 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Tokens Are Created Equal: Query-Efficient Jailbreak Fuzzing for LLMs
Mar 24, 2026Large Language Models(LLMs) are widely deployed, yet are vulnerable to jailbreak prompts that elicit policy-violating outputs. Although prior studies have uncovered these risks, they typically treat all tokens as equally important during prompt mutation, overlooking the varying contributions of individual tokens to triggering model refusals. Consequently, these attacks introduce substantial redundant searching under query-constrained scenarios, reducing attack efficiency and hindering comprehensive vulnerability assessment. In this work, we conduct a token-level analysis of refusal behavior and observe that token contributions are highly skewed rather than uniform. Moreover, we find strong cross-model consistency in refusal tendencies, enabling the use of a surrogate model to estimate token-level contributions to the target model's refusals. Motivated by these findings, we propose TriageFuzz, a token-aware jailbreak fuzzing framework that adapts the fuzz testing approach with a series of customized designs. TriageFuzz leverages a surrogate model to estimate the contribution of individual tokens to refusal behaviors, enabling the identification of sensitive regions within the prompt. Furthermore, it incorporates a refusal-guided evolutionary strategy that adaptively weights candidate prompts with a lightweight scorer to steer the evolution toward bypassing safety constraints. Extensive experiments on six open-source LLMs and three commercial APIs demonstrate that TriageFuzz achieves comparable attack success rates (ASR) with significantly reduced query costs. Notably, it attains a 90% ASR with over 70% fewer queries compared to baselines. Even under an extremely restrictive budget of 25 queries, TriageFuzz outperforms existing methods, improving ASR by 20-40%.
BEACON: Language-Conditioned Navigation Affordance Prediction under Occlusion
Mar 10, 2026Language-conditioned local navigation requires a robot to infer a nearby traversable target location from its current observation and an open-vocabulary, relational instruction. Existing vision-language spatial grounding methods usually rely on vision-language models (VLMs) to reason in image space, producing 2D predictions tied to visible pixels. As a result, they struggle to infer target locations in occluded regions, typically caused by furniture or moving humans. To address this issue, we propose BEACON, which predicts an ego-centric Bird's-Eye View (BEV) affordance heatmap over a bounded local region including occluded areas. Given an instruction and surround-view RGB-D observations from four directions around the robot, BEACON predicts the BEV heatmap by injecting spatial cues into a VLM and fusing the VLM's output with depth-derived BEV features. Using an occlusion-aware dataset built in the Habitat simulator, we conduct detailed experimental analysis to validate both our BEV space formulation and the design choices of each module. Our method improves the accuracy averaged across geodesic thresholds by 22.74 percentage points over the state-of-the-art image-space baseline on the validation subset with occluded target locations. Our project page is: https://xin-yu-gao.github.io/beacon.
TA-KAND: Two-stage Attention Triple Enhancement and U-KAN based Diffusion For Few-shot Knowledge Graph Completion
Dec 13, 2025Knowledge Graphs (KGs), thanks to their concise and efficient triple-based structure, have been widely applied in intelligent question answering, recommender systems and other domains. However, the heterogeneous and multifaceted nature of real-world data inevitably renders the distribution of relations long-tailed, making it crucial to complete missing facts with limited samples. Previous studies mainly based on metric matching or meta learning, yet they either fail to fully exploit neighborhood information in graph or overlook the distributional characteristics of contrastive signals. In this paper, we re-examine the problem from a perspective of generative representation and propose a few-shot knowledge graph completion framework that integrates two-stage attention triple enhancer with U-KAN based diffusion model. Extensive experiments on two public datasets show that our method achieve new state-of-the-art results.
The Devil is in the Prompts: Retrieval-Augmented Prompt Optimization for Text-to-Video Generation
Apr 16, 2025The evolution of Text-to-video (T2V) generative models, trained on large-scale datasets, has been marked by significant progress. However, the sensitivity of T2V generative models to input prompts highlights the critical role of prompt design in influencing generative outcomes. Prior research has predominantly relied on Large Language Models (LLMs) to align user-provided prompts with the distribution of training prompts, albeit without tailored guidance encompassing prompt vocabulary and sentence structure nuances. To this end, we introduce \textbf{RAPO}, a novel \textbf{R}etrieval-\textbf{A}ugmented \textbf{P}rompt \textbf{O}ptimization framework. In order to address potential inaccuracies and ambiguous details generated by LLM-generated prompts. RAPO refines the naive prompts through dual optimization branches, selecting the superior prompt for T2V generation. The first branch augments user prompts with diverse modifiers extracted from a learned relational graph, refining them to align with the format of training prompts via a fine-tuned LLM. Conversely, the second branch rewrites the naive prompt using a pre-trained LLM following a well-defined instruction set. Extensive experiments demonstrate that RAPO can effectively enhance both the static and dynamic dimensions of generated videos, demonstrating the significance of prompt optimization for user-provided prompts. Project website: \href{https://whynothaha.github.io/Prompt_optimizer/RAPO.html}{GitHub}.
SE(3)-Equivariant Ternary Complex Prediction Towards Target Protein Degradation
Feb 26, 2025



Targeted protein degradation (TPD) induced by small molecules has emerged as a rapidly evolving modality in drug discovery, targeting proteins traditionally considered "undruggable". Proteolysis-targeting chimeras (PROTACs) and molecular glue degraders (MGDs) are the primary small molecules that induce TPD. Both types of molecules form a ternary complex linking an E3 ligase with a target protein, a crucial step for drug discovery. While significant advances have been made in binary structure prediction for proteins and small molecules, ternary structure prediction remains challenging due to obscure interaction mechanisms and insufficient training data. Traditional methods relying on manually assigned rules perform poorly and are computationally demanding due to extensive random sampling. In this work, we introduce DeepTernary, a novel deep learning-based approach that directly predicts ternary structures in an end-to-end manner using an encoder-decoder architecture. DeepTernary leverages an SE(3)-equivariant graph neural network (GNN) with both intra-graph and ternary inter-graph attention mechanisms to capture intricate ternary interactions from our collected high-quality training dataset, TernaryDB. The proposed query-based Pocket Points Decoder extracts the 3D structure of the final binding ternary complex from learned ternary embeddings, demonstrating state-of-the-art accuracy and speed in existing PROTAC benchmarks without prior knowledge from known PROTACs. It also achieves notable accuracy on the more challenging MGD benchmark under the blind docking protocol. Remarkably, our experiments reveal that the buried surface area calculated from predicted structures correlates with experimentally obtained degradation potency-related metrics. Consequently, DeepTernary shows potential in effectively assisting and accelerating the development of TPDs for previously undruggable targets.
A Study on Educational Data Analysis and Personalized Feedback Report Generation Based on Tags and ChatGPT
Jan 12, 2025This study introduces a novel method that employs tag annotation coupled with the ChatGPT language model to analyze student learning behaviors and generate personalized feedback. Central to this approach is the conversion of complex student data into an extensive set of tags, which are then decoded through tailored prompts to deliver constructive feedback that encourages rather than discourages students. This methodology focuses on accurately feeding student data into large language models and crafting prompts that enhance the constructive nature of feedback. The effectiveness of this approach was validated through surveys conducted with over 20 mathematics teachers, who confirmed the reliability of the generated reports. This method can be seamlessly integrated into intelligent adaptive learning systems or provided as a tool to significantly reduce the workload of teachers, providing accurate and timely feedback to students. By transforming raw educational data into interpretable tags, this method supports the provision of efficient and timely personalized learning feedback that offers constructive suggestions tailored to individual learner needs.
POINTS1.5: Building a Vision-Language Model towards Real World Applications
Dec 11, 2024



Vision-language models have made significant strides recently, demonstrating superior performance across a range of tasks, e.g. optical character recognition and complex diagram analysis. Building on this trend, we introduce a new vision-language model, POINTS1.5, designed to excel in various real-world applications. POINTS1.5 is an enhancement of POINTS1.0 and incorporates several key innovations: i) We replace the original CLIP vision encoder, which had a fixed image resolution, with a NaViT-style vision encoder that supports native dynamic high resolution. This allows POINTS1.5 to process images of any resolution without needing to split them into tiles. ii) We add bilingual support to POINTS1.5, significantly enhancing its capability in Chinese. Due to the scarcity of open-source Chinese datasets for vision-language models, we collect numerous images from the Internet and annotate them using a combination of manual and automatic methods. iii) We propose a set of rigorous filtering methods for visual instruction tuning datasets. We comprehensively evaluate all these filtering methods, and choose the most effective ones to obtain the final visual instruction tuning set. Thanks to these innovations, POINTS1.5 significantly outperforms POINTS1.0 and demonstrates strong performance across a range of real-world applications. Notably, POINTS1.5-7B is trained on fewer than 4 billion tokens and ranks first on the OpenCompass leaderboard among models with fewer than 10 billion parameters
Non-target Divergence Hypothesis: Toward Understanding Domain Gaps in Cross-Modal Knowledge Distillation
Sep 04, 2024



Compared to single-modal knowledge distillation, cross-modal knowledge distillation faces more severe challenges due to domain gaps between modalities. Although various methods have proposed various solutions to overcome these challenges, there is still limited research on how domain gaps affect cross-modal knowledge distillation. This paper provides an in-depth analysis and evaluation of this issue. We first introduce the Non-Target Divergence Hypothesis (NTDH) to reveal the impact of domain gaps on cross-modal knowledge distillation. Our key finding is that domain gaps between modalities lead to distribution differences in non-target classes, and the smaller these differences, the better the performance of cross-modal knowledge distillation. Subsequently, based on Vapnik-Chervonenkis (VC) theory, we derive the upper and lower bounds of the approximation error for cross-modal knowledge distillation, thereby theoretically validating the NTDH. Finally, experiments on five cross-modal datasets further confirm the validity, generalisability, and applicability of the NTDH.
Towards Realistic Example-based Modeling via 3D Gaussian Stitching
Aug 28, 2024Using parts of existing models to rebuild new models, commonly termed as example-based modeling, is a classical methodology in the realm of computer graphics. Previous works mostly focus on shape composition, making them very hard to use for realistic composition of 3D objects captured from real-world scenes. This leads to combining multiple NeRFs into a single 3D scene to achieve seamless appearance blending. However, the current SeamlessNeRF method struggles to achieve interactive editing and harmonious stitching for real-world scenes due to its gradient-based strategy and grid-based representation. To this end, we present an example-based modeling method that combines multiple Gaussian fields in a point-based representation using sample-guided synthesis. Specifically, as for composition, we create a GUI to segment and transform multiple fields in real time, easily obtaining a semantically meaningful composition of models represented by 3D Gaussian Splatting (3DGS). For texture blending, due to the discrete and irregular nature of 3DGS, straightforwardly applying gradient propagation as SeamlssNeRF is not supported. Thus, a novel sampling-based cloning method is proposed to harmonize the blending while preserving the original rich texture and content. Our workflow consists of three steps: 1) real-time segmentation and transformation of a Gaussian model using a well-tailored GUI, 2) KNN analysis to identify boundary points in the intersecting area between the source and target models, and 3) two-phase optimization of the target model using sampling-based cloning and gradient constraints. Extensive experimental results validate that our approach significantly outperforms previous works in terms of realistic synthesis, demonstrating its practicality. More demos are available at https://ingra14m.github.io/gs_stitching_website.
Spec-Gaussian: Anisotropic View-Dependent Appearance for 3D Gaussian Splatting
Feb 24, 2024
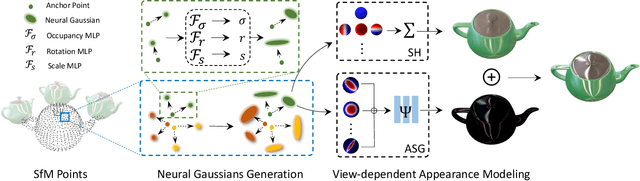
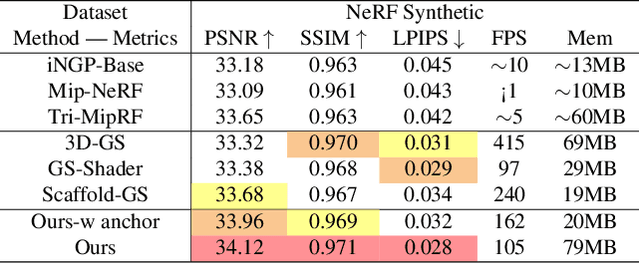
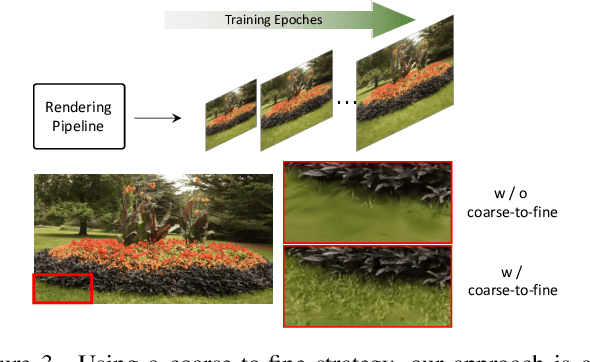
The recent advancements in 3D Gaussian splatting (3D-GS) have not only facilitated real-time rendering through modern GPU rasterization pipelines but have also attained state-of-the-art rendering quality. Nevertheless, despite its exceptional rendering quality and performance on standard datasets, 3D-GS frequently encounters difficulties in accurately modeling specular and anisotropic components. This issue stems from the limited ability of spherical harmonics (SH) to represent high-frequency information. To overcome this challenge, we introduce Spec-Gaussian, an approach that utilizes an anisotropic spherical Gaussian (ASG) appearance field instead of SH for modeling the view-dependent appearance of each 3D Gaussian. Additionally, we have developed a coarse-to-fine training strategy to improve learning efficiency and eliminate floaters caused by overfitting in real-world scenes. Our experimental results demonstrate that our method surpasses existing approaches in terms of rendering quality. Thanks to ASG, we have significantly improved the ability of 3D-GS to model scenes with specular and anisotropic components without increasing the number of 3D Gaussians. This improvement extends the applicability of 3D GS to handle intricate scenarios with specular and anisotropic surfaces.