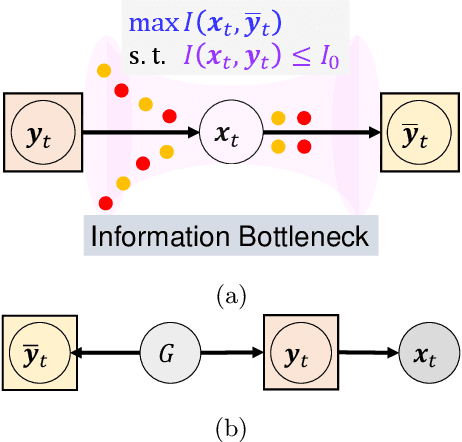
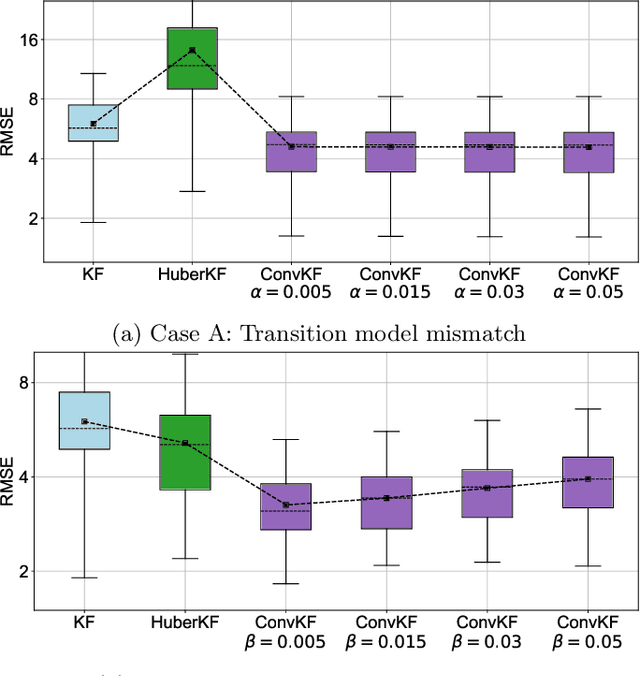
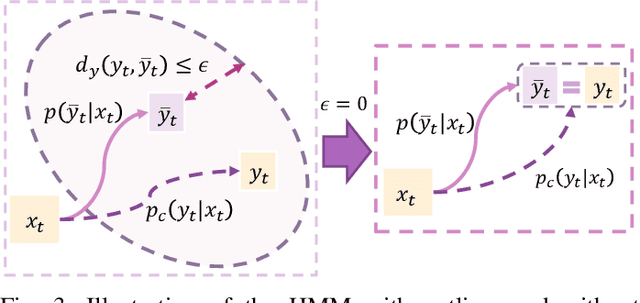
Bayesian filtering serves as the mainstream framework of state estimation in dynamic systems. Its standard version utilizes total probability rule and Bayes' law alternatively, where how to define and compute conditional probability is critical to state distribution inference. Previously, the conditional probability is assumed to be exactly known, which represents a measure of the occurrence probability of one event, given the second event. In this paper, we find that by adding an additional event that stipulates an inequality condition, we can transform the conditional probability into a special integration that is analogous to convolution. Based on this transformation, we show that both transition probability and output probability can be generalized to convolutional forms, resulting in a more general filtering framework that we call convolutional Bayesian filtering. This new framework encompasses standard Bayesian filtering as a special case when the distance metric of the inequality condition is selected as Dirac delta function. It also allows for a more nuanced consideration of model mismatch by choosing different types of inequality conditions. For instance, when the distance metric is defined in a distributional sense, the transition probability and output probability can be approximated by simply rescaling them into fractional powers. Under this framework, a robust version of Kalman filter can be constructed by only altering the noise covariance matrix, while maintaining the conjugate nature of Gaussian distributions. Finally, we exemplify the effectiveness of our approach by reshaping classic filtering algorithms into convolutional versions, including Kalman filter, extended Kalman filter, unscented Kalman filter and particle filter.