 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-R$^3$: On (In-)Consistency of Multi-modal Large Language Models (MLLMs)
Oct 07, 2024With the advent of Large Language Models (LLMs) and Multimodal (Visio-lingual) LLMs, a flurry of research has emerged, analyzing the performance of such models across a diverse array of tasks. While most studies focus on evaluating the capabilities of state-of-the-art (SoTA) MLLM models through task accuracy (e.g., Visual Question Answering, grounding) across various datasets, our work explores the related but complementary aspect of consistency - the ability of an MLLM model to produce semantically similar or identical responses to semantically similar queries. We note that consistency is a fundamental prerequisite (necessary but not sufficient condition) for robustness and trust in MLLMs. Humans, in particular, are known to be highly consistent (even if not always accurate) in their responses, and consistency is inherently expected from AI systems. Armed with this perspective, we propose the MM-R$^3$ benchmark, which analyses the performance in terms of consistency and accuracy in SoTA MLLMs with three tasks: Question Rephrasing, Image Restyling, and Context Reasoning. Our analysis reveals that consistency does not always align with accuracy, indicating that models with higher accuracy are not necessarily more consistent, and vice versa. Furthermore, we propose a simple yet effective mitigation strategy in the form of an adapter module trained to minimize inconsistency across prompts. With our proposed strategy, we are able to achieve absolute improvements of 5.7% and 12.5%, on average on widely used MLLMs such as BLIP-2 and LLaVa 1.5M in terms of consistency over their existing counterparts.
Multi-modal News Understanding with Professionally Labelled Videos (ReutersViLNews)
Jan 23, 2024
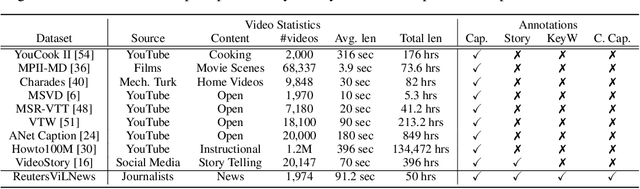
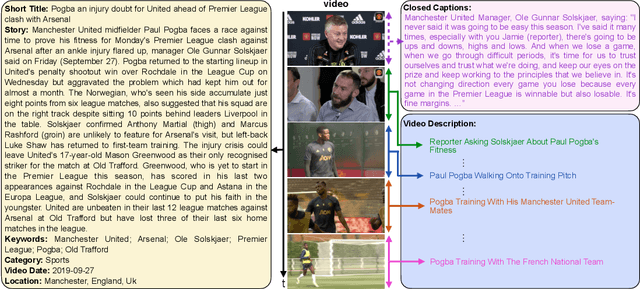
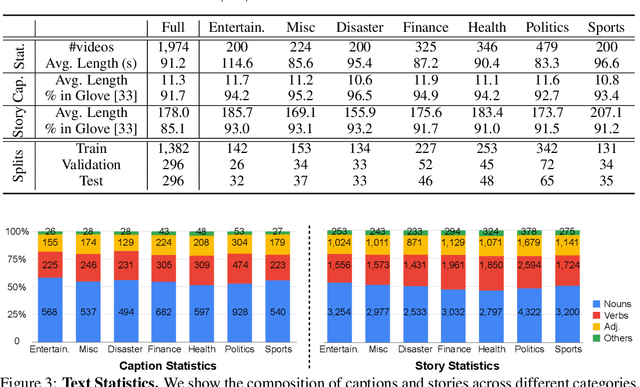
While progress has been made in the domain of video-language understanding, current state-of-the-art algorithms are still limited in their ability to understand videos at high levels of abstraction, such as news-oriented videos. Alternatively, humans easily amalgamate information from video and language to infer information beyond what is visually observable in the pixels. An example of this is watching a news story, where the context of the event can play as big of a role in understanding the story as the event itself. Towards a solution for designing this ability in algorithms, we present a large-scale analysis on an in-house dataset collected by the Reuters News Agency, called Reuters Video-Language News (ReutersViLNews) dataset which focuses on high-level video-language understanding with an emphasis on long-form news. The ReutersViLNews Dataset consists of long-form news videos collected and labeled by news industry professionals over several years and contains prominent news reporting from around the world. Each video involves a single story and contains action shots of the actual event, interviews with people associated with the event, footage from nearby areas, and more. ReutersViLNews dataset contains videos from seven subject categories: disaster, finance, entertainment, health, politics, sports, and miscellaneous with annotations from high-level to low-level, title caption, visual video description, high-level story description, keywords, and location. We first present an analysis of the dataset statistics of ReutersViLNews compared to previous datasets. Then we benchmark state-of-the-art approaches for four different video-language tasks. The results suggest that news-oriented videos are a substantial challenge for current video-language understanding algorithms and we conclude by providing future directions in designing approaches to solve the ReutersViLNews dataset.
Implicit and Explicit Commonsense for Multi-sentence Video Captioning
Mar 14, 2023



Existing dense or paragraph video captioning approaches rely on holistic representations of videos, possibly coupled with learned object/action representations, to condition hierarchical language decoders. However, they fundamentally lack the commonsense knowledge of the world required to reason about progression of events, causality, and even function of certain objects within a scene. To address this limitation we propose a novel video captioning Transformer-based model, that takes into account both implicit (visuo-lingual and purely linguistic) and explicit (knowledge-base) commonsense knowledge. We show that these forms of knowledge, in isolation and in combination, enhance the quality of produced captions. Further, inspired by imitation learning, we propose a new task of instruction generation, where the goal is to produce a set of linguistic instructions from a video demonstration of its performance. We formalize the task using ALFRED dataset [52] generated using an AI2-THOR environment. While instruction generation is conceptually similar to paragraph captioning, it differs in the fact that it exhibits stronger object persistence, as well as spatially-aware and causal sentence structure. We show that our commonsense knowledge enhanced approach produces significant improvements on this task (up to 57% in METEOR and 8.5% in CIDEr), as well as the state-of-the-art result on more traditional video captioning in the ActivityNet Captions dataset [29].
An Improved Attention for Visual Question Answering
Nov 07, 2020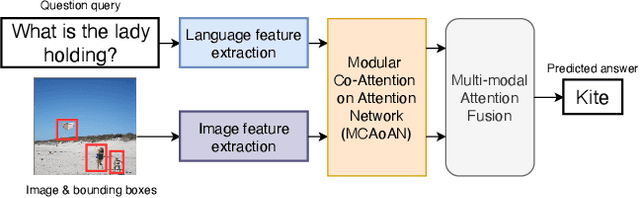
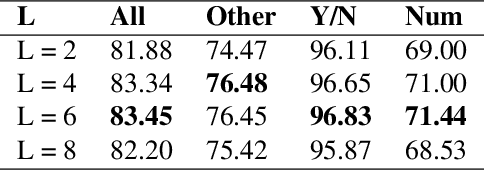
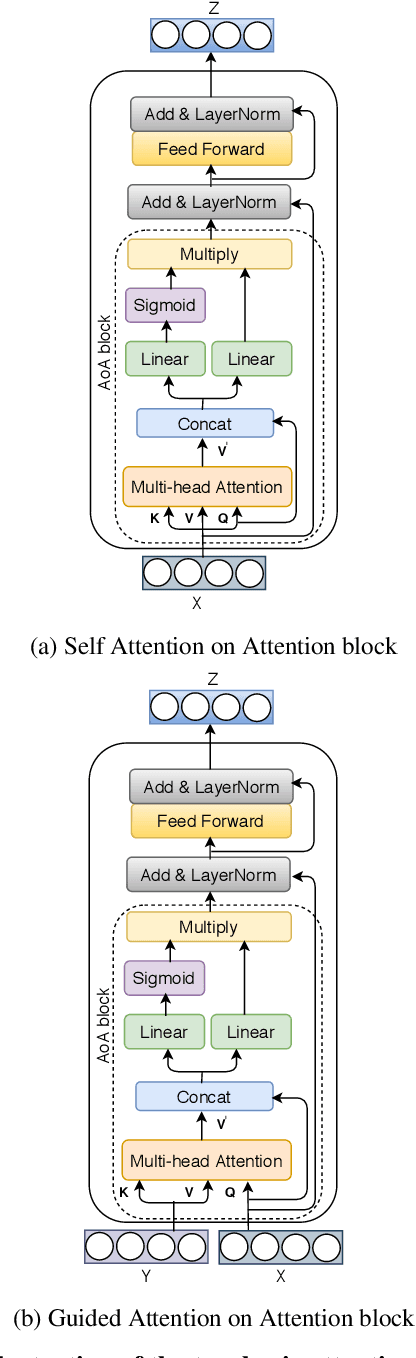

We consider the problem of Visual Question Answering (VQA). Given an image and a free-form, open-ended, question, expressed in natural language, the goal of VQA system is to provide accurate answer to this question with respect to the image. The task is challenging because it requires simultaneous and intricate understanding of both visual and textual information. Attention, which captures intra- and inter-modal dependencies, has emerged as perhaps the most widely used mechanism for addressing these challenges. In this paper, we propose an improved attention-based architecture to solve VQA. We incorporate an Attention on Attention (AoA) module within encoder-decoder framework, which is able to determine the relation between attention results and queries. Attention module generates weighted average for each query. On the other hand, AoA module first generates an information vector and an attention gate using attention results and current context; and then adds another attention to generate final attended information by multiplying the two. We also propose multimodal fusion module to combine both visual and textual information. The goal of this fusion module is to dynamically decide how much information should be considered from each modality. Extensive experiments on VQA-v2 benchmark dataset show that our method achieves the state-of-the-art performance.
Visual Question Answering on 360° Images
Jan 10, 2020
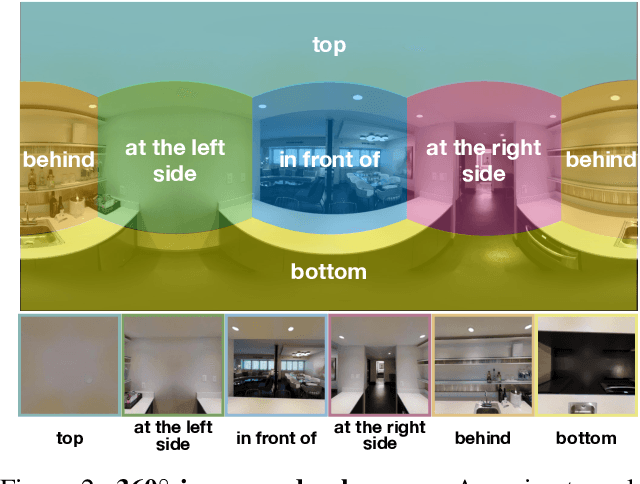
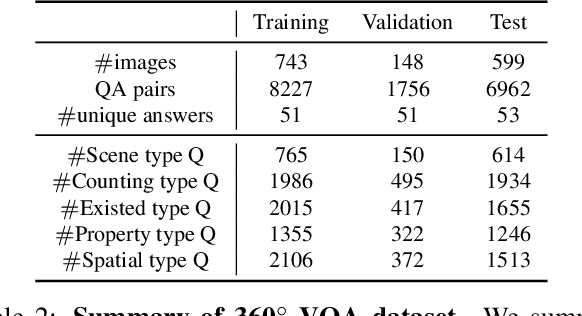
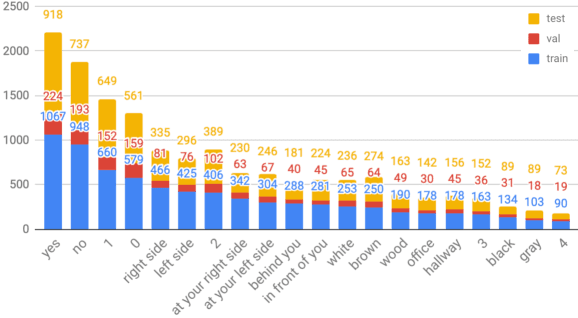
In this work, we introduce VQA 360, a novel task of visual question answering on 360 images. Unlike a normal field-of-view image, a 360 image captures the entire visual content around the optical center of a camera, demanding more sophisticated spatial understanding and reasoning. To address this problem, we collect the first VQA 360 dataset, containing around 17,000 real-world image-question-answer triplets for a variety of question types. We then study two different VQA models on VQA 360, including one conventional model that takes an equirectangular image (with intrinsic distortion) as input and one dedicated model that first projects a 360 image onto cubemaps and subsequently aggregates the information from multiple spatial resolutions. We demonstrate that the cubemap-based model with multi-level fusion and attention diffusion performs favorably against other variants and the equirectangular-based models. Nevertheless, the gap between the humans' and machines' performance reveals the need for more advanced VQA 360 algorithms. We, therefore, expect our dataset and studies to serve as the benchmark for future development in this challenging task. Dataset, code, and pre-trained models are available online.
360-Indoor: Towards Learning Real-World Objects in 360° Indoor Equirectangular Images
Oct 03, 2019


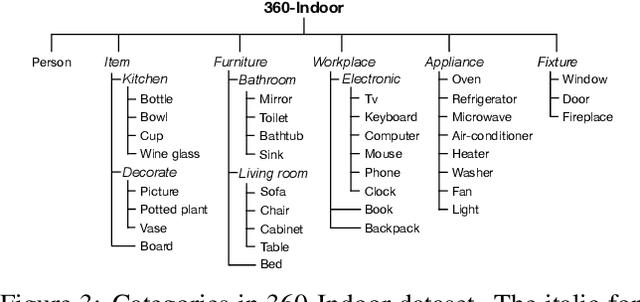
While there are several widely used object detection datasets, current computer vision algorithms are still limited in conventional images. Such images narrow our vision in a restricted region. On the other hand, 360{\deg} images provide a thorough sight. In this paper, our goal is to provide a standard dataset to facilitate the vision and machine learning communities in 360{\deg} domain. To facilitate the research, we present a real-world 360{\deg} panoramic object detection dataset, 360-Indoor, which is a new benchmark for visual object detection and class recognition in 360{\deg} indoor images. It is achieved by gathering images of complex indoor scenes containing common objects and the intensive annotated bounding field-of-view. In addition, 360-Indoor has several distinct properties: (1) the largest category number (37 labels in total). (2) the most complete annotations on average (27 bounding boxes per image). The selected 37 objects are all common in indoor scene. With around 3k images and 90k labels in total, 360-Indoor achieves the largest dataset for detection in 360{\deg} images. In the end, extensive experiments on the state-of-the-art methods for both classification and detection are provided. We will release this dataset in the near future.
Self-view Grounding Given a Narrated 360° Video
Nov 23, 2017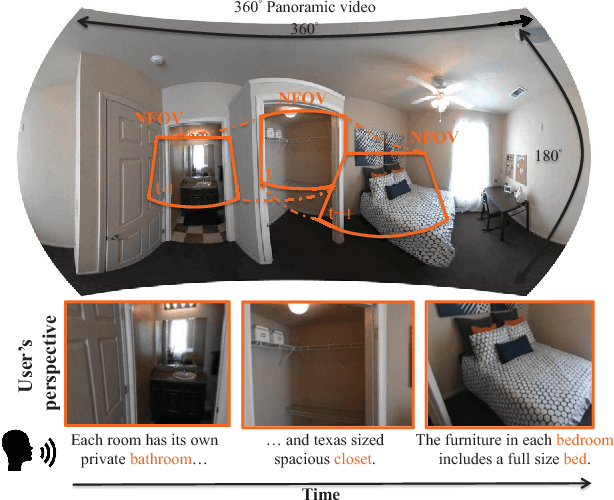
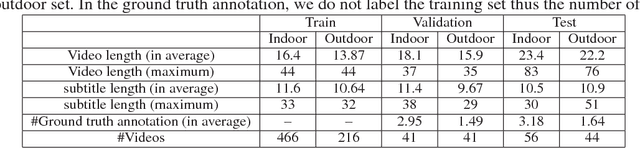
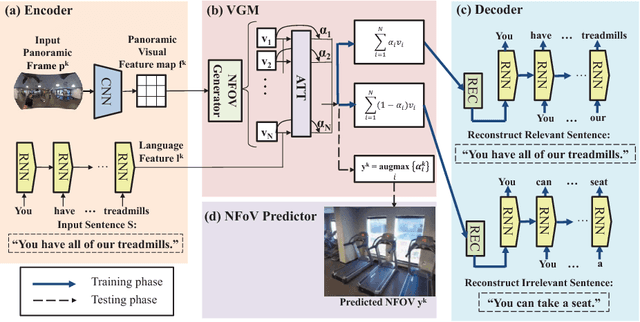
Narrated 360{\deg} videos are typically provided in many touring scenarios to mimic real-world experience. However, previous work has shown that smart assistance (i.e., providing visual guidance) can significantly help users to follow the Normal Field of View (NFoV) corresponding to the narrative. In this project, we aim at automatically grounding the NFoVs of a 360{\deg} video given subtitles of the narrative (referred to as "NFoV-grounding"). We propose a novel Visual Grounding Model (VGM) to implicitly and efficiently predict the NFoVs given the video content and subtitles. Specifically, at each frame, we efficiently encode the panorama into feature map of candidate NFoVs using a Convolutional Neural Network (CNN) and the subtitles to the same hidden space using an RNN with Gated Recurrent Units (GRU). Then, we apply soft-attention on candidate NFoVs to trigger sentence decoder aiming to minimize the reconstruct loss between the generated and given sentence. Finally, we obtain the NFoV as the candidate NFoV with the maximum attention without any human supervision. To train VGM more robustly, we also generate a reverse sentence conditioning on one minus the soft-attention such that the attention focuses on candidate NFoVs less relevant to the given sentence. The negative log reconstruction loss of the reverse sentence (referred to as "irrelevant loss") is jointly minimized to encourage the reverse sentence to be different from the given sentence. To evaluate our method, we collect the first narrated 360{\deg} videos dataset and achieve state-of-the-art NFoV-grounding performance.
Agent-Centric Risk Assessment: Accident Anticipation and Risky Region Localization
May 18, 2017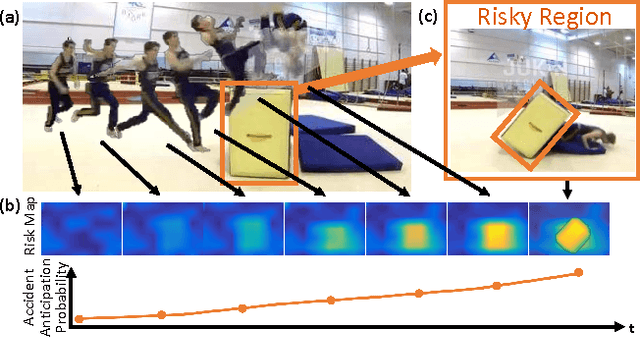
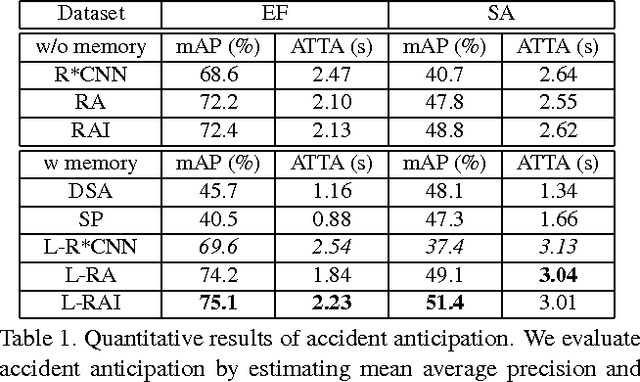
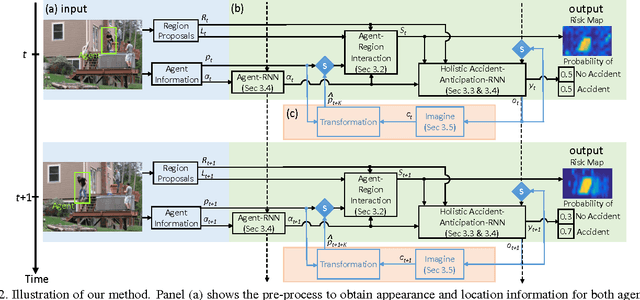
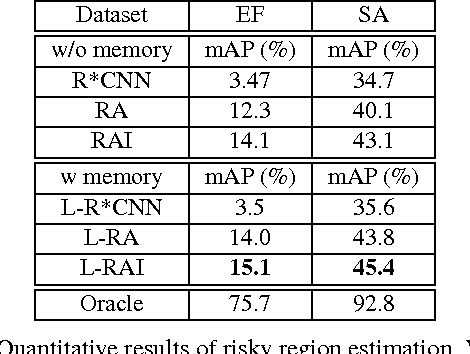
For survival, a living agent must have the ability to assess risk (1) by temporally anticipating accidents before they occur, and (2) by spatially localizing risky regions in the environment to move away from threats. In this paper, we take an agent-centric approach to study the accident anticipation and risky region localization tasks. We propose a novel soft-attention Recurrent Neural Network (RNN) which explicitly models both spatial and appearance-wise non-linear interaction between the agent triggering the event and another agent or static-region involved. In order to test our proposed method, we introduce the Epic Fail (EF) dataset consisting of 3000 viral videos capturing various accidents. In the experiments, we evaluate the risk assessment accuracy both in the temporal domain (accident anticipation) and spatial domain (risky region localization) on our EF dataset and the Street Accident (SA) dataset. Our method consistently outperforms other baselines on both datasets.