 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom GPS Points to Travel Patterns: Flexible and Semantic Trajectory Generation with LLMs
May 28, 2026Urban trajectories play a crucial role in modeling urban dynamics and supporting various smart city applications. However, privacy concerns restrict access to large-scale and high-quality trajectory datasets. Trajectory generation provides a promising alternative by synthesizing realistic data to mitigate privacy risks. However, existing methods fail to explicitly capture travel patterns and can only generate fixed-length trajectories under a single condition. To address these limitations, we propose \textbf{HTP}, which \textbf{H}ierarchically generates \textbf{T}ravel patterns first and then generates GPS \textbf{P}oints by using large language models (LLMs), rather than directly generating GPS points. We first design a trajectory-specific residual quantization variational autoencoder (RQ-VAE) that quantizes micro-level GPS trajectories into compact, macro-level travel pattern tokens in a coarse-to-fine manner. These tokens capture rich segment spatial irregularities, such as point density variations caused by traffic conditions. Then, we extend the LLM vocabulary with travel pattern tokens to align trajectory representations with the LLM input, and apply supervised fine-tuning (SFT) to align the LLM with the trajectory generation task, enabling generation of travel pattern sequences under various conditions. Extensive experiments on two real-world datasets show that HTP outperforms the strongest baseline by an average of 29.78\% in terms of generation quality. Our code is available at https://github.com/slzhou-xy/HTP.
DPEPO: Diverse Parallel Exploration Policy Optimization for LLM-based Agents
Apr 27, 2026Large language model (LLM) agents that follow the sequential "reason-then-act" paradigm have achieved superior performance in many complex tasks.However, these methods suffer from limited exploration and incomplete environmental understanding, as they interact with only a single environment per step. In this paper, we first introduce a novel paradigm that enables an agent to interact with multiple environments simultaneously and share cross-trajectory experiences. Building upon this paradigm, we further propose DPEPO, a reinforcement learning (RL) algorithm that encourages the agent to perform diverse parallel exploration. There are two stages in DPEPO: initial supervised fine-tuning (SFT) imparts basic parallel reasoning and action generation, followed by reinforcement learning stage with a hierarchical reward scheme. We design a parallel trajectory-level success reward and two step-level rewards: Diverse Action Reward and Diverse State Transition Reward, which actively penalize behavioral redundancy and promote broad exploration. Extensive experiments on ALFWorld and ScienceWorld show that DPEPO achieves state-of-the-art (SOTA) success rates, while maintaining comparable efficiency to strong sequential baselines. (Code is available at https://github.com/LePanda026/Code-for-DPEPO)
HTAA: Enhancing LLM Planning via Hybrid Toolset Agentization & Adaptation
Apr 13, 2026Enabling large language models to scale and reliably use hundreds of tools is critical for real-world applications, yet challenging due to the inefficiency and error accumulation inherent in flat tool-calling architectures. To address this, we propose Hybrid Toolset Agentization & Adaptation (HTAA), a hierarchical framework for scalable tool-use planning. We propose a novel toolset agentization paradigm, which encapsulates frequently co-used tools into specialized agent tools, thereby reducing the planner's action space and mitigating redundancy. To ensure effective coordination, we design Asymmetric Planner Adaptation, a trajectory-based training paradigm that aligns the high-level planner with agent tools via backward reconstruction and forward refinement. To validate the performance of HTAA, we conduct experiments on a real-world internal dataset, InfoVerify, based on the POI validation workflow of China's largest online large-scale ride-hailing platform, featuring long-horizon executable tool trajectories. Experiments on InfoVerify and widely-used benchmarks show that HTAA consistently achieves higher task success rates, requires short tool calling trajectories, and significantly reduces context overhead compared to strong baselines. Furthermore, in a production deployment, HTAA substantially reduces manual validation effort and operational cost, demonstrating its practical efficacy.
FAVE: Flow-based Average Velocity Establishment for Sequential Recommendation
Apr 06, 2026Generative recommendation has emerged as a transformative paradigm for capturing the dynamic evolution of user intents in sequential recommendation. While flow-based methods improve the efficiency of diffusion models, they remain hindered by the ``Noise-to-Data'' paradigm, which introduces two critical inefficiencies: prior mismatch, where generation starts from uninformative noise, forcing a lengthy recovery trajectory; and linear redundancy, where iterative solvers waste computation on modeling deterministic preference transitions. To address these limitations, we propose a Flow-based Average Velocity Establishment (Fave) framework for one-step generation recommendation that learns a direct trajectory from an informative prior to the target distribution. Fave is structured via a progressive two-stage training strategy. In Stage 1, we establish a stable preference space through dual-end semantic alignment, applying constraints at both the source (user history) and target (next item) to prevent representation collapse. In Stage 2, we directly resolve the efficiency bottlenecks by introducing a semantic anchor prior, which initializes the flow with a masked embedding from the user's interaction history, providing an informative starting point. Then we learn a global average velocity, consolidating the multi-step trajectory into a single displacement vector, and enforce trajectory straightness via a JVP-based consistency constraint to ensure one-step generation. Extensive experiments on three benchmarks demonstrate that Fave not only achieves state-of-the-art recommendation performance but also delivers an order-of-magnitude improvement in inference efficiency, making it practical for latency-sensitive scenarios.
CoME: Empowering Channel-of-Mobile-Experts with Informative Hybrid-Capabilities Reasoning
Feb 27, 2026Mobile Agents can autonomously execute user instructions, which requires hybrid-capabilities reasoning, including screen summary, subtask planning, action decision and action function. However, existing agents struggle to achieve both decoupled enhancement and balanced integration of these capabilities. To address these challenges, we propose Channel-of-Mobile-Experts (CoME), a novel agent architecture consisting of four distinct experts, each aligned with a specific reasoning stage, CoME activates the corresponding expert to generate output tokens in each reasoning stage via output-oriented activation. To empower CoME with hybrid-capabilities reasoning, we introduce a progressive training strategy: Expert-FT enables decoupling and enhancement of different experts' capability; Router-FT aligns expert activation with the different reasoning stage; CoT-FT facilitates seamless collaboration and balanced optimization across multiple capabilities. To mitigate error propagation in hybrid-capabilities reasoning, we propose InfoGain-Driven DPO (Info-DPO), which uses information gain to evaluate the contribution of each intermediate step, thereby guiding CoME toward more informative reasoning. Comprehensive experiments show that CoME outperforms dense mobile agents and MoE methods on both AITZ and AMEX datasets.
PACE: Prefix-Protected and Difficulty-Aware Compression for Efficient Reasoning
Feb 12, 2026Language Reasoning Models (LRMs) achieve strong performance by scaling test-time computation but often suffer from ``overthinking'', producing excessively long reasoning traces that increase latency and memory usage. Existing LRMs typically enforce conciseness with uniform length penalties, which over-compress crucial early deduction steps at the sequence level and indiscriminately penalize all queries at the group level. To solve these limitations, we propose \textbf{\model}, a dual-level framework for prefix-protected and difficulty-aware compression under hierarchical supervision. At the sequence level, prefix-protected optimization employs decaying mixed rollouts to maintain valid reasoning paths while promoting conciseness. At the group level, difficulty-aware penalty dynamically scales length constraints based on query complexity, maintaining exploration for harder questions while curbing redundancy on easier ones. Extensive experiments on DeepSeek-R1-Distill-Qwen (1.5B/7B) demonstrate that \model achieves a substantial reduction in token usage (up to \textbf{55.7\%}) while simultaneously improving accuracy (up to \textbf{4.1\%}) on math benchmarks, with generalization ability to code, science, and general domains.
R^3: Replay, Reflection, and Ranking Rewards for LLM Reinforcement Learning
Jan 27, 2026Large reasoning models (LRMs) aim to solve diverse and complex problems through structured reasoning. Recent advances in group-based policy optimization methods have shown promise in enabling stable advantage estimation without reliance on process-level annotations. However, these methods rely on advantage gaps induced by high-quality samples within the same batch, which makes the training process fragile and inefficient when intra-group advantages collapse under challenging tasks. To address these problems, we propose a reinforcement learning mechanism named \emph{\textbf{R^3}} that along three directions: (1) a \emph{cross-context \underline{\textbf{R}}eplay} strategy that maintains the intra-group advantage by recalling valuable examples from historical trajectories of the same query, (2) an \emph{in-context self-\underline{\textbf{R}}eflection} mechanism enabling models to refine outputs by leveraging past failures, and (3) a \emph{structural entropy \underline{\textbf{R}}anking reward}, which assigns relative rewards to truncated or failed samples by ranking responses based on token-level entropy patterns, capturing both local exploration and global stability. We implement our method on Deepseek-R1-Distill-Qwen-1.5B and train it on the DeepscaleR-40k in the math domain. Experiments demonstrate our method achieves SoTA performance on several math benchmarks, representing significant improvements and fewer reasoning tokens over the base models. Code and model will be released.
Region-Point Joint Representation for Effective Trajectory Similarity Learning
Nov 17, 2025Recent learning-based methods have reduced the computational complexity of traditional trajectory similarity computation, but state-of-the-art (SOTA) methods still fail to leverage the comprehensive spectrum of trajectory information for similarity modeling. To tackle this problem, we propose \textbf{RePo}, a novel method that jointly encodes \textbf{Re}gion-wise and \textbf{Po}int-wise features to capture both spatial context and fine-grained moving patterns. For region-wise representation, the GPS trajectories are first mapped to grid sequences, and spatial context are captured by structural features and semantic context enriched by visual features. For point-wise representation, three lightweight expert networks extract local, correlation, and continuous movement patterns from dense GPS sequences. Then, a router network adaptively fuses the learned point-wise features, which are subsequently combined with region-wise features using cross-attention to produce the final trajectory embedding. To train RePo, we adopt a contrastive loss with hard negative samples to provide similarity ranking supervision. Experiment results show that RePo achieves an average accuracy improvement of 22.2\% over SOTA baselines across all evaluation metrics.
Efficient Model-Agnostic Continual Learning for Next POI Recommendation
Nov 12, 2025Next point-of-interest (POI) recommendation improves personalized location-based services by predicting users' next destinations based on their historical check-ins. However, most existing methods rely on static datasets and fixed models, limiting their ability to adapt to changes in user behavior over time. To address this limitation, we explore a novel task termed continual next POI recommendation, where models dynamically adapt to evolving user interests through continual updates. This task is particularly challenging, as it requires capturing shifting user behaviors while retaining previously learned knowledge. Moreover, it is essential to ensure efficiency in update time and memory usage for real-world deployment. To this end, we propose GIRAM (Generative Key-based Interest Retrieval and Adaptive Modeling), an efficient, model-agnostic framework that integrates context-aware sustained interests with recent interests. GIRAM comprises four components: (1) an interest memory to preserve historical preferences; (2) a context-aware key encoding module for unified interest key representation; (3) a generative key-based retrieval module to identify diverse and relevant sustained interests; and (4) an adaptive interest update and fusion module to update the interest memory and balance sustained and recent interests. In particular, GIRAM can be seamlessly integrated with existing next POI recommendation models. Experiments on three real-world datasets demonstrate that GIRAM consistently outperforms state-of-the-art methods while maintaining high efficiency in both update time and memory consumption.
Blurred Encoding for Trajectory Representation Learning
Nov 12, 2025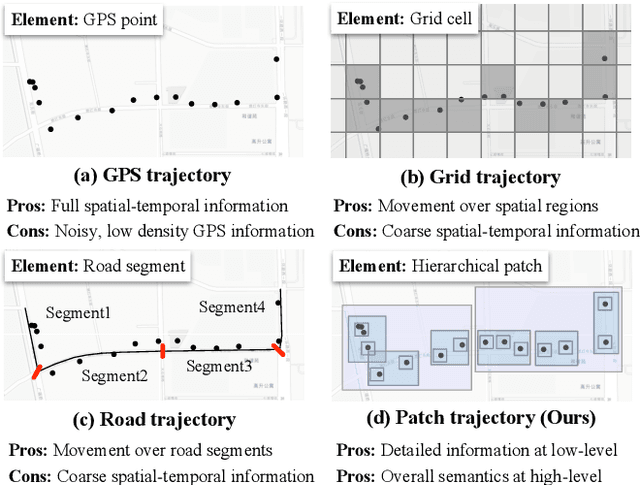

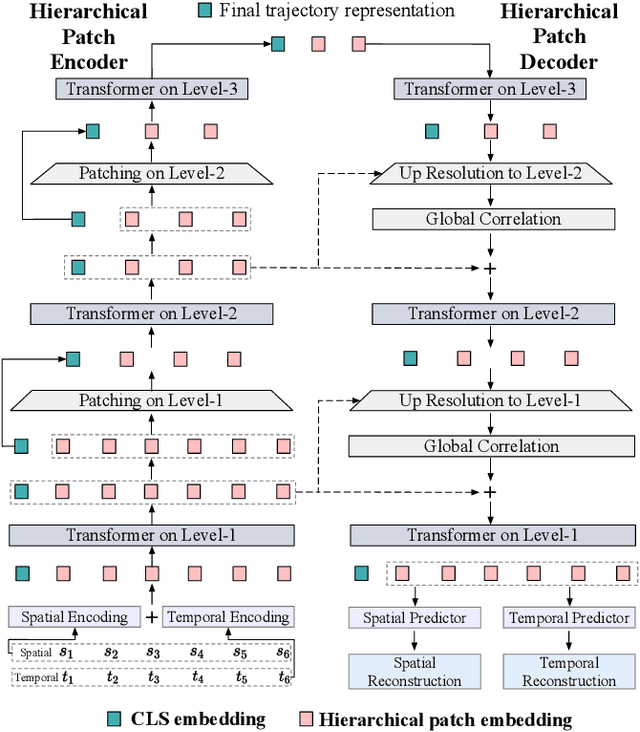
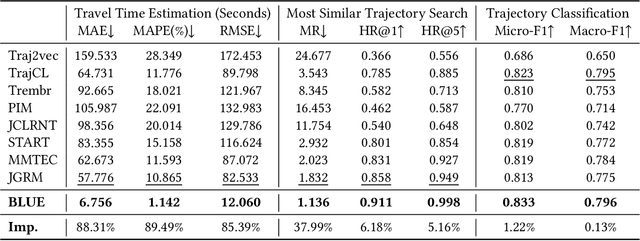
Trajectory representation learning (TRL) maps trajectories to vector embeddings and facilitates tasks such as trajectory classification and similarity search. State-of-the-art (SOTA) TRL methods transform raw GPS trajectories to grid or road trajectories to capture high-level travel semantics, i.e., regions and roads. However, they lose fine-grained spatial-temporal details as multiple GPS points are grouped into a single grid cell or road segment. To tackle this problem, we propose the BLUrred Encoding method, dubbed BLUE, which gradually reduces the precision of GPS coordinates to create hierarchical patches with multiple levels. The low-level patches are small and preserve fine-grained spatial-temporal details, while the high-level patches are large and capture overall travel patterns. To complement different patch levels with each other, our BLUE is an encoder-decoder model with a pyramid structure. At each patch level, a Transformer is used to learn the trajectory embedding at the current level, while pooling prepares inputs for the higher level in the encoder, and up-resolution provides guidance for the lower level in the decoder. BLUE is trained using the trajectory reconstruction task with the MSE loss. We compare BLUE with 8 SOTA TRL methods for 3 downstream tasks, the results show that BLUE consistently achieves higher accuracy than all baselines, outperforming the best-performing baselines by an average of 30.90%. Our code is available at https://github.com/slzhou-xy/BLUE.