 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneous emulation and downscaling with physically-consistent deep learning-based regional ocean emulators
Jan 09, 2025



Building on top of the success in AI-based atmospheric emulation, we propose an AI-based ocean emulation and downscaling framework focusing on the high-resolution regional ocean over Gulf of Mexico. Regional ocean emulation presents unique challenges owing to the complex bathymetry and lateral boundary conditions as well as from fundamental biases in deep learning-based frameworks, such as instability and hallucinations. In this paper, we develop a deep learning-based framework to autoregressively integrate ocean-surface variables over the Gulf of Mexico at $8$ Km spatial resolution without unphysical drifts over decadal time scales and simulataneously downscale and bias-correct it to $4$ Km resolution using a physics-constrained generative model. The framework shows both short-term skills as well as accurate long-term statistics in terms of mean and variability.
RMP-YOLO: A Robust Motion Predictor for Partially Observable Scenarios even if You Only Look Once
Sep 18, 2024



We introduce RMP-YOLO, a unified framework designed to provide robust motion predictions even with incomplete input data. Our key insight stems from the observation that complete and reliable historical trajectory data plays a pivotal role in ensuring accurate motion prediction. Therefore, we propose a new paradigm that prioritizes the reconstruction of intact historical trajectories before feeding them into the prediction modules. Our approach introduces a novel scene tokenization module to enhance the extraction and fusion of spatial and temporal features. Following this, our proposed recovery module reconstructs agents' incomplete historical trajectories by leveraging local map topology and interactions with nearby agents. The reconstructed, clean historical data is then integrated into the downstream prediction modules. Our framework is able to effectively handle missing data of varying lengths and remains robust against observation noise, while maintaining high prediction accuracy. Furthermore, our recovery module is compatible with existing prediction models, ensuring seamless integration. Extensive experiments validate the effectiveness of our approach, and deployment in real-world autonomous vehicles confirms its practical utility. In the 2024 Waymo Motion Prediction Competition, our method, RMP-YOLO, achieves state-of-the-art performance, securing third place.
DRAMA: An Efficient End-to-end Motion Planner for Autonomous Driving with Mamba
Aug 07, 2024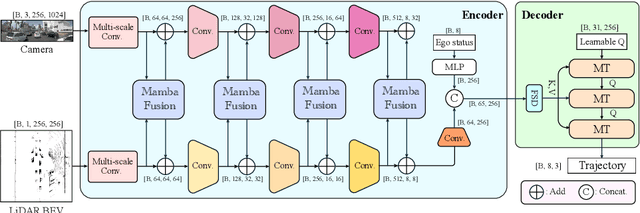



Motion planning is a challenging task to generate safe and feasible trajectories in highly dynamic and complex environments, forming a core capability for autonomous vehicles. In this paper, we propose DRAMA, the first Mamba-based end-to-end motion planner for autonomous vehicles. DRAMA fuses camera, LiDAR Bird's Eye View images in the feature space, as well as ego status information, to generate a series of future ego trajectories. Unlike traditional transformer-based methods with quadratic attention complexity for sequence length, DRAMA is able to achieve a less computationally intensive attention complexity, demonstrating potential to deal with increasingly complex scenarios. Leveraging our Mamba fusion module, DRAMA efficiently and effectively fuses the features of the camera and LiDAR modalities. In addition, we introduce a Mamba-Transformer decoder that enhances the overall planning performance. This module is universally adaptable to any Transformer-based model, especially for tasks with long sequence inputs. We further introduce a novel feature state dropout which improves the planner's robustness without increasing training and inference times. Extensive experimental results show that DRAMA achieves higher accuracy on the NAVSIM dataset compared to the baseline Transfuser, with fewer parameters and lower computational costs.
ControlMTR: Control-Guided Motion Transformer with Scene-Compliant Intention Points for Feasible Motion Prediction
Apr 17, 2024



The ability to accurately predict feasible multimodal future trajectories of surrounding traffic participants is crucial for behavior planning in autonomous vehicles. The Motion Transformer (MTR), a state-of-the-art motion prediction method, alleviated mode collapse and instability during training and enhanced overall prediction performance by replacing conventional dense future endpoints with a small set of fixed prior motion intention points. However, the fixed prior intention points make the MTR multi-modal prediction distribution over-scattered and infeasible in many scenarios. In this paper, we propose the ControlMTR framework to tackle the aforementioned issues by generating scene-compliant intention points and additionally predicting driving control commands, which are then converted into trajectories by a simple kinematic model with soft constraints. These control-generated trajectories will guide the directly predicted trajectories by an auxiliary loss function. Together with our proposed scene-compliant intention points, they can effectively restrict the prediction distribution within the road boundaries and suppress infeasible off-road predictions while enhancing prediction performance. Remarkably, without resorting to additional model ensemble techniques, our method surpasses the baseline MTR model across all performance metrics, achieving notable improvements of 5.22% in SoftmAP and a 4.15% reduction in MissRate. Our approach notably results in a 41.85% reduction in the cross-boundary rate of the MTR, effectively ensuring that the prediction distribution is confined within the drivable area.
Are Out-of-Distribution Detection Methods Reliable?
Nov 20, 2022

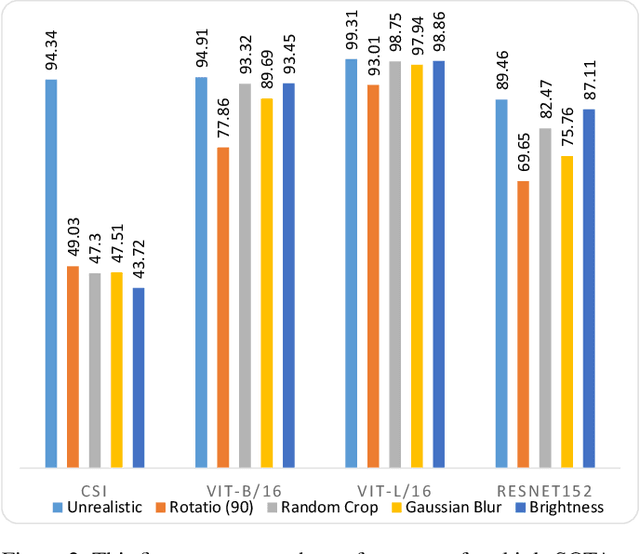

This paper establishes a novel evaluation framework for assessing the performance of out-of-distribution (OOD) detection in realistic settings. Our goal is to expose the shortcomings of existing OOD detection benchmarks and encourage a necessary research direction shift toward satisfying the requirements of real-world applications. We expand OOD detection research by introducing new OOD test datasets CIFAR-10-R, CIFAR-100-R, and MVTec-R, which allow researchers to benchmark OOD detection performance under realistic distribution shifts. We also introduce a generalizability score to measure a method's ability to generalize from standard OOD detection test datasets to a realistic setting. Contrary to existing OOD detection research, we demonstrate that further performance improvements on standard benchmark datasets do not increase the usability of such models in the real world. State-of-the-art (SOTA) methods tested on our realistic distributionally-shifted datasets drop in performance for up to 45%. This setting is critical for evaluating the reliability of OOD models before they are deployed in real-world environments.
GET-DIPP: Graph-Embedded Transformer for Differentiable Integrated Prediction and Planning
Nov 11, 2022



Accurately predicting interactive road agents' future trajectories and planning a socially compliant and human-like trajectory accordingly are important for autonomous vehicles. In this paper, we propose a planning-centric prediction neural network, which takes surrounding agents' historical states and map context information as input, and outputs the joint multi-modal prediction trajectories for surrounding agents, as well as a sequence of control commands for the ego vehicle by imitation learning. An agent-agent interaction module along the time axis is proposed in our network architecture to better comprehend the relationship among all the other intelligent agents on the road. To incorporate the map's topological information, a Dynamic Graph Convolutional Neural Network (DGCNN) is employed to process the road network topology. Besides, the whole architecture can serve as a backbone for the Differentiable Integrated motion Prediction with Planning (DIPP) method by providing accurate prediction results and initial planning commands. Experiments are conducted on real-world datasets to demonstrate the improvements made by our proposed method in both planning and prediction accuracy compared to the previous state-of-the-art methods.
Augment to Detect Anomalies with Continuous Labelling
Jul 03, 2022
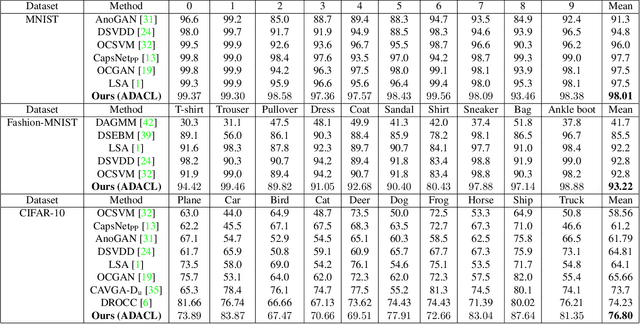

Anomaly detection is to recognize samples that differ in some respect from the training observations. These samples which do not conform to the distribution of normal data are called outliers or anomalies. In real-world anomaly detection problems, the outliers are absent, not well defined, or have a very limited number of instances. Recent state-of-the-art deep learning-based anomaly detection methods suffer from high computational cost, complexity, unstable training procedures, and non-trivial implementation, making them difficult to deploy in real-world applications. To combat this problem, we leverage a simple learning procedure that trains a lightweight convolutional neural network, reaching state-of-the-art performance in anomaly detection. In this paper, we propose to solve anomaly detection as a supervised regression problem. We label normal and anomalous data using two separable distributions of continuous values. To compensate for the unavailability of anomalous samples during training time, we utilize straightforward image augmentation techniques to create a distinct set of samples as anomalies. The distribution of the augmented set is similar but slightly deviated from the normal data, whereas real anomalies are expected to have an even further distribution. Therefore, training a regressor on these augmented samples will result in more separable distributions of labels for normal and real anomalous data points. Anomaly detection experiments on image and video datasets show the superiority of the proposed method over the state-of-the-art approaches.
Anomaly Detection with Adversarially Learned Perturbations of Latent Space
Jul 03, 2022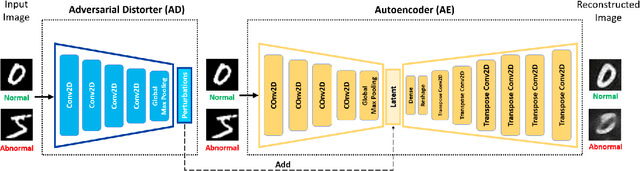



Anomaly detection is to identify samples that do not conform to the distribution of the normal data. Due to the unavailability of anomalous data, training a supervised deep neural network is a cumbersome task. As such, unsupervised methods are preferred as a common approach to solve this task. Deep autoencoders have been broadly adopted as a base of many unsupervised anomaly detection methods. However, a notable shortcoming of deep autoencoders is that they provide insufficient representations for anomaly detection by generalizing to reconstruct outliers. In this work, we have designed an adversarial framework consisting of two competing components, an Adversarial Distorter, and an Autoencoder. The Adversarial Distorter is a convolutional encoder that learns to produce effective perturbations and the autoencoder is a deep convolutional neural network that aims to reconstruct the images from the perturbed latent feature space. The networks are trained with opposing goals in which the Adversarial Distorter produces perturbations that are applied to the encoder's latent feature space to maximize the reconstruction error and the autoencoder tries to neutralize the effect of these perturbations to minimize it. When applied to anomaly detection, the proposed method learns semantically richer representations due to applying perturbations to the feature space. The proposed method outperforms the existing state-of-the-art methods in anomaly detection on image and video datasets.