 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPR: Towards a Generative Pre-trained One-Model Paradigm for Large-Scale Advertising Recommendation
Nov 13, 2025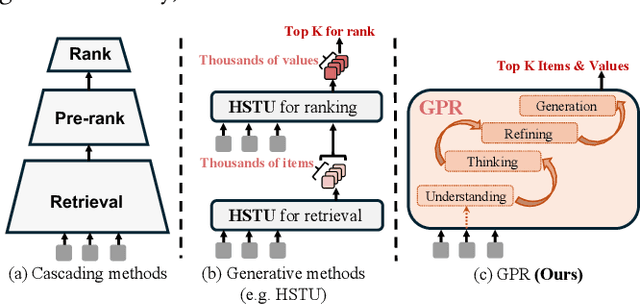
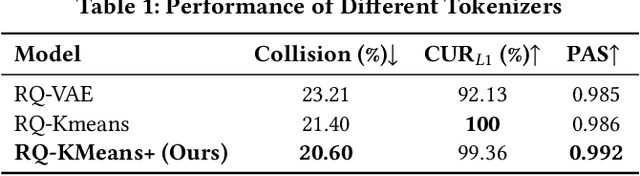
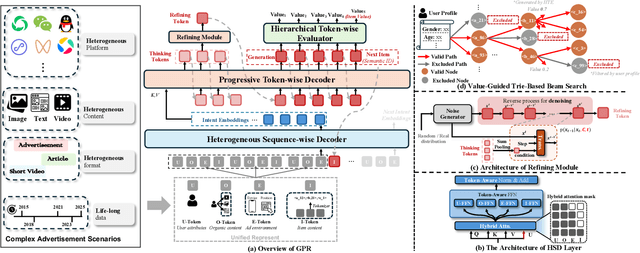
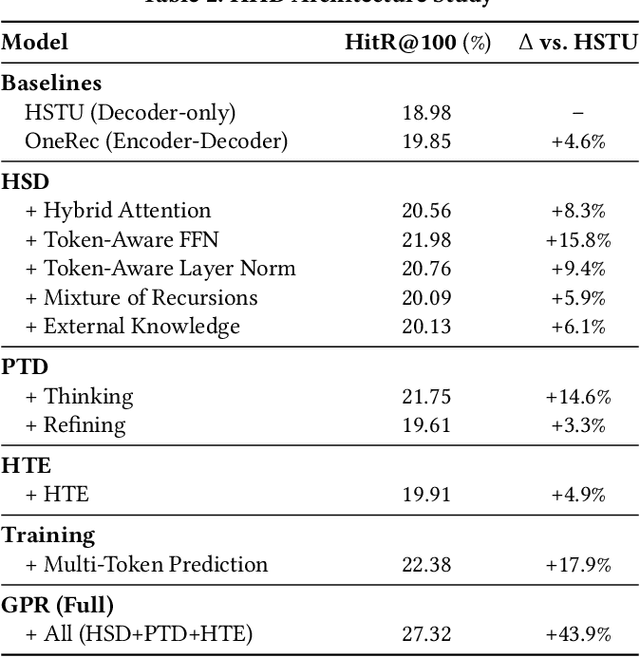
As an intelligent infrastructure connecting users with commercial content, advertising recommendation systems play a central role in information flow and value creation within the digital economy. However, existing multi-stage advertising recommendation systems suffer from objective misalignment and error propagation, making it difficult to achieve global optimality, while unified generative recommendation models still struggle to meet the demands of practical industrial applications. To address these issues, we propose GPR (Generative Pre-trained Recommender), the first one-model framework that redefines advertising recommendation as an end-to-end generative task, replacing the traditional cascading paradigm with a unified generative approach. To realize GPR, we introduce three key innovations spanning unified representation, network architecture, and training strategy. First, we design a unified input schema and tokenization method tailored to advertising scenarios, mapping both ads and organic content into a shared multi-level semantic ID space, thereby enhancing semantic alignment and modeling consistency across heterogeneous data. Second, we develop the Heterogeneous Hierarchical Decoder (HHD), a dual-decoder architecture that decouples user intent modeling from ad generation, achieving a balance between training efficiency and inference flexibility while maintaining strong modeling capacity. Finally, we propose a multi-stage joint training strategy that integrates Multi-Token Prediction (MTP), Value-Aware Fine-Tuning and the Hierarchy Enhanced Policy Optimization (HEPO) algorithm, forming a complete generative recommendation pipeline that unifies interest modeling, value alignment, and policy optimization. GPR has been fully deployed in the Tencent Weixin Channels advertising system, delivering significant improvements in key business metrics including GMV and CTCVR.
Generating Vision-Language Navigation Instructions Incorporated Fine-Grained Alignment Annotations
Jun 10, 2025Vision-Language Navigation (VLN) enables intelligent agents to navigate environments by integrating visual perception and natural language instructions, yet faces significant challenges due to the scarcity of fine-grained cross-modal alignment annotations. Existing datasets primarily focus on global instruction-trajectory matching, neglecting sub-instruction-level and entity-level alignments critical for accurate navigation action decision-making. To address this limitation, we propose FCA-NIG, a generative framework that automatically constructs navigation instructions with dual-level fine-grained cross-modal annotations. In this framework, an augmented trajectory is first divided into sub-trajectories, which are then processed through GLIP-based landmark detection, crafted instruction construction, OFA-Speaker based R2R-like instruction generation, and CLIP-powered entity selection, generating sub-instruction-trajectory pairs with entity-landmark annotations. Finally, these sub-pairs are aggregated to form a complete instruction-trajectory pair. The framework generates the FCA-R2R dataset, the first large-scale augmentation dataset featuring precise sub-instruction-sub-trajectory and entity-landmark alignments. Extensive experiments demonstrate that training with FCA-R2R significantly improves the performance of multiple state-of-the-art VLN agents, including SF, EnvDrop, RecBERT, and HAMT. Incorporating sub-instruction-trajectory alignment enhances agents' state awareness and decision accuracy, while entity-landmark alignment further boosts navigation performance and generalization. These results highlight the effectiveness of FCA-NIG in generating high-quality, scalable training data without manual annotation, advancing fine-grained cross-modal learning in complex navigation tasks.
ProMind-LLM: Proactive Mental Health Care via Causal Reasoning with Sensor Data
May 20, 2025Mental health risk is a critical global public health challenge, necessitating innovative and reliable assessment methods. With the development of large language models (LLMs), they stand out to be a promising tool for explainable mental health care applications. Nevertheless, existing approaches predominantly rely on subjective textual mental records, which can be distorted by inherent mental uncertainties, leading to inconsistent and unreliable predictions. To address these limitations, this paper introduces ProMind-LLM. We investigate an innovative approach integrating objective behavior data as complementary information alongside subjective mental records for robust mental health risk assessment. Specifically, ProMind-LLM incorporates a comprehensive pipeline that includes domain-specific pretraining to tailor the LLM for mental health contexts, a self-refine mechanism to optimize the processing of numerical behavioral data, and causal chain-of-thought reasoning to enhance the reliability and interpretability of its predictions. Evaluations of two real-world datasets, PMData and Globem, demonstrate the effectiveness of our proposed methods, achieving substantial improvements over general LLMs. We anticipate that ProMind-LLM will pave the way for more dependable, interpretable, and scalable mental health case solutions.
AGI-Elo: How Far Are We From Mastering A Task?
May 19, 2025As the field progresses toward Artificial General Intelligence (AGI), there is a pressing need for more comprehensive and insightful evaluation frameworks that go beyond aggregate performance metrics. This paper introduces a unified rating system that jointly models the difficulty of individual test cases and the competency of AI models (or humans) across vision, language, and action domains. Unlike existing metrics that focus solely on models, our approach allows for fine-grained, difficulty-aware evaluations through competitive interactions between models and tasks, capturing both the long-tail distribution of real-world challenges and the competency gap between current models and full task mastery. We validate the generalizability and robustness of our system through extensive experiments on multiple established datasets and models across distinct AGI domains. The resulting rating distributions offer novel perspectives and interpretable insights into task difficulty, model progression, and the outstanding challenges that remain on the path to achieving full AGI task mastery.
IMPACT: Behavioral Intention-aware Multimodal Trajectory Prediction with Adaptive Context Trimming
Apr 12, 2025While most prior research has focused on improving the precision of multimodal trajectory predictions, the explicit modeling of multimodal behavioral intentions (e.g., yielding, overtaking) remains relatively underexplored. This paper proposes a unified framework that jointly predicts both behavioral intentions and trajectories to enhance prediction accuracy, interpretability, and efficiency. Specifically, we employ a shared context encoder for both intention and trajectory predictions, thereby reducing structural redundancy and information loss. Moreover, we address the lack of ground-truth behavioral intention labels in mainstream datasets (Waymo, Argoverse) by auto-labeling these datasets, thus advancing the community's efforts in this direction. We further introduce a vectorized occupancy prediction module that infers the probability of each map polyline being occupied by the target vehicle's future trajectory. By leveraging these intention and occupancy prediction priors, our method conducts dynamic, modality-dependent pruning of irrelevant agents and map polylines in the decoding stage, effectively reducing computational overhead and mitigating noise from non-critical elements. Our approach ranks first among LiDAR-free methods on the Waymo Motion Dataset and achieves first place on the Waymo Interactive Prediction Dataset. Remarkably, even without model ensembling, our single-model framework improves the soft mean average precision (softmAP) by 10 percent compared to the second-best method in the Waymo Interactive Prediction Leaderboard. Furthermore, the proposed framework has been successfully deployed on real vehicles, demonstrating its practical effectiveness in real-world applications.
RMP-YOLO: A Robust Motion Predictor for Partially Observable Scenarios even if You Only Look Once
Sep 18, 2024



We introduce RMP-YOLO, a unified framework designed to provide robust motion predictions even with incomplete input data. Our key insight stems from the observation that complete and reliable historical trajectory data plays a pivotal role in ensuring accurate motion prediction. Therefore, we propose a new paradigm that prioritizes the reconstruction of intact historical trajectories before feeding them into the prediction modules. Our approach introduces a novel scene tokenization module to enhance the extraction and fusion of spatial and temporal features. Following this, our proposed recovery module reconstructs agents' incomplete historical trajectories by leveraging local map topology and interactions with nearby agents. The reconstructed, clean historical data is then integrated into the downstream prediction modules. Our framework is able to effectively handle missing data of varying lengths and remains robust against observation noise, while maintaining high prediction accuracy. Furthermore, our recovery module is compatible with existing prediction models, ensuring seamless integration. Extensive experiments validate the effectiveness of our approach, and deployment in real-world autonomous vehicles confirms its practical utility. In the 2024 Waymo Motion Prediction Competition, our method, RMP-YOLO, achieves state-of-the-art performance, securing third place.
AlignBot: Aligning VLM-powered Customized Task Planning with User Reminders Through Fine-Tuning for Household Robots
Sep 18, 2024



This paper presents AlignBot, a novel framework designed to optimize VLM-powered customized task planning for household robots by effectively aligning with user reminders. In domestic settings, aligning task planning with user reminders poses significant challenges due to the limited quantity, diversity, and multimodal nature of the reminders. To address these challenges, AlignBot employs a fine-tuned LLaVA-7B model, functioning as an adapter for GPT-4o. This adapter model internalizes diverse forms of user reminders-such as personalized preferences, corrective guidance, and contextual assistance-into structured instruction-formatted cues that prompt GPT-4o in generating customized task plans. Additionally, AlignBot integrates a dynamic retrieval mechanism that selects task-relevant historical successes as prompts for GPT-4o, further enhancing task planning accuracy. To validate the effectiveness of AlignBot, experiments are conducted in real-world household environments, which are constructed within the laboratory to replicate typical household settings. A multimodal dataset with over 1,500 entries derived from volunteer reminders is used for training and evaluation. The results demonstrate that AlignBot significantly improves customized task planning, outperforming existing LLM- and VLM-powered planners by interpreting and aligning with user reminders, achieving 86.8% success rate compared to the vanilla GPT-4o baseline at 21.6%, reflecting a 65% improvement and over four times greater effectiveness. Supplementary materials are available at: https://yding25.com/AlignBot/
MindGuard: Towards Accessible and Sitgma-free Mental Health First Aid via Edge LLM
Sep 16, 2024Mental health disorders are among the most prevalent diseases worldwide, affecting nearly one in four people. Despite their widespread impact, the intervention rate remains below 25%, largely due to the significant cooperation required from patients for both diagnosis and intervention. The core issue behind this low treatment rate is stigma, which discourages over half of those affected from seeking help. This paper presents MindGuard, an accessible, stigma-free, and professional mobile mental healthcare system designed to provide mental health first aid. The heart of MindGuard is an innovative edge LLM, equipped with professional mental health knowledge, that seamlessly integrates objective mobile sensor data with subjective Ecological Momentary Assessment records to deliver personalized screening and intervention conversations. We conduct a broad evaluation of MindGuard using open datasets spanning four years and real-world deployment across various mobile devices involving 20 subjects for two weeks. Remarkably, MindGuard achieves results comparable to GPT-4 and outperforms its counterpart with more than 10 times the model size. We believe that MindGuard paves the way for mobile LLM applications, potentially revolutionizing mental healthcare practices by substituting self-reporting and intervention conversations with passive, integrated monitoring within daily life, thus ensuring accessible and stigma-free mental health support.
DRAMA: An Efficient End-to-end Motion Planner for Autonomous Driving with Mamba
Aug 07, 2024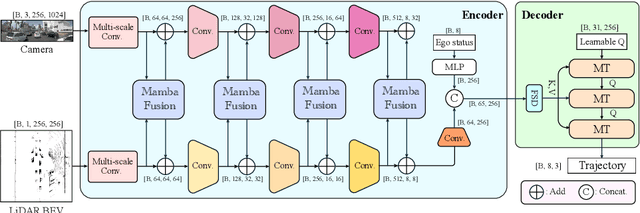



Motion planning is a challenging task to generate safe and feasible trajectories in highly dynamic and complex environments, forming a core capability for autonomous vehicles. In this paper, we propose DRAMA, the first Mamba-based end-to-end motion planner for autonomous vehicles. DRAMA fuses camera, LiDAR Bird's Eye View images in the feature space, as well as ego status information, to generate a series of future ego trajectories. Unlike traditional transformer-based methods with quadratic attention complexity for sequence length, DRAMA is able to achieve a less computationally intensive attention complexity, demonstrating potential to deal with increasingly complex scenarios. Leveraging our Mamba fusion module, DRAMA efficiently and effectively fuses the features of the camera and LiDAR modalities. In addition, we introduce a Mamba-Transformer decoder that enhances the overall planning performance. This module is universally adaptable to any Transformer-based model, especially for tasks with long sequence inputs. We further introduce a novel feature state dropout which improves the planner's robustness without increasing training and inference times. Extensive experimental results show that DRAMA achieves higher accuracy on the NAVSIM dataset compared to the baseline Transfuser, with fewer parameters and lower computational costs.
Lensless fiber endomicroscopic phase imaging with speckle-conditioned diffusion model
Jul 26, 2024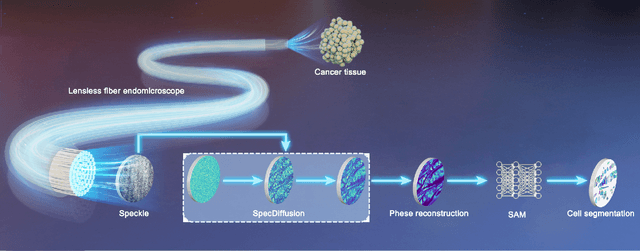

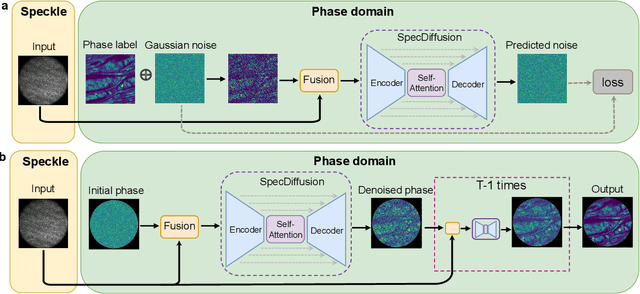
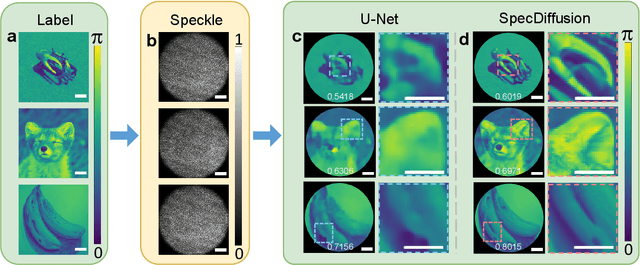
Lensless fiber endomicroscope is an emerging tool for in-vivo microscopic imaging, where quantitative phase imaging (QPI) can be utilized as a label-free method to enhance image contrast. However, existing single-shot phase reconstruction methods through lensless fiber endomicroscope typically perform well on simple images but struggle with complex microscopic structures. Here, we propose a speckle-conditioned diffusion model (SpecDiffusion), which reconstructs phase images directly from speckles captured at the detection side of a multi-core fiber (MCF). Unlike conventional neural networks, SpecDiffusion employs iterative phase denoising steps for speckle-driven phase reconstruction. The iteration scheme allows SpecDiffusion to break down the phase reconstruction process into multiple steps, gradually building up to the final phase image. This attribute alleviates the computation challenge at each step and enables the reconstruction of rich details in complex microscopic images. To validate its efficacy, we build an optical system to capture speckles from MCF and construct a dataset consisting of 100,000 paired images. SpecDiffusion provides high-fidelity phase reconstruction results and shows powerful generalization capacity for unseen objects, such as test charts and biological tissues, reducing the average mean absolute error of the reconstructed tissue images by 7 times. Furthermore, the reconstructed tissue images using SpecDiffusion shows higher accuracy in zero-shot cell segmentation tasks compared to the conventional method, demonstrating the potential for further cell morphology analysis through the learning-based lensless fiber endomicroscope. SpecDiffusion offers a precise and generalized method to phase reconstruction through scattering media, including MCFs, opening new perspective in lensless fiber endomicroscopic imaging.