 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Turn-Taking and Backchannel in Human-Machine Conversations Using Linguistic, Acoustic, and Visual Signals
May 19, 2025This paper addresses the gap in predicting turn-taking and backchannel actions in human-machine conversations using multi-modal signals (linguistic, acoustic, and visual). To overcome the limitation of existing datasets, we propose an automatic data collection pipeline that allows us to collect and annotate over 210 hours of human conversation videos. From this, we construct a Multi-Modal Face-to-Face (MM-F2F) human conversation dataset, including over 1.5M words and corresponding turn-taking and backchannel annotations from approximately 20M frames. Additionally, we present an end-to-end framework that predicts the probability of turn-taking and backchannel actions from multi-modal signals. The proposed model emphasizes the interrelation between modalities and supports any combination of text, audio, and video inputs, making it adaptable to a variety of realistic scenarios. Our experiments show that our approach achieves state-of-the-art performance on turn-taking and backchannel prediction tasks, achieving a 10\% increase in F1-score on turn-taking and a 33\% increase on backchannel prediction. Our dataset and code are publicly available online to ease of subsequent research.
Wavelet-based Global-Local Interaction Network with Cross-Attention for Multi-View Diabetic Retinopathy Detection
Mar 25, 2025Multi-view diabetic retinopathy (DR) detection has recently emerged as a promising method to address the issue of incomplete lesions faced by single-view DR. However, it is still challenging due to the variable sizes and scattered locations of lesions. Furthermore, existing multi-view DR methods typically merge multiple views without considering the correlations and redundancies of lesion information across them. Therefore, we propose a novel method to overcome the challenges of difficult lesion information learning and inadequate multi-view fusion. Specifically, we introduce a two-branch network to obtain both local lesion features and their global dependencies. The high-frequency component of the wavelet transform is used to exploit lesion edge information, which is then enhanced by global semantic to facilitate difficult lesion learning. Additionally, we present a cross-view fusion module to improve multi-view fusion and reduce redundancy. Experimental results on large public datasets demonstrate the effectiveness of our method. The code is open sourced on https://github.com/HuYongting/WGLIN.
VLM-Assisted Continual learning for Visual Question Answering in Self-Driving
Feb 02, 2025



In this paper, we propose a novel approach for solving the Visual Question Answering (VQA) task in autonomous driving by integrating Vision-Language Models (VLMs) with continual learning. In autonomous driving, VQA plays a vital role in enabling the system to understand and reason about its surroundings. However, traditional models often struggle with catastrophic forgetting when sequentially exposed to new driving tasks, such as perception, prediction, and planning, each requiring different forms of knowledge. To address this challenge, we present a novel continual learning framework that combines VLMs with selective memory replay and knowledge distillation, reinforced by task-specific projection layer regularization. The knowledge distillation allows a previously trained model to act as a "teacher" to guide the model through subsequent tasks, minimizing forgetting. Meanwhile, task-specific projection layers calculate the loss based on the divergence of feature representations, ensuring continuity in learning and reducing the shift between tasks. Evaluated on the DriveLM dataset, our framework shows substantial performance improvements, with gains ranging from 21.40% to 32.28% across various metrics. These results highlight the effectiveness of combining continual learning with VLMs in enhancing the resilience and reliability of VQA systems in autonomous driving. We will release our source code.
CausalStock: Deep End-to-end Causal Discovery for News-driven Stock Movement Prediction
Nov 10, 2024



There are two issues in news-driven multi-stock movement prediction tasks that are not well solved in the existing works. On the one hand, "relation discovery" is a pivotal part when leveraging the price information of other stocks to achieve accurate stock movement prediction. Given that stock relations are often unidirectional, such as the "supplier-consumer" relationship, causal relations are more appropriate to capture the impact between stocks. On the other hand, there is substantial noise existing in the news data leading to extracting effective information with difficulty. With these two issues in mind, we propose a novel framework called CausalStock for news-driven multi-stock movement prediction, which discovers the temporal causal relations between stocks. We design a lag-dependent temporal causal discovery mechanism to model the temporal causal graph distribution. Then a Functional Causal Model is employed to encapsulate the discovered causal relations and predict the stock movements. Additionally, we propose a Denoised News Encoder by taking advantage of the excellent text evaluation ability of large language models (LLMs) to extract useful information from massive news data. The experiment results show that CausalStock outperforms the strong baselines for both news-driven multi-stock movement prediction and multi-stock movement prediction tasks on six real-world datasets collected from the US, China, Japan, and UK markets. Moreover, getting benefit from the causal relations, CausalStock could offer a clear prediction mechanism with good explainability.
Collecting Larg-Scale Robotic Datasets on a High-Speed Mobile Platform
Aug 01, 2024Mobile robotics datasets are essential for research on robotics, for example for research on Simultaneous Localization and Mapping (SLAM). Therefore the ShanghaiTech Mapping Robot was constructed, that features a multitude high-performance sensors and a 16-node cluster to collect all this data. That robot is based on a Clearpath Husky mobile base with a maximum speed of 1 meter per second. This is fine for indoor datasets, but to collect large-scale outdoor datasets a faster platform is needed. This system paper introduces our high-speed mobile platform for data collection. The mapping robot is secured on the rear-steered flatbed car with maximum field of view. Additionally two encoders collect odometry data from two of the car wheels and an external sensor plate houses a downlooking RGB and event camera. With this setup a dataset of more than 10km in the underground parking garage and the outside of our campus was collected and is published with this paper.
3D-Printed Hydraulic Fluidic Logic Circuitry for Soft Robots
Jan 30, 2024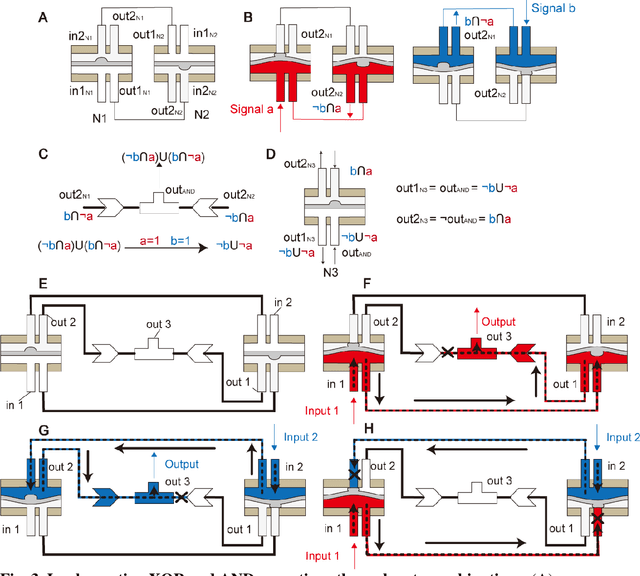
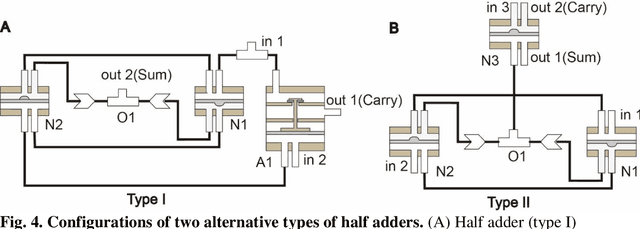
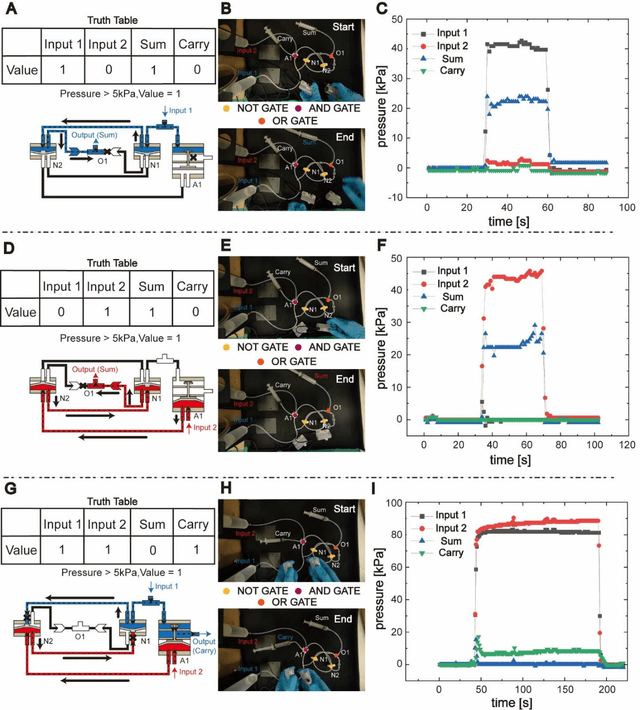
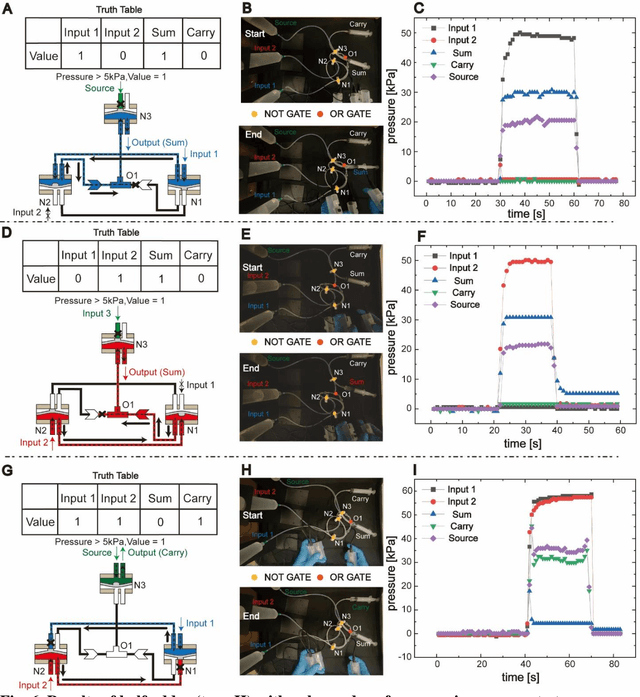
Fluidic logic circuitry analogous to its electric counterpart could potentially provide soft robots with machine intelligence due to its supreme adaptability, dexterity, and seamless compatibility using state-of-the-art additive manufacturing processes. However, conventional microfluidic channel based circuitry suffers from limited driving force, while macroscopic pneumatic logic lacks timely responsivity and desirable accuracy. Producing heavy duty, highly responsive and integrated fluidic soft robotic circuitry for control and actuation purposes for biomedical applications has yet to be accomplished in a hydraulic manner. Here, we present a 3D printed hydraulic fluidic half-adder system, composing of three basic hydraulic fluidic logic building blocks: AND, OR, and NOT gates. Furthermore, a hydraulic soft robotic half-adder system is implemented using an XOR operation and modified dual NOT gate system based on an electrical oscillator structure. This half-adder system possesses binary arithmetic capability as a key component of arithmetic logic unit in modern computers. With slight modifications, it can realize the control over three different directions of deformation of a three degree-of-freedom soft actuation mechanism solely by changing the states of the two fluidic inputs. This hydraulic fluidic system utilizing a small number of inputs to control multiple distinct outputs, can alter the internal state of the circuit solely based on external inputs, holding significant promises for the development of microfluidics, fluidic logic, and intricate internal systems of untethered soft robots with machine intelligence.