 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinRpt: Dataset, Evaluation System and LLM-based Multi-agent Framework for Equity Research Report Generation
Nov 11, 2025While LLMs have shown great success in financial tasks like stock prediction and question answering, their application in fully automating Equity Research Report generation remains uncharted territory. In this paper, we formulate the Equity Research Report (ERR) Generation task for the first time. To address the data scarcity and the evaluation metrics absence, we present an open-source evaluation benchmark for ERR generation - FinRpt. We frame a Dataset Construction Pipeline that integrates 7 financial data types and produces a high-quality ERR dataset automatically, which could be used for model training and evaluation. We also introduce a comprehensive evaluation system including 11 metrics to assess the generated ERRs. Moreover, we propose a multi-agent framework specifically tailored to address this task, named FinRpt-Gen, and train several LLM-based agents on the proposed datasets using Supervised Fine-Tuning and Reinforcement Learning. Experimental results indicate the data quality and metrics effectiveness of the benchmark FinRpt and the strong performance of FinRpt-Gen, showcasing their potential to drive innovation in the ERR generation field. All code and datasets are publicly available.
SE(3)-Equivariant Ternary Complex Prediction Towards Target Protein Degradation
Feb 26, 2025



Targeted protein degradation (TPD) induced by small molecules has emerged as a rapidly evolving modality in drug discovery, targeting proteins traditionally considered "undruggable". Proteolysis-targeting chimeras (PROTACs) and molecular glue degraders (MGDs) are the primary small molecules that induce TPD. Both types of molecules form a ternary complex linking an E3 ligase with a target protein, a crucial step for drug discovery. While significant advances have been made in binary structure prediction for proteins and small molecules, ternary structure prediction remains challenging due to obscure interaction mechanisms and insufficient training data. Traditional methods relying on manually assigned rules perform poorly and are computationally demanding due to extensive random sampling. In this work, we introduce DeepTernary, a novel deep learning-based approach that directly predicts ternary structures in an end-to-end manner using an encoder-decoder architecture. DeepTernary leverages an SE(3)-equivariant graph neural network (GNN) with both intra-graph and ternary inter-graph attention mechanisms to capture intricate ternary interactions from our collected high-quality training dataset, TernaryDB. The proposed query-based Pocket Points Decoder extracts the 3D structure of the final binding ternary complex from learned ternary embeddings, demonstrating state-of-the-art accuracy and speed in existing PROTAC benchmarks without prior knowledge from known PROTACs. It also achieves notable accuracy on the more challenging MGD benchmark under the blind docking protocol. Remarkably, our experiments reveal that the buried surface area calculated from predicted structures correlates with experimentally obtained degradation potency-related metrics. Consequently, DeepTernary shows potential in effectively assisting and accelerating the development of TPDs for previously undruggable targets.
Baichuan4-Finance Technical Report
Dec 17, 2024



Large language models (LLMs) have demonstrated strong capabilities in language understanding, generation, and reasoning, yet their potential in finance remains underexplored due to the complexity and specialization of financial knowledge. In this work, we report the development of the Baichuan4-Finance series, including a comprehensive suite of foundational Baichuan4-Finance-Base and an aligned language model Baichuan4-Finance, which are built upon Baichuan4-Turbo base model and tailored for finance domain. Firstly, we have dedicated significant effort to building a detailed pipeline for improving data quality. Moreover, in the continual pre-training phase, we propose a novel domain self-constraint training strategy, which enables Baichuan4-Finance-Base to acquire financial knowledge without losing general capabilities. After Supervised Fine-tuning and Reinforcement Learning from Human Feedback and AI Feedback, the chat model Baichuan4-Finance is able to tackle various financial certification questions and real-world scenario applications. We evaluate Baichuan4-Finance on many widely used general datasets and two holistic financial benchmarks. The evaluation results show that Baichuan4-Finance-Base surpasses almost all competitive baselines on financial tasks by significant margins without sacrificing performance on general LLM benchmarks. At the same time, Baichuan4-Finance demonstrates even more impressive performance on financial application scenarios, showcasing its potential to foster community innovation in the financial LLM field.
CausalStock: Deep End-to-end Causal Discovery for News-driven Stock Movement Prediction
Nov 10, 2024



There are two issues in news-driven multi-stock movement prediction tasks that are not well solved in the existing works. On the one hand, "relation discovery" is a pivotal part when leveraging the price information of other stocks to achieve accurate stock movement prediction. Given that stock relations are often unidirectional, such as the "supplier-consumer" relationship, causal relations are more appropriate to capture the impact between stocks. On the other hand, there is substantial noise existing in the news data leading to extracting effective information with difficulty. With these two issues in mind, we propose a novel framework called CausalStock for news-driven multi-stock movement prediction, which discovers the temporal causal relations between stocks. We design a lag-dependent temporal causal discovery mechanism to model the temporal causal graph distribution. Then a Functional Causal Model is employed to encapsulate the discovered causal relations and predict the stock movements. Additionally, we propose a Denoised News Encoder by taking advantage of the excellent text evaluation ability of large language models (LLMs) to extract useful information from massive news data. The experiment results show that CausalStock outperforms the strong baselines for both news-driven multi-stock movement prediction and multi-stock movement prediction tasks on six real-world datasets collected from the US, China, Japan, and UK markets. Moreover, getting benefit from the causal relations, CausalStock could offer a clear prediction mechanism with good explainability.
Leveraging 2D Information for Long-term Time Series Forecasting with Vanilla Transformers
May 22, 2024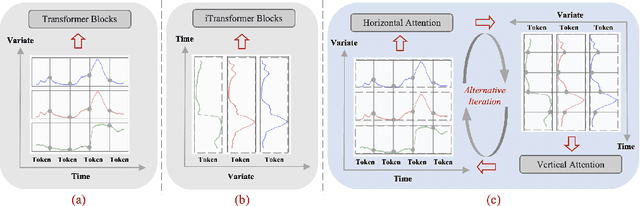
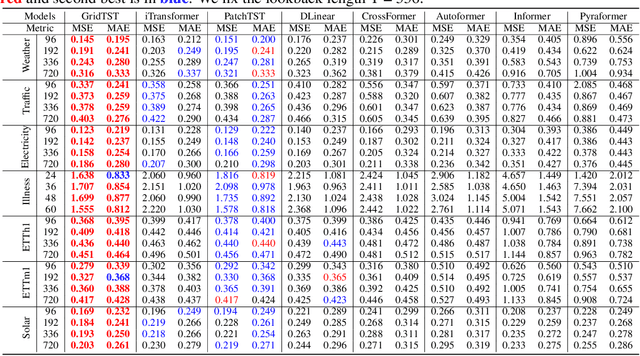
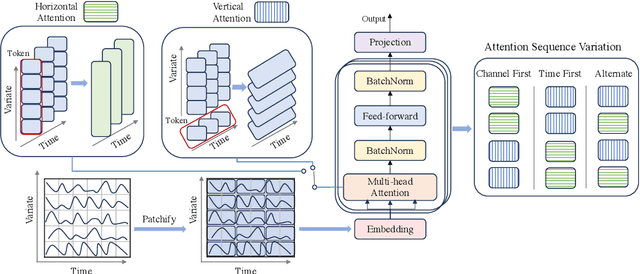
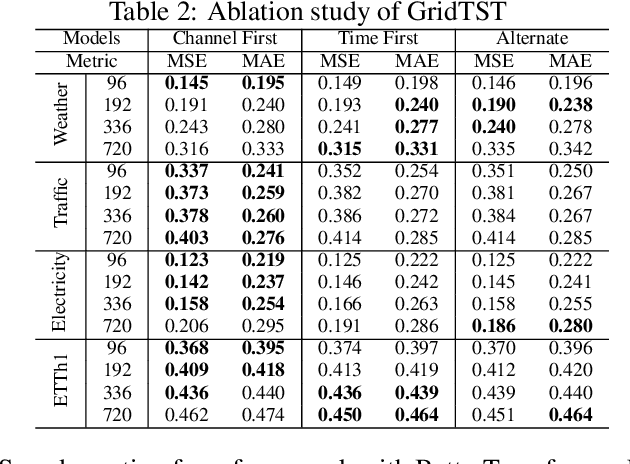
Time series prediction is crucial for understanding and forecasting complex dynamics in various domains, ranging from finance and economics to climate and healthcare. Based on Transformer architecture, one approach involves encoding multiple variables from the same timestamp into a single temporal token to model global dependencies. In contrast, another approach embeds the time points of individual series into separate variate tokens. The former method faces challenges in learning variate-centric representations, while the latter risks missing essential temporal information critical for accurate forecasting. In our work, we introduce GridTST, a model that combines the benefits of two approaches using innovative multi-directional attentions based on a vanilla Transformer. We regard the input time series data as a grid, where the $x$-axis represents the time steps and the $y$-axis represents the variates. A vertical slicing of this grid combines the variates at each time step into a \textit{time token}, while a horizontal slicing embeds the individual series across all time steps into a \textit{variate token}. Correspondingly, a \textit{horizontal attention mechanism} focuses on time tokens to comprehend the correlations between data at various time steps, while a \textit{vertical}, variate-aware \textit{attention} is employed to grasp multivariate correlations. This combination enables efficient processing of information across both time and variate dimensions, thereby enhancing the model's analytical strength. % We also integrate the patch technique, segmenting time tokens into subseries-level patches, ensuring that local semantic information is retained in the embedding. The GridTST model consistently delivers state-of-the-art performance across various real-world datasets.
Selecting Query-bag as Pseudo Relevance Feedback for Information-seeking Conversations
Mar 22, 2024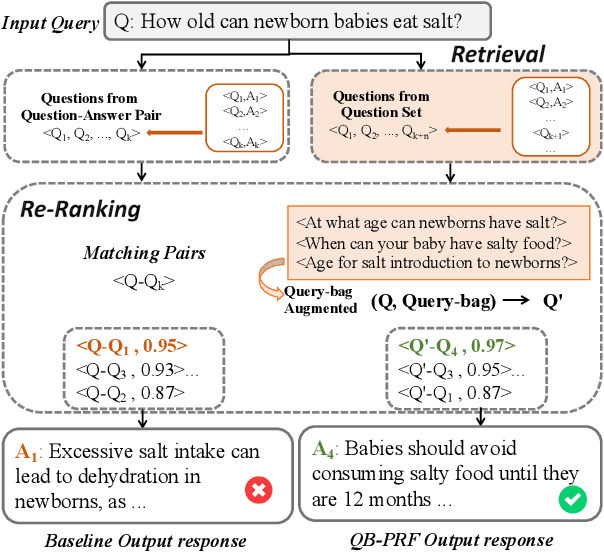

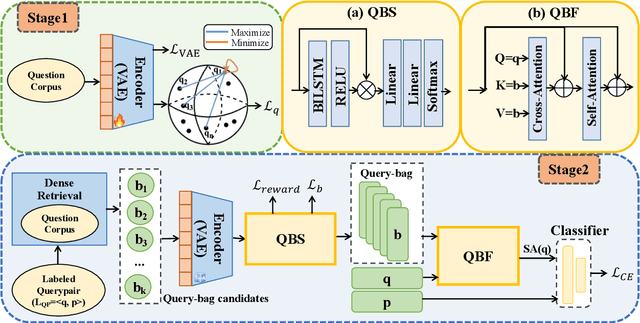
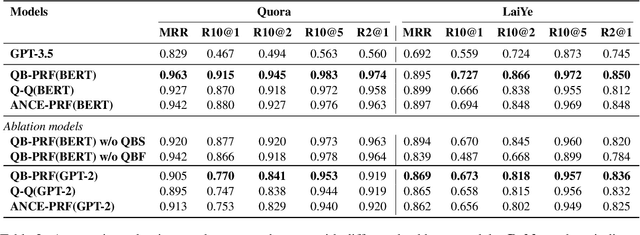
Information-seeking dialogue systems are widely used in e-commerce systems, with answers that must be tailored to fit the specific settings of the online system. Given the user query, the information-seeking dialogue systems first retrieve a subset of response candidates, then further select the best response from the candidate set through re-ranking. Current methods mainly retrieve response candidates based solely on the current query, however, incorporating similar questions could introduce more diverse content, potentially refining the representation and improving the matching process. Hence, in this paper, we proposed a Query-bag based Pseudo Relevance Feedback framework (QB-PRF), which constructs a query-bag with related queries to serve as pseudo signals to guide information-seeking conversations. Concretely, we first propose a Query-bag Selection module (QBS), which utilizes contrastive learning to train the selection of synonymous queries in an unsupervised manner by leveraging the representations learned from pre-trained VAE. Secondly, we come up with a Query-bag Fusion module (QBF) that fuses synonymous queries to enhance the semantic representation of the original query through multidimensional attention computation. We verify the effectiveness of the QB-PRF framework on two competitive pretrained backbone models, including BERT and GPT-2. Experimental results on two benchmark datasets show that our framework achieves superior performance over strong baselines.