 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge360-Indoor: Towards Learning Real-World Objects in 360° Indoor Equirectangular Images
Oct 03, 2019


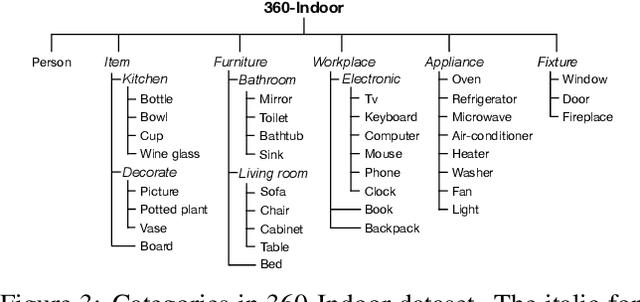
While there are several widely used object detection datasets, current computer vision algorithms are still limited in conventional images. Such images narrow our vision in a restricted region. On the other hand, 360{\deg} images provide a thorough sight. In this paper, our goal is to provide a standard dataset to facilitate the vision and machine learning communities in 360{\deg} domain. To facilitate the research, we present a real-world 360{\deg} panoramic object detection dataset, 360-Indoor, which is a new benchmark for visual object detection and class recognition in 360{\deg} indoor images. It is achieved by gathering images of complex indoor scenes containing common objects and the intensive annotated bounding field-of-view. In addition, 360-Indoor has several distinct properties: (1) the largest category number (37 labels in total). (2) the most complete annotations on average (27 bounding boxes per image). The selected 37 objects are all common in indoor scene. With around 3k images and 90k labels in total, 360-Indoor achieves the largest dataset for detection in 360{\deg} images. In the end, extensive experiments on the state-of-the-art methods for both classification and detection are provided. We will release this dataset in the near future.
Efficient Uncertainty Estimation for Semantic Segmentation in Videos
Jul 29, 2018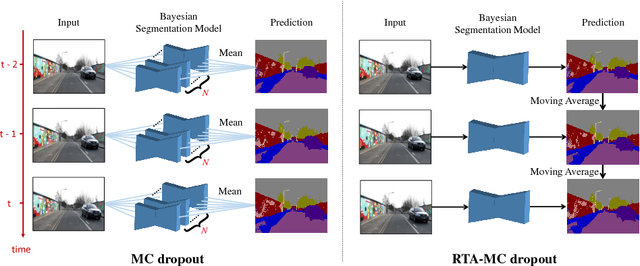
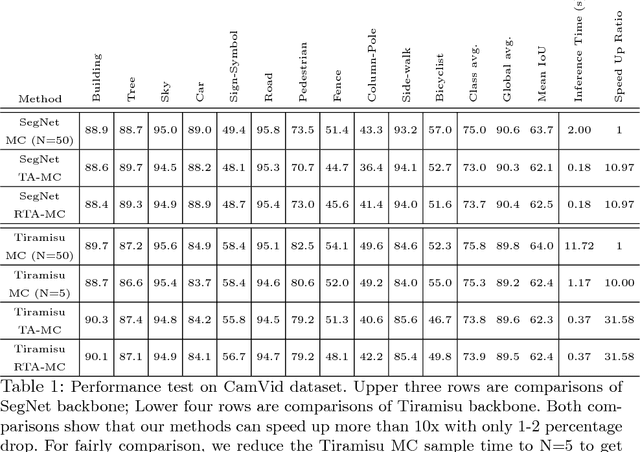
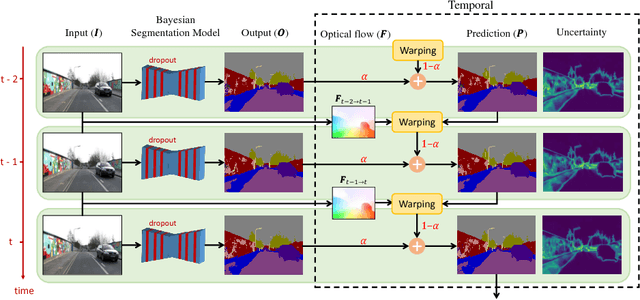

Uncertainty estimation in deep learning becomes more important recently. A deep learning model can't be applied in real applications if we don't know whether the model is certain about the decision or not. Some literature proposes the Bayesian neural network which can estimate the uncertainty by Monte Carlo Dropout (MC dropout). However, MC dropout needs to forward the model $N$ times which results in $N$ times slower. For real-time applications such as a self-driving car system, which needs to obtain the prediction and the uncertainty as fast as possible, so that MC dropout becomes impractical. In this work, we propose the region-based temporal aggregation (RTA) method which leverages the temporal information in videos to simulate the sampling procedure. Our RTA method with Tiramisu backbone is 10x faster than the MC dropout with Tiramisu backbone ($N=5$). Furthermore, the uncertainty estimation obtained by our RTA method is comparable to MC dropout's uncertainty estimation on pixel-level and frame-level metrics.
A Unified Model for Extractive and Abstractive Summarization using Inconsistency Loss
Jul 05, 2018
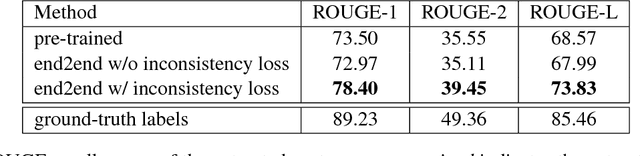
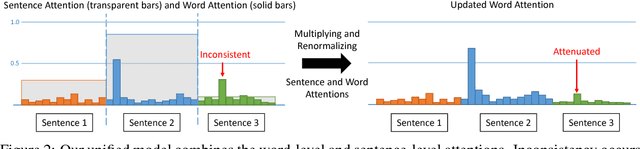
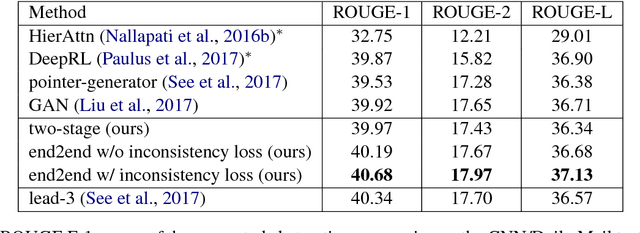
We propose a unified model combining the strength of extractive and abstractive summarization. On the one hand, a simple extractive model can obtain sentence-level attention with high ROUGE scores but less readable. On the other hand, a more complicated abstractive model can obtain word-level dynamic attention to generate a more readable paragraph. In our model, sentence-level attention is used to modulate the word-level attention such that words in less attended sentences are less likely to be generated. Moreover, a novel inconsistency loss function is introduced to penalize the inconsistency between two levels of attentions. By end-to-end training our model with the inconsistency loss and original losses of extractive and abstractive models, we achieve state-of-the-art ROUGE scores while being the most informative and readable summarization on the CNN/Daily Mail dataset in a solid human evaluation.
Show, Adapt and Tell: Adversarial Training of Cross-domain Image Captioner
Aug 14, 2017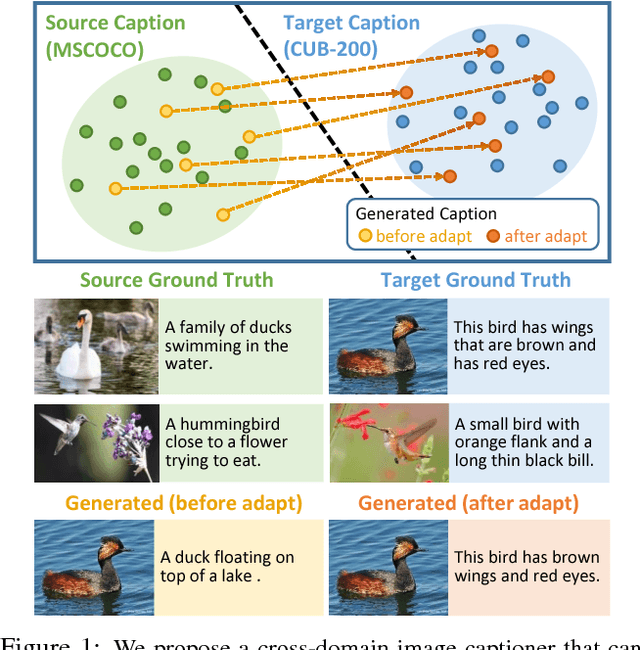
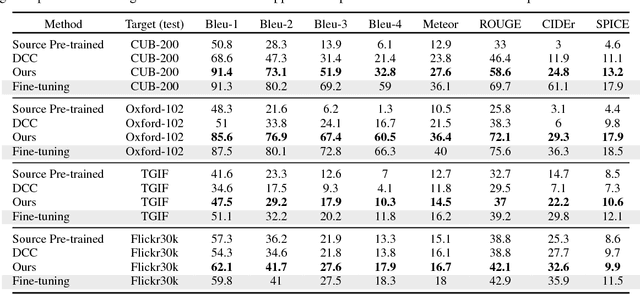
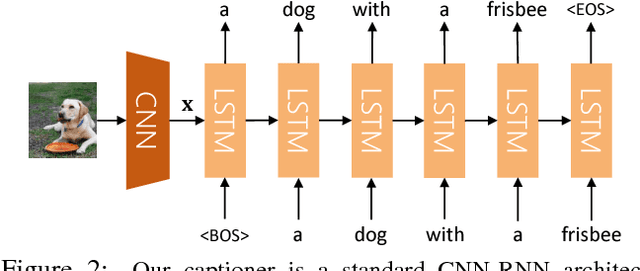
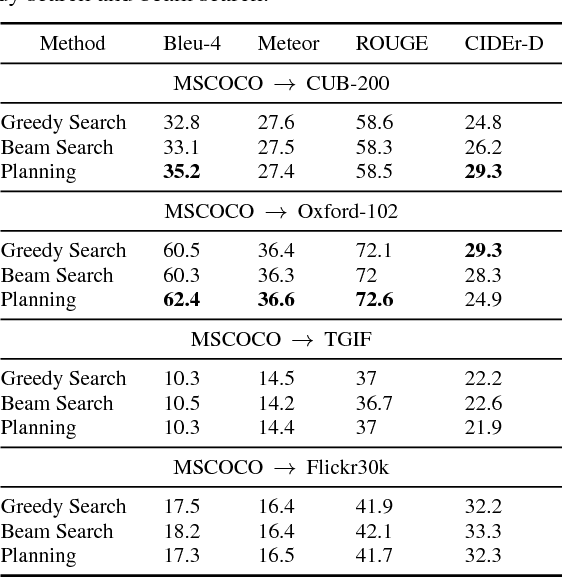
Impressive image captioning results are achieved in domains with plenty of training image and sentence pairs (e.g., MSCOCO). However, transferring to a target domain with significant domain shifts but no paired training data (referred to as cross-domain image captioning) remains largely unexplored. We propose a novel adversarial training procedure to leverage unpaired data in the target domain. Two critic networks are introduced to guide the captioner, namely domain critic and multi-modal critic. The domain critic assesses whether the generated sentences are indistinguishable from sentences in the target domain. The multi-modal critic assesses whether an image and its generated sentence are a valid pair. During training, the critics and captioner act as adversaries -- captioner aims to generate indistinguishable sentences, whereas critics aim at distinguishing them. The assessment improves the captioner through policy gradient updates. During inference, we further propose a novel critic-based planning method to select high-quality sentences without additional supervision (e.g., tags). To evaluate, we use MSCOCO as the source domain and four other datasets (CUB-200-2011, Oxford-102, TGIF, and Flickr30k) as the target domains. Our method consistently performs well on all datasets. In particular, on CUB-200-2011, we achieve 21.8% CIDEr-D improvement after adaptation. Utilizing critics during inference further gives another 4.5% boost.