 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the adaptive and continuous learning capabilities of artificial neural networks: Lessons from multi-neuromodulatory dynamics
Jan 12, 2025



Continuous, adaptive learning-the ability to adapt to the environment and improve performance-is a hallmark of both natural and artificial intelligence. Biological organisms excel in acquiring, transferring, and retaining knowledge while adapting to dynamic environments, making them a rich source of inspiration for artificial neural networks (ANNs). This study explores how neuromodulation, a fundamental feature of biological learning systems, can help address challenges such as catastrophic forgetting and enhance the robustness of ANNs in continuous learning scenarios. Driven by neuromodulators including dopamine (DA), acetylcholine (ACh), serotonin (5-HT) and noradrenaline (NA), neuromodulatory processes in the brain operate at multiple scales, facilitating dynamic responses to environmental changes through mechanisms ranging from local synaptic plasticity to global network-wide adaptability. Importantly, the relationship between neuromodulators, and their interplay in the modulation of sensory and cognitive processes are more complex than expected, demonstrating a "many-to-one" neuromodulator-to-task mapping. To inspire the design of novel neuromodulation-aware learning rules, we highlight (i) how multi-neuromodulatory interactions enrich single-neuromodulator-driven learning, (ii) the impact of neuromodulators at multiple spatial and temporal scales, and correspondingly, (iii) strategies to integrate neuromodulated learning into or approximate it in ANNs. To illustrate these principles, we present a case study to demonstrate how neuromodulation-inspired mechanisms, such as DA-driven reward processing and NA-based cognitive flexibility, can enhance ANN performance in a Go/No-Go task. By integrating multi-scale neuromodulation, we aim to bridge the gap between biological learning and artificial systems, paving the way for ANNs with greater flexibility, robustness, and adaptability.
Modeling Visual Memorability Assessment with Autoencoders Reveals Characteristics of Memorable Images
Oct 19, 2024Background: Image memorability refers to the phenomenon where certain images are more likely to be remembered than others. It is a quantifiable and intrinsic image attribute, defined as the likelihood of being remembered upon a single exposure. Despite advances in understanding human visual perception and memory, it is unclear what features contribute to an image's memorability. To address this question, we propose a deep learning-based computational modeling approach. Methods: We modeled the subjective experience of visual memorability using an autoencoder based on VGG16 Convolutional Neural Networks (CNNs). The model was trained on images for one epoch, to simulate the single-exposure condition used in human memory tests. We investigated the relationship between memorability and reconstruction error, assessed latent space representations distinctiveness, and developed a Gated Recurrent Unit (GRU) model to predict memorability likelihood. Interpretability analysis was conducted to identify key image characteristics contributing to memorability. Results: Our results demonstrate a significant correlation between the images memorability score and autoencoder's reconstruction error, and the robust predictive performance of its latent representations. Distinctiveness in these representations correlated significantly with memorability. Additionally, certain visual characteristics, such as strong contrasts, distinctive objects, and prominent foreground elements were among the features contributing to image memorability in our model. Conclusions: Images with unique features that challenge the autoencoder's capacity are inherently more memorable. Moreover, these memorable images are distinct from others the model has encountered, and the latent space of the encoder contains features predictive of memorability.
Efficient Slice Anomaly Detection Network for 3D Brain MRI Volume
Aug 28, 2024



Current anomaly detection methods excel with benchmark industrial data but struggle with natural images and medical data due to varying definitions of 'normal' and 'abnormal.' This makes accurate identification of deviations in these fields particularly challenging. Especially for 3D brain MRI data, all the state-of-the-art models are reconstruction-based with 3D convolutional neural networks which are memory-intensive, time-consuming and producing noisy outputs that require further post-processing. We propose a framework called Simple Slice-based Network (SimpleSliceNet), which utilizes a model pre-trained on ImageNet and fine-tuned on a separate MRI dataset as a 2D slice feature extractor to reduce computational cost. We aggregate the extracted features to perform anomaly detection tasks on 3D brain MRI volumes. Our model integrates a conditional normalizing flow to calculate log likelihood of features and employs the Semi-Push-Pull Mechanism to enhance anomaly detection accuracy. The results indicate improved performance, showcasing our model's remarkable adaptability and effectiveness when addressing the challenges exists in brain MRI data. In addition, for the large-scale 3D brain volumes, our model SimpleSliceNet outperforms the state-of-the-art 2D and 3D models in terms of accuracy, memory usage and time consumption. Code is available at: https://anonymous.4open.science/r/SimpleSliceNet-8EA3.
Multi-modal News Understanding with Professionally Labelled Videos (ReutersViLNews)
Jan 23, 2024
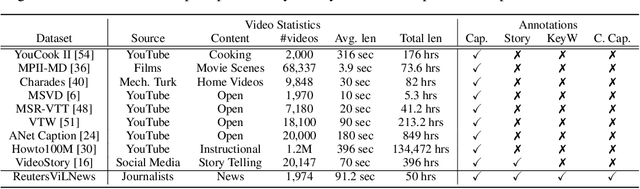
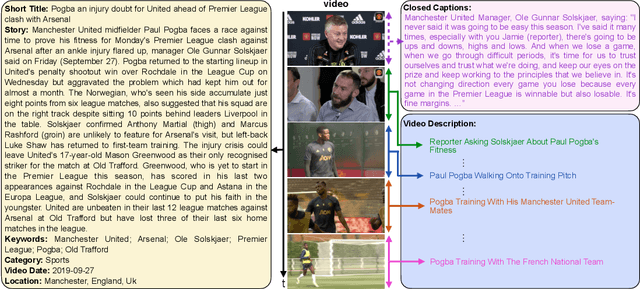
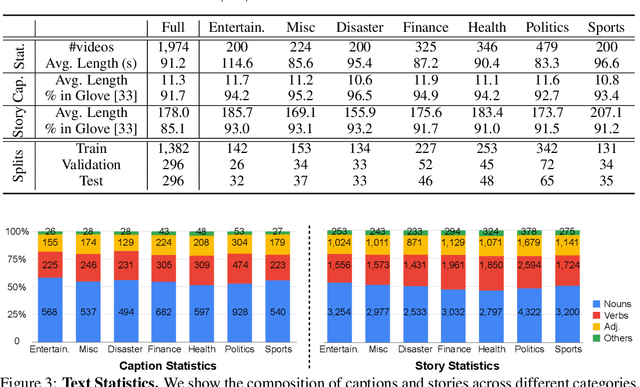
While progress has been made in the domain of video-language understanding, current state-of-the-art algorithms are still limited in their ability to understand videos at high levels of abstraction, such as news-oriented videos. Alternatively, humans easily amalgamate information from video and language to infer information beyond what is visually observable in the pixels. An example of this is watching a news story, where the context of the event can play as big of a role in understanding the story as the event itself. Towards a solution for designing this ability in algorithms, we present a large-scale analysis on an in-house dataset collected by the Reuters News Agency, called Reuters Video-Language News (ReutersViLNews) dataset which focuses on high-level video-language understanding with an emphasis on long-form news. The ReutersViLNews Dataset consists of long-form news videos collected and labeled by news industry professionals over several years and contains prominent news reporting from around the world. Each video involves a single story and contains action shots of the actual event, interviews with people associated with the event, footage from nearby areas, and more. ReutersViLNews dataset contains videos from seven subject categories: disaster, finance, entertainment, health, politics, sports, and miscellaneous with annotations from high-level to low-level, title caption, visual video description, high-level story description, keywords, and location. We first present an analysis of the dataset statistics of ReutersViLNews compared to previous datasets. Then we benchmark state-of-the-art approaches for four different video-language tasks. The results suggest that news-oriented videos are a substantial challenge for current video-language understanding algorithms and we conclude by providing future directions in designing approaches to solve the ReutersViLNews dataset.
Look-Ahead Selective Plasticity for Continual Learning of Visual Tasks
Nov 02, 2023Contrastive representation learning has emerged as a promising technique for continual learning as it can learn representations that are robust to catastrophic forgetting and generalize well to unseen future tasks. Previous work in continual learning has addressed forgetting by using previous task data and trained models. Inspired by event models created and updated in the brain, we propose a new mechanism that takes place during task boundaries, i.e., when one task finishes and another starts. By observing the redundancy-inducing ability of contrastive loss on the output of a neural network, our method leverages the first few samples of the new task to identify and retain parameters contributing most to the transfer ability of the neural network, freeing up the remaining parts of the network to learn new features. We evaluate the proposed methods on benchmark computer vision datasets including CIFAR10 and TinyImagenet and demonstrate state-of-the-art performance in the task-incremental, class-incremental, and domain-incremental continual learning scenarios.
Augment to Detect Anomalies with Continuous Labelling
Jul 03, 2022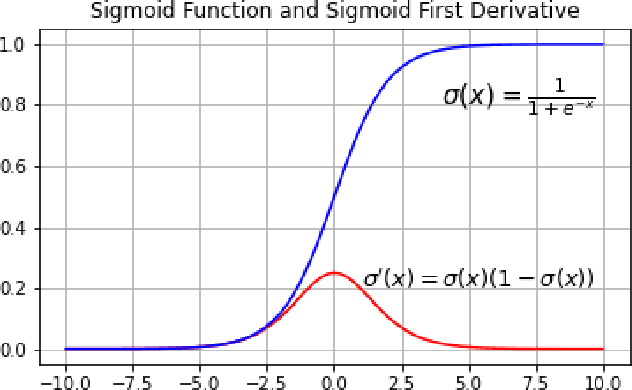
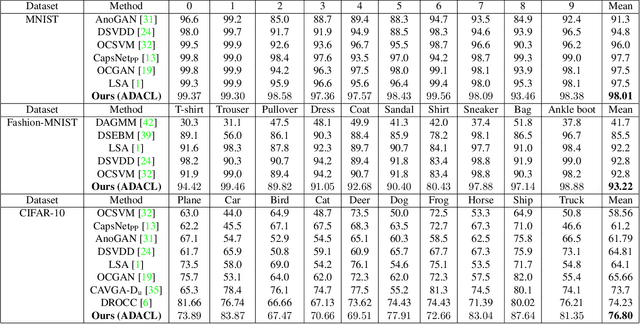
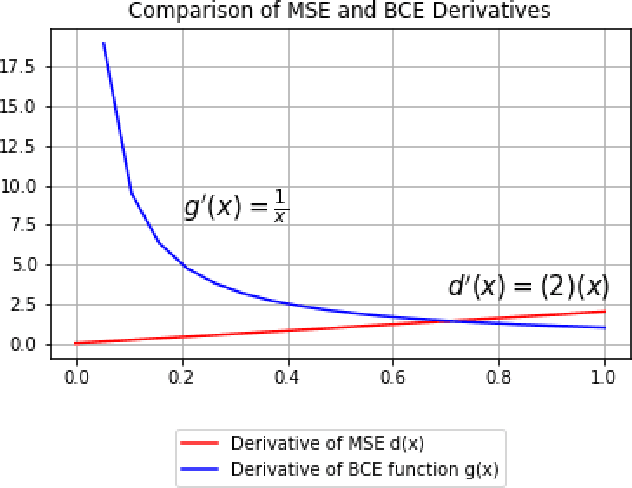

Anomaly detection is to recognize samples that differ in some respect from the training observations. These samples which do not conform to the distribution of normal data are called outliers or anomalies. In real-world anomaly detection problems, the outliers are absent, not well defined, or have a very limited number of instances. Recent state-of-the-art deep learning-based anomaly detection methods suffer from high computational cost, complexity, unstable training procedures, and non-trivial implementation, making them difficult to deploy in real-world applications. To combat this problem, we leverage a simple learning procedure that trains a lightweight convolutional neural network, reaching state-of-the-art performance in anomaly detection. In this paper, we propose to solve anomaly detection as a supervised regression problem. We label normal and anomalous data using two separable distributions of continuous values. To compensate for the unavailability of anomalous samples during training time, we utilize straightforward image augmentation techniques to create a distinct set of samples as anomalies. The distribution of the augmented set is similar but slightly deviated from the normal data, whereas real anomalies are expected to have an even further distribution. Therefore, training a regressor on these augmented samples will result in more separable distributions of labels for normal and real anomalous data points. Anomaly detection experiments on image and video datasets show the superiority of the proposed method over the state-of-the-art approaches.
Anomaly Detection with Adversarially Learned Perturbations of Latent Space
Jul 03, 2022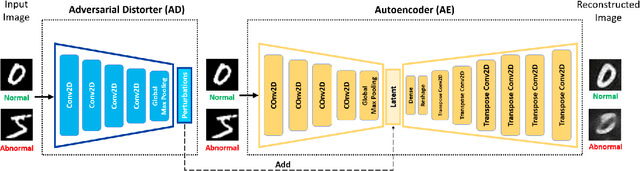



Anomaly detection is to identify samples that do not conform to the distribution of the normal data. Due to the unavailability of anomalous data, training a supervised deep neural network is a cumbersome task. As such, unsupervised methods are preferred as a common approach to solve this task. Deep autoencoders have been broadly adopted as a base of many unsupervised anomaly detection methods. However, a notable shortcoming of deep autoencoders is that they provide insufficient representations for anomaly detection by generalizing to reconstruct outliers. In this work, we have designed an adversarial framework consisting of two competing components, an Adversarial Distorter, and an Autoencoder. The Adversarial Distorter is a convolutional encoder that learns to produce effective perturbations and the autoencoder is a deep convolutional neural network that aims to reconstruct the images from the perturbed latent feature space. The networks are trained with opposing goals in which the Adversarial Distorter produces perturbations that are applied to the encoder's latent feature space to maximize the reconstruction error and the autoencoder tries to neutralize the effect of these perturbations to minimize it. When applied to anomaly detection, the proposed method learns semantically richer representations due to applying perturbations to the feature space. The proposed method outperforms the existing state-of-the-art methods in anomaly detection on image and video datasets.
Controlling Memorability of Face Images
Feb 24, 2022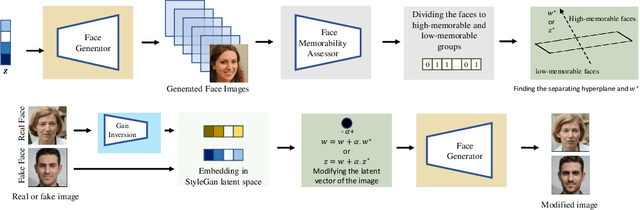


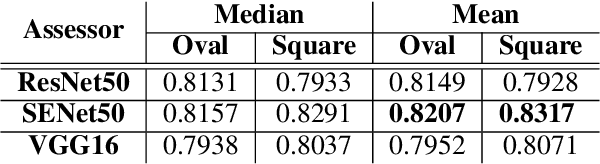
Everyday, we are bombarded with many photographs of faces, whether on social media, television, or smartphones. From an evolutionary perspective, faces are intended to be remembered, mainly due to survival and personal relevance. However, all these faces do not have the equal opportunity to stick in our minds. It has been shown that memorability is an intrinsic feature of an image but yet, it is largely unknown what attributes make an image more memorable. In this work, we aimed to address this question by proposing a fast approach to modify and control the memorability of face images. In our proposed method, we first found a hyperplane in the latent space of StyleGAN to separate high and low memorable images. We then modified the image memorability (while maintaining the identity and other facial features such as age, emotion, etc.) by moving in the positive or negative direction of this hyperplane normal vector. We further analyzed how different layers of the StyleGAN augmented latent space contribute to face memorability. These analyses showed how each individual face attribute makes an image more or less memorable. Most importantly, we evaluated our proposed method for both real and synthesized face images. The proposed method successfully modifies and controls the memorability of real human faces as well as unreal synthesized faces. Our proposed method can be employed in photograph editing applications for social media, learning aids, or advertisement purposes.
The Impact of Spatiotemporal Augmentations on Self-Supervised Audiovisual Representation Learning
Oct 13, 2021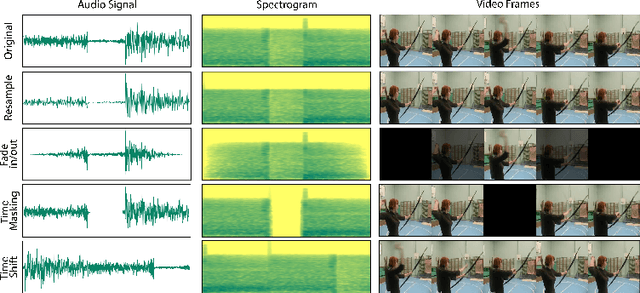
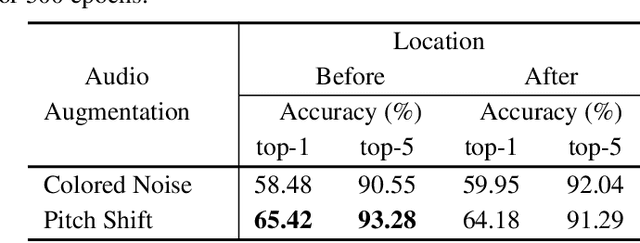
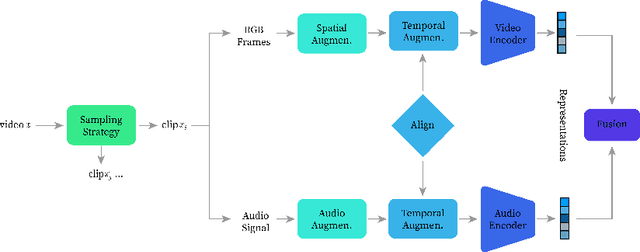
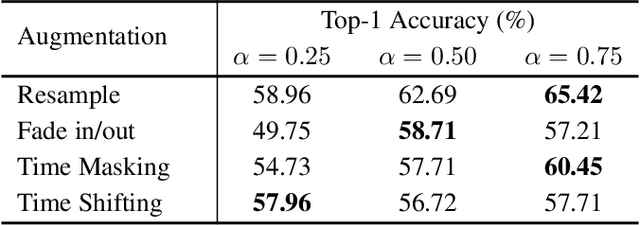
Contrastive learning of auditory and visual perception has been extremely successful when investigated individually. However, there are still major questions on how we could integrate principles learned from both domains to attain effective audiovisual representations. In this paper, we present a contrastive framework to learn audiovisual representations from unlabeled videos. The type and strength of augmentations utilized during self-supervised pre-training play a crucial role for contrastive frameworks to work sufficiently. Hence, we extensively investigate composition of temporal augmentations suitable for learning audiovisual representations; we find lossy spatio-temporal transformations that do not corrupt the temporal coherency of videos are the most effective. Furthermore, we show that the effectiveness of these transformations scales with higher temporal resolution and stronger transformation intensity. Compared to self-supervised models pre-trained on only sampling-based temporal augmentation, self-supervised models pre-trained with our temporal augmentations lead to approximately 6.5% gain on linear classifier performance on AVE dataset. Lastly, we show that despite their simplicity, our proposed transformations work well across self-supervised learning frameworks (SimSiam, MoCoV3, etc), and benchmark audiovisual dataset (AVE).
OLED: One-Class Learned Encoder-Decoder Network with Adversarial Context Masking for Novelty Detection
Apr 08, 2021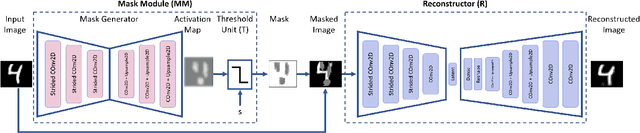
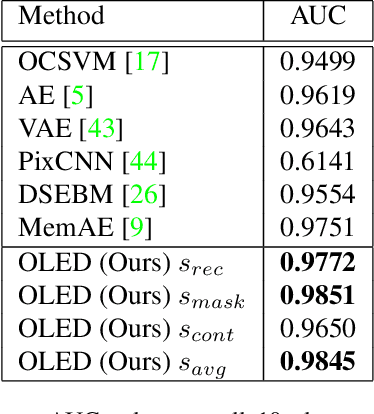

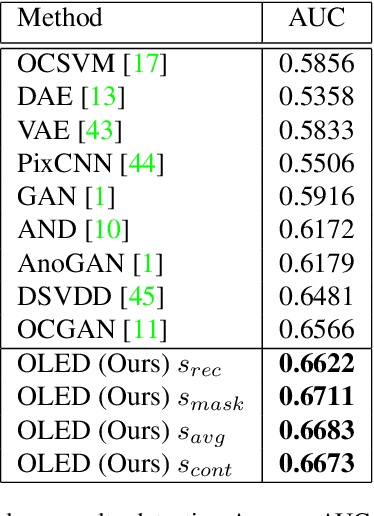
Novelty detection is the task of recognizing samples that do not belong to the distribution of the target class. During training, the novelty class is absent, preventing the use of traditional classification approaches. Deep autoencoders have been widely used as a base of many unsupervised novelty detection methods. In particular, context autoencoders have been successful in the novelty detection task because of the more effective representations they learn by reconstructing original images from randomly masked images. However, a significant drawback of context autoencoders is that random masking fails to consistently cover important structures of the input image, leading to suboptimal representations - especially for the novelty detection task. In this paper, to optimize input masking, we have designed a framework consisting of two competing networks, a Mask Module and a Reconstructor. The Mask Module is a convolutional autoencoder that learns to generate optimal masks that cover the most important parts of images. Alternatively, the Reconstructor is a convolutional encoder-decoder that aims to reconstruct unperturbed images from masked images. The networks are trained in an adversarial manner in which the Mask Module generates masks that are applied to images given to the Reconstructor. In this way, the Mask Module seeks to maximize the reconstruction error that the Reconstructor is minimizing. When applied to novelty detection, the proposed approach learns semantically richer representations compared to context autoencoders and enhances novelty detection at test time through more optimal masking. Novelty detection experiments on the MNIST and CIFAR-10 image datasets demonstrate the proposed approach's superiority over cutting-edge methods. In a further experiment on the UCSD video dataset for novelty detection, the proposed approach achieves state-of-the-art results.