 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Soccer Skills for Humanoid Robots: A Progressive Perception-Action Framework
Feb 05, 2026Soccer presents a significant challenge for humanoid robots, demanding tightly integrated perception-action capabilities for tasks like perception-guided kicking and whole-body balance control. Existing approaches suffer from inter-module instability in modular pipelines or conflicting training objectives in end-to-end frameworks. We propose Perception-Action integrated Decision-making (PAiD), a progressive architecture that decomposes soccer skill acquisition into three stages: motion-skill acquisition via human motion tracking, lightweight perception-action integration for positional generalization, and physics-aware sim-to-real transfer. This staged decomposition establishes stable foundational skills, avoids reward conflicts during perception integration, and minimizes sim-to-real gaps. Experiments on the Unitree G1 demonstrate high-fidelity human-like kicking with robust performance under diverse conditions-including static or rolling balls, various positions, and disturbances-while maintaining consistent execution across indoor and outdoor scenarios. Our divide-and-conquer strategy advances robust humanoid soccer capabilities and offers a scalable framework for complex embodied skill acquisition. The project page is available at https://soccer-humanoid.github.io/.
Differential Barometric Altimetry for Submeter Vertical Localization and Floor Recognition Indoors
Jan 05, 2026Accurate altitude estimation and reliable floor recognition are critical for mobile robot localization and navigation within complex multi-storey environments. In this paper, we present a robust, low-cost vertical estimation framework leveraging differential barometric sensing integrated within a fully ROS-compliant software package. Our system simultaneously publishes real-time altitude data from both a stationary base station and a mobile sensor, enabling precise and drift-free vertical localization. Empirical evaluations conducted in challenging scenarios -- such as fully enclosed stairwells and elevators, demonstrate that our proposed barometric pipeline achieves sub-meter vertical accuracy (RMSE: 0.29 m) and perfect (100%) floor-level identification. In contrast, our results confirm that standalone height estimates, obtained solely from visual- or LiDAR-based SLAM odometry, are insufficient for reliable vertical localization. The proposed ROS-compatible barometric module thus provides a practical and cost-effective solution for robust vertical awareness in real-world robotic deployments. The implementation of our method is released as open source at https://github.com/witsir/differential-barometric.
WiFi-based Global Localization in Large-Scale Environments Leveraging Structural Priors from osmAG
Aug 13, 2025Global localization is essential for autonomous robotics, especially in indoor environments where the GPS signal is denied. We propose a novel WiFi-based localization framework that leverages ubiquitous wireless infrastructure and the OpenStreetMap Area Graph (osmAG) for large-scale indoor environments. Our approach integrates signal propagation modeling with osmAG's geometric and topological priors. In the offline phase, an iterative optimization algorithm localizes WiFi Access Points (APs) by modeling wall attenuation, achieving a mean localization error of 3.79 m (35.3\% improvement over trilateration). In the online phase, real-time robot localization uses the augmented osmAG map, yielding a mean error of 3.12 m in fingerprinted areas (8.77\% improvement over KNN fingerprinting) and 3.83 m in non-fingerprinted areas (81.05\% improvement). Comparison with a fingerprint-based method shows that our approach is much more space efficient and achieves superior localization accuracy, especially for positions where no fingerprint data are available. Validated across a complex 11,025 &m^2& multi-floor environment, this framework offers a scalable, cost-effective solution for indoor robotic localization, solving the kidnapped robot problem. The code and dataset are available at https://github.com/XuMa369/osmag-wifi-localization.
Adversarial Locomotion and Motion Imitation for Humanoid Policy Learning
Apr 19, 2025Humans exhibit diverse and expressive whole-body movements. However, attaining human-like whole-body coordination in humanoid robots remains challenging, as conventional approaches that mimic whole-body motions often neglect the distinct roles of upper and lower body. This oversight leads to computationally intensive policy learning and frequently causes robot instability and falls during real-world execution. To address these issues, we propose Adversarial Locomotion and Motion Imitation (ALMI), a novel framework that enables adversarial policy learning between upper and lower body. Specifically, the lower body aims to provide robust locomotion capabilities to follow velocity commands while the upper body tracks various motions. Conversely, the upper-body policy ensures effective motion tracking when the robot executes velocity-based movements. Through iterative updates, these policies achieve coordinated whole-body control, which can be extended to loco-manipulation tasks with teleoperation systems. Extensive experiments demonstrate that our method achieves robust locomotion and precise motion tracking in both simulation and on the full-size Unitree H1 robot. Additionally, we release a large-scale whole-body motion control dataset featuring high-quality episodic trajectories from MuJoCo simulations deployable on real robots. The project page is https://almi-humanoid.github.io.
Intelligent LiDAR Navigation: Leveraging External Information and Semantic Maps with LLM as Copilot
Sep 13, 2024Traditional robot navigation systems primarily utilize occupancy grid maps and laser-based sensing technologies, as demonstrated by the popular move_base package in ROS. Unlike robots, humans navigate not only through spatial awareness and physical distances but also by integrating external information, such as elevator maintenance updates from public notification boards and experiential knowledge, like the need for special access through certain doors. With the development of Large Language Models (LLMs), which posses text understanding and intelligence close to human performance, there is now an opportunity to infuse robot navigation systems with a level of understanding akin to human cognition. In this study, we propose using osmAG (Area Graph in OpensStreetMap textual format), an innovative semantic topometric hierarchical map representation, to bridge the gap between the capabilities of ROS move_base and the contextual understanding offered by LLMs. Our methodology employs LLMs as actual copilot in robot navigation, enabling the integration of a broader range of informational inputs while maintaining the robustness of traditional robotic navigation systems. Our code, demo, map, experiment results can be accessed at https://github.com/xiexiexiaoxiexie/Intelligent-LiDAR-Navigation-LLM-as-Copilot.
Collecting Larg-Scale Robotic Datasets on a High-Speed Mobile Platform
Aug 01, 2024Mobile robotics datasets are essential for research on robotics, for example for research on Simultaneous Localization and Mapping (SLAM). Therefore the ShanghaiTech Mapping Robot was constructed, that features a multitude high-performance sensors and a 16-node cluster to collect all this data. That robot is based on a Clearpath Husky mobile base with a maximum speed of 1 meter per second. This is fine for indoor datasets, but to collect large-scale outdoor datasets a faster platform is needed. This system paper introduces our high-speed mobile platform for data collection. The mapping robot is secured on the rear-steered flatbed car with maximum field of view. Additionally two encoders collect odometry data from two of the car wheels and an external sensor plate houses a downlooking RGB and event camera. With this setup a dataset of more than 10km in the underground parking garage and the outside of our campus was collected and is published with this paper.
High-Quality, ROS Compatible Video Encoding and Decoding for High-Definition Datasets
Aug 01, 2024



Robotic datasets are important for scientific benchmarking and developing algorithms, for example for Simultaneous Localization and Mapping (SLAM). Modern robotic datasets feature video data of high resolution and high framerates. Storing and sharing those datasets becomes thus very costly, especially if more than one camera is used for the datasets. It is thus essential to store this video data in a compressed format. This paper investigates the use of modern video encoders for robotic datasets. We provide a software that can replay mp4 videos within ROS 1 and ROS 2 frameworks, supporting the synchronized playback in simulated time. Furthermore, the paper evaluates different encoders and their settings to find optimal configurations in terms of resulting size, quality and encoding time. Through this work we show that it is possible to store and share even highest quality video datasets within reasonable storage constraints.
Benchmarking SLAM Algorithms in the Cloud: The SLAM Hive System
Jun 25, 2024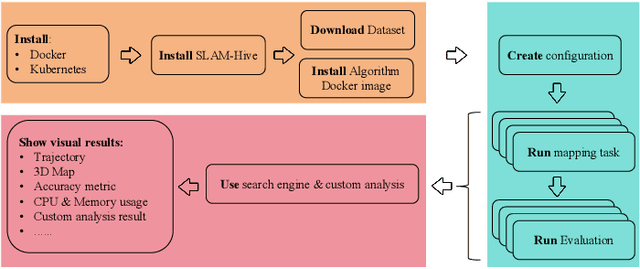
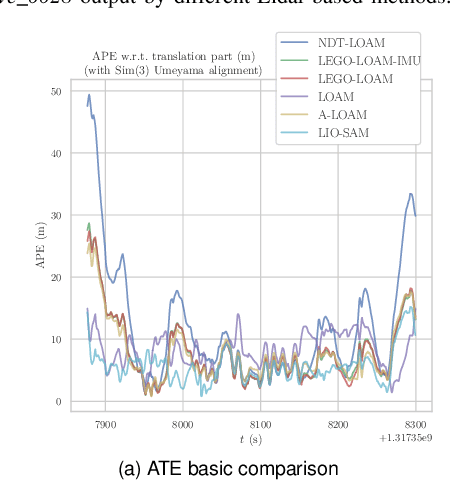
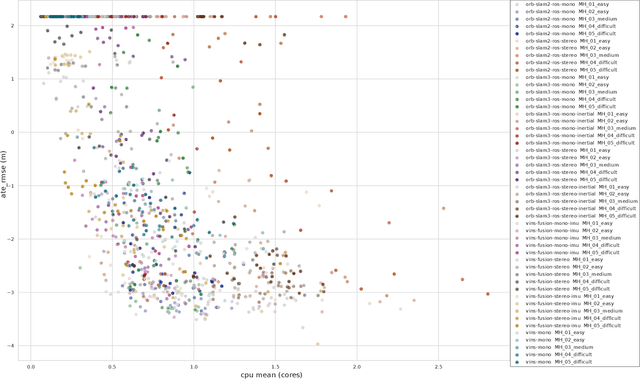
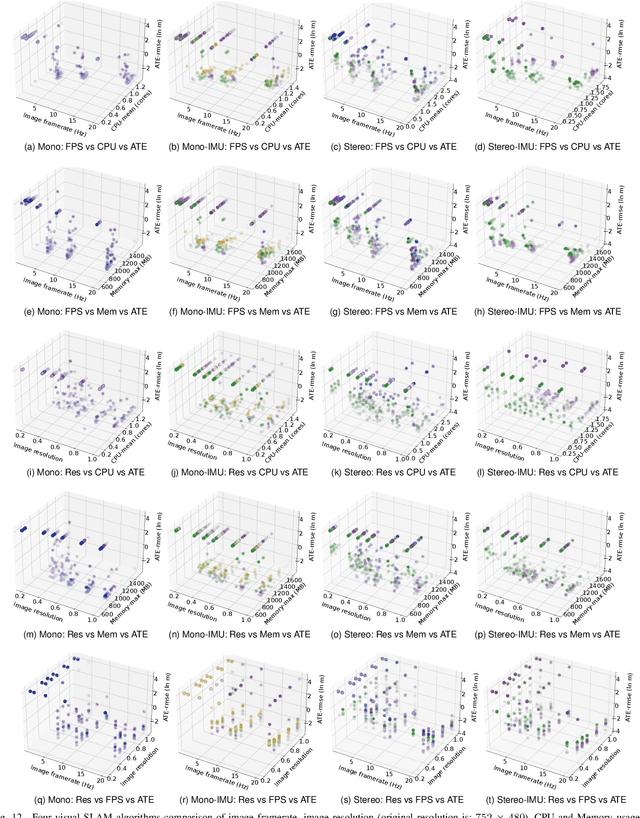
Evaluating the performance of Simultaneous Localization and Mapping (SLAM) algorithms is essential for scientists and users of robotic systems alike. But there are a multitude different permutations of possible options of hardware setups and algorithm configurations, as well as different datasets and algorithms, such that it is infeasible to thoroughly compare SLAM systems against the full state of the art. To solve that we present the SLAM Hive Benchmarking Suite, which is able to analyze SLAM algorithms in thousands of mapping runs, through its utilization of container technology and deployment in the cloud. This paper presents the architecture and open source implementation of SLAM Hive and compares it to existing efforts on SLAM evaluation. We perform mapping runs of many of the most popular visual and LiDAR based SLAM algorithms against commonly used datasets and show how SLAM Hive and then be used to conveniently analyze the results against various aspects. Through this we envision that SLAM Hive can become an essential tool for proper comparisons and evaluations of SLAM algorithms and thus drive the scientific development in the research on SLAM. The open source software as well as a demo to show the live analysis of 100s of mapping runs can be found on our SLAM Hive website.
ShanghaiTech Mapping Robot is All You Need: Robot System for Collecting Universal Ground Vehicle Datasets
Jun 24, 2024This paper presents the ShanghaiTech Mapping Robot, a state-of-the-art unmanned ground vehicle (UGV) designed for collecting comprehensive multi-sensor datasets to support research in robotics, computer vision, and autonomous driving. The robot is equipped with a wide array of sensors including RGB cameras, RGB-D cameras, event-based cameras, IR cameras, LiDARs, mmWave radars, IMUs, ultrasonic range finders, and a GNSS RTK receiver. The sensor suite is integrated onto a specially designed mechanical structure with a centralized power system and a synchronization mechanism to ensure spatial and temporal alignment of the sensor data. A 16-node on-board computing cluster handles sensor control, data collection, and storage. We describe the hardware and software architecture of the robot in detail and discuss the calibration procedures for the various sensors. The capabilities of the platform are demonstrated through an extensive dataset collected in diverse real-world environments. To facilitate research, we make the dataset publicly available along with the associated robot sensor calibration data. Performance evaluations on a set of standard perception and localization tasks showcase the potential of the dataset to support developments in Robot Autonomy.
Detection and Utilization of Reflections in LiDAR Scans Through Plane Optimization and Plane SLAM
Jun 15, 2024
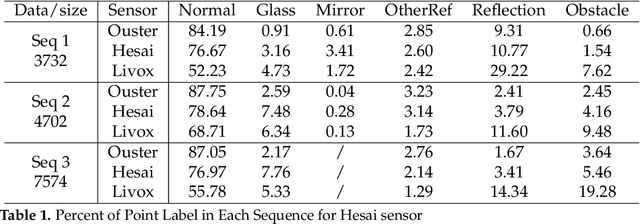

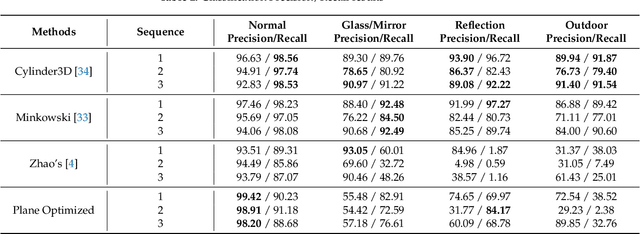
In LiDAR sensing, glass, mirrors and other material often cause inconsistent data readings, because the laser beams may report the distance of the glass, the distance of the object behind the glass or the distance to a reflected object. This causes problems in robotics and 3D reconstruction, especially with respect to localization, mapping and thus navigation. With dual-return LiDARs and other methods, one can detect the glass plane and classify the points in a single scan. In this work we go one step further and construct a global, optimized map of reflective planes, in order to then classify all LiDAR readings at the end. As our experiments will show, this approach provides superior classification accuracy compared to the single scan approach. The code and data for this work are available as open source online.