 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong Grounded Thoughts: Distilling Compositional Visual Reasoning Chains at Scale
Nov 07, 2025Recent progress in multimodal reasoning has been driven largely by undisclosed datasets and proprietary data synthesis recipes, leaving open questions about how to systematically build large-scale, vision-centric reasoning datasets, particularly for tasks that go beyond visual math. In this work, we introduce a new reasoning data generation framework spanning diverse skills and levels of complexity with over 1M high-quality synthetic vision-centric questions. The dataset also includes preference data and instruction prompts supporting both offline and online RL. Our synthesis framework proceeds in two stages: (1) scale; and (2) complexity. Reasoning traces are then synthesized through a two-stage process that leverages VLMs and reasoning LLMs, producing CoT traces for VLMs that capture the richness and diverse cognitive behaviors found in frontier reasoning models. Remarkably, we show that finetuning Qwen2.5-VL-7B on our data outperforms all open-data baselines across all evaluated vision-centric benchmarks, and even surpasses strong closed-data models such as MiMo-VL-7B-RL on V* Bench, CV-Bench and MMStar-V. Perhaps most surprising, despite being entirely vision-centric, our data transfers positively to text-only reasoning (MMLU-Pro) and audio reasoning (MMAU), demonstrating its effectiveness. Similarly, despite not containing videos or embodied visual data, we observe notable gains when evaluating on a single-evidence embodied QA benchmark (NiEH). Finally, we use our data to analyze the entire VLM post-training pipeline. Our empirical analysis highlights that (i) SFT on high-quality data with non-linear reasoning traces is essential for effective online RL, (ii) staged offline RL matches online RL's performance while reducing compute demands, and (iii) careful SFT on high quality data can substantially improve out-of-domain, cross-modality transfer.
LongPerceptualThoughts: Distilling System-2 Reasoning for System-1 Perception
Apr 21, 2025Recent reasoning models through test-time scaling have demonstrated that long chain-of-thoughts can unlock substantial performance boosts in hard reasoning tasks such as math and code. However, the benefit of such long thoughts for system-2 reasoning is relatively less explored in other domains such as perceptual tasks where shallower, system-1 reasoning seems sufficient. In this paper, we introduce LongPerceptualThoughts, a new synthetic dataset with 30K long-thought traces for perceptual tasks. The key challenges in synthesizing elaborate reasoning thoughts for perceptual tasks are that off-the-shelf models are not yet equipped with such thinking behavior and that it is not straightforward to build a reliable process verifier for perceptual tasks. Thus, we propose a novel three-stage data synthesis framework that first synthesizes verifiable multiple-choice questions from dense image descriptions, then extracts simple CoTs from VLMs for those verifiable problems, and finally expands those simple thoughts to elaborate long thoughts via frontier reasoning models. In controlled experiments with a strong instruction-tuned 7B model, we demonstrate notable improvements over existing visual reasoning data-generation methods. Our model, trained on the generated dataset, achieves an average +3.4 points improvement over 5 vision-centric benchmarks, including +11.8 points on V$^*$ Bench. Notably, despite being tuned for vision tasks, it also improves performance on the text reasoning benchmark, MMLU-Pro, by +2 points.
Reasoning Paths with Reference Objects Elicit Quantitative Spatial Reasoning in Large Vision-Language Models
Sep 15, 2024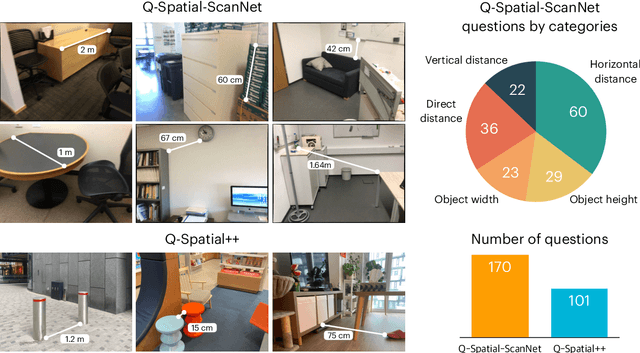
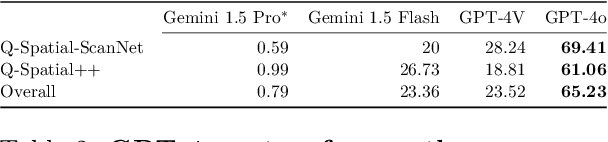

Despite recent advances demonstrating vision-language models' (VLMs) abilities to describe complex relationships in images using natural language, their capability to quantitatively reason about object sizes and distances remains underexplored. In this work, we introduce a manually annotated benchmark, Q-Spatial Bench, with 271 questions across five categories designed for quantitative spatial reasoning and systematically investigate the performance of state-of-the-art VLMs on this task. Our analysis reveals that reasoning about distances between objects is particularly challenging for SoTA VLMs; however, some VLMs significantly outperform others, with an over 40-point gap between the two best performing models. We also make the surprising observation that the success rate of the top-performing VLM increases by 19 points when a reasoning path using a reference object emerges naturally in the response. Inspired by this observation, we develop a zero-shot prompting technique, SpatialPrompt, that encourages VLMs to answer quantitative spatial questions using reference objects as visual cues. By instructing VLMs to use reference objects in their reasoning paths via SpatialPrompt, Gemini 1.5 Pro, Gemini 1.5 Flash, and GPT-4V improve their success rates by over 40, 20, and 30 points, respectively. We emphasize that these significant improvements are obtained without needing more data, model architectural modifications, or fine-tuning.
Can Feedback Enhance Semantic Grounding in Large Vision-Language Models?
Apr 09, 2024Enhancing semantic grounding abilities in Vision-Language Models (VLMs) often involves collecting domain-specific training data, refining the network architectures, or modifying the training recipes. In this work, we venture into an orthogonal direction and explore whether VLMs can improve their semantic grounding by "receiving" feedback, without requiring in-domain data, fine-tuning, or modifications to the network architectures. We systematically analyze this hypothesis using a feedback mechanism composed of a binary signal. We find that if prompted appropriately, VLMs can utilize feedback both in a single step and iteratively, showcasing the potential of feedback as an alternative technique to improve grounding in internet-scale VLMs. Furthermore, VLMs, like LLMs, struggle to self-correct errors out-of-the-box. However, we find that this issue can be mitigated via a binary verification mechanism. Finally, we explore the potential and limitations of amalgamating these findings and applying them iteratively to automatically enhance VLMs' grounding performance, showing grounding accuracy consistently improves using automated feedback across all models in all settings investigated. Overall, our iterative framework improves semantic grounding in VLMs by more than 15 accuracy points under noise-free feedback and up to 5 accuracy points under a simple automated binary verification mechanism. The project website is hosted at https://andrewliao11.github.io/vlms_feedback
Towards Good Practices for Efficiently Annotating Large-Scale Image Classification Datasets
Apr 26, 2021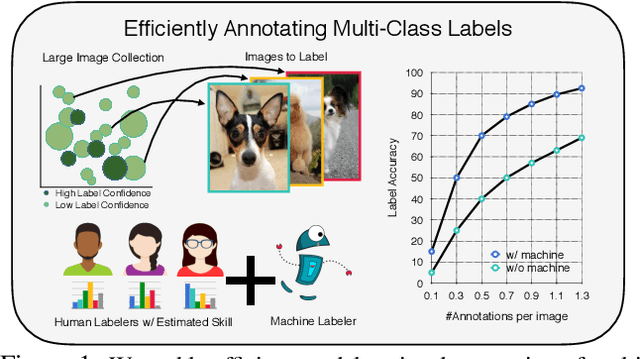

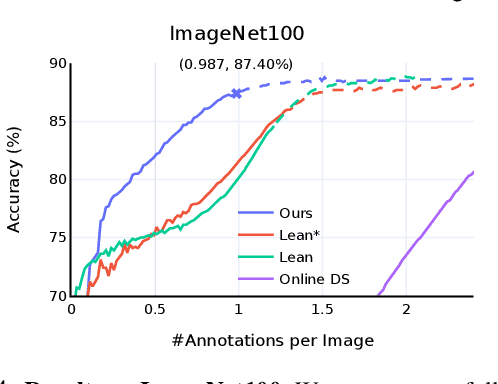
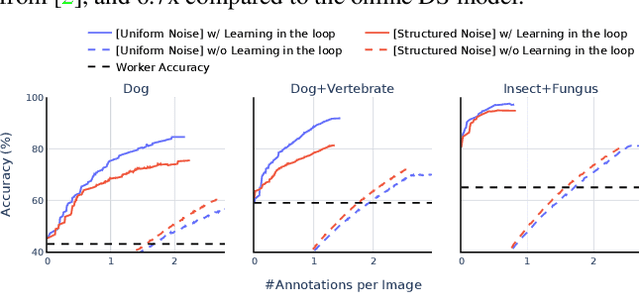
Data is the engine of modern computer vision, which necessitates collecting large-scale datasets. This is expensive, and guaranteeing the quality of the labels is a major challenge. In this paper, we investigate efficient annotation strategies for collecting multi-class classification labels for a large collection of images. While methods that exploit learnt models for labeling exist, a surprisingly prevalent approach is to query humans for a fixed number of labels per datum and aggregate them, which is expensive. Building on prior work on online joint probabilistic modeling of human annotations and machine-generated beliefs, we propose modifications and best practices aimed at minimizing human labeling effort. Specifically, we make use of advances in self-supervised learning, view annotation as a semi-supervised learning problem, identify and mitigate pitfalls and ablate several key design choices to propose effective guidelines for labeling. Our analysis is done in a more realistic simulation that involves querying human labelers, which uncovers issues with evaluation using existing worker simulation methods. Simulated experiments on a 125k image subset of the ImageNet100 show that it can be annotated to 80% top-1 accuracy with 0.35 annotations per image on average, a 2.7x and 6.7x improvement over prior work and manual annotation, respectively. Project page: https://fidler-lab.github.io/efficient-annotation-cookbook
Emergent Road Rules In Multi-Agent Driving Environments
Nov 21, 2020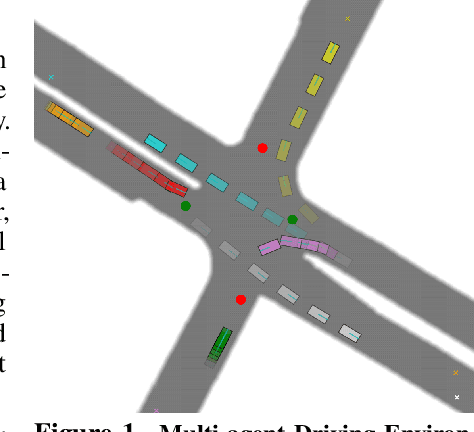
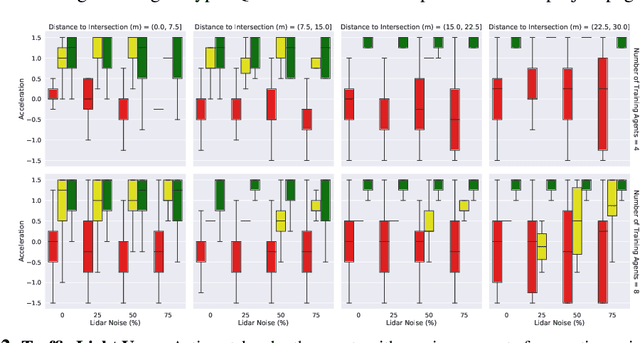
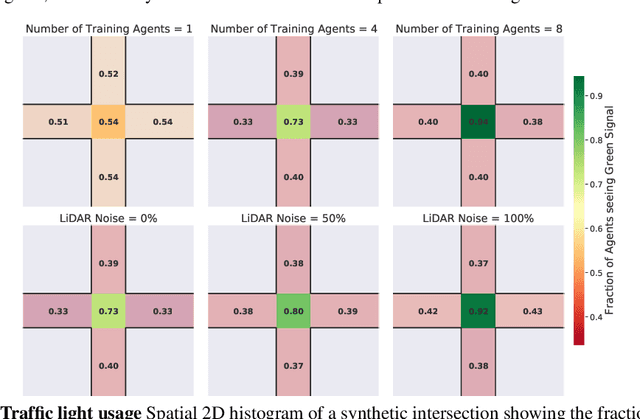
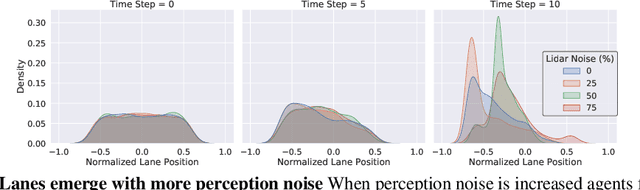
For autonomous vehicles to safely share the road with human drivers, autonomous vehicles must abide by specific "road rules" that human drivers have agreed to follow. "Road rules" include rules that drivers are required to follow by law -- such as the requirement that vehicles stop at red lights -- as well as more subtle social rules -- such as the implicit designation of fast lanes on the highway. In this paper, we provide empirical evidence that suggests that -- instead of hard-coding road rules into self-driving algorithms -- a scalable alternative may be to design multi-agent environments in which road rules emerge as optimal solutions to the problem of maximizing traffic flow. We analyze what ingredients in driving environments cause the emergence of these road rules and find that two crucial factors are noisy perception and agents' spatial density. We provide qualitative and quantitative evidence of the emergence of seven social driving behaviors, ranging from obeying traffic signals to following lanes, all of which emerge from training agents to drive quickly to destinations without colliding. Our results add empirical support for the social road rules that countries worldwide have agreed on for safe, efficient driving.
Show, Adapt and Tell: Adversarial Training of Cross-domain Image Captioner
Aug 14, 2017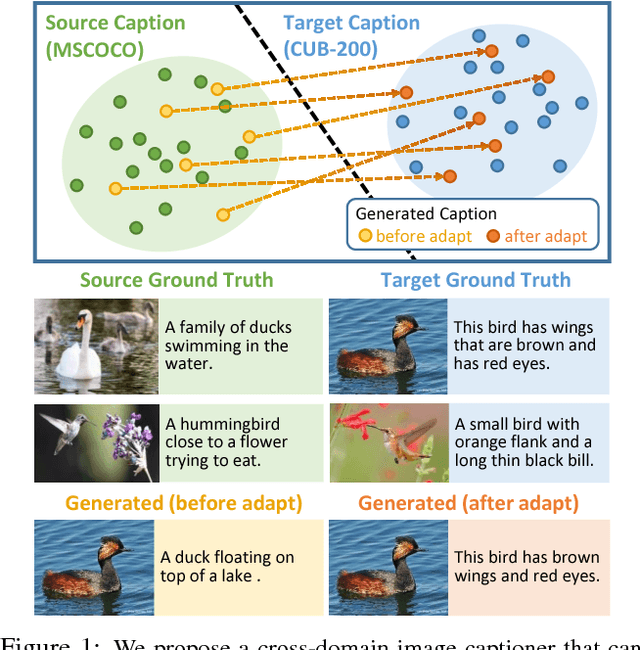
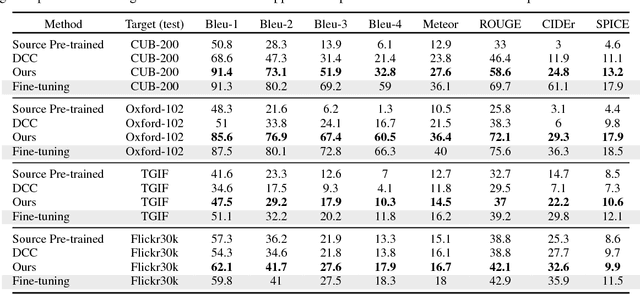
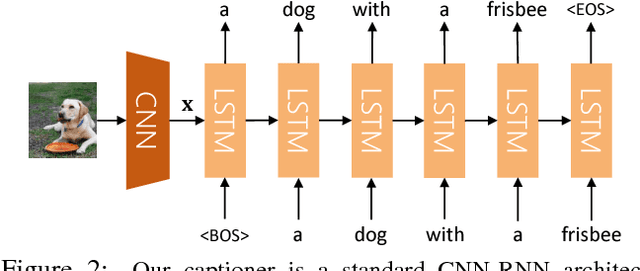
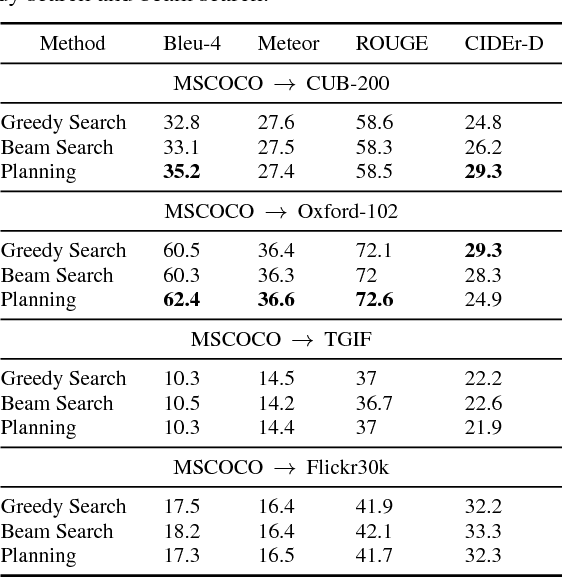
Impressive image captioning results are achieved in domains with plenty of training image and sentence pairs (e.g., MSCOCO). However, transferring to a target domain with significant domain shifts but no paired training data (referred to as cross-domain image captioning) remains largely unexplored. We propose a novel adversarial training procedure to leverage unpaired data in the target domain. Two critic networks are introduced to guide the captioner, namely domain critic and multi-modal critic. The domain critic assesses whether the generated sentences are indistinguishable from sentences in the target domain. The multi-modal critic assesses whether an image and its generated sentence are a valid pair. During training, the critics and captioner act as adversaries -- captioner aims to generate indistinguishable sentences, whereas critics aim at distinguishing them. The assessment improves the captioner through policy gradient updates. During inference, we further propose a novel critic-based planning method to select high-quality sentences without additional supervision (e.g., tags). To evaluate, we use MSCOCO as the source domain and four other datasets (CUB-200-2011, Oxford-102, TGIF, and Flickr30k) as the target domains. Our method consistently performs well on all datasets. In particular, on CUB-200-2011, we achieve 21.8% CIDEr-D improvement after adaptation. Utilizing critics during inference further gives another 4.5% boost.
Tactics of Adversarial Attack on Deep Reinforcement Learning Agents
May 23, 2017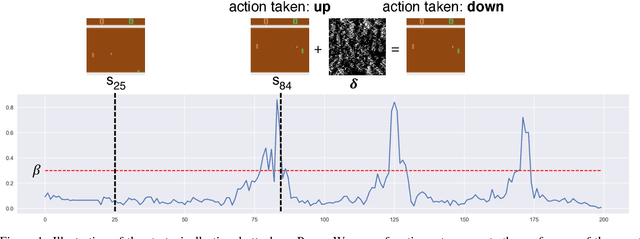
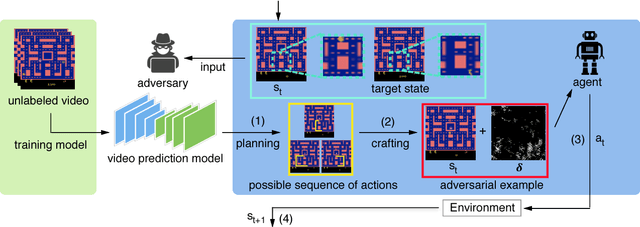

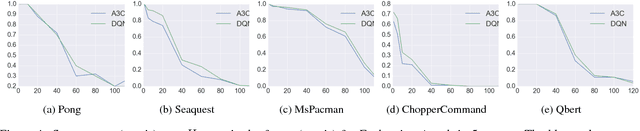
We introduce two tactics to attack agents trained by deep reinforcement learning algorithms using adversarial examples, namely the strategically-timed attack and the enchanting attack. In the strategically-timed attack, the adversary aims at minimizing the agent's reward by only attacking the agent at a small subset of time steps in an episode. Limiting the attack activity to this subset helps prevent detection of the attack by the agent. We propose a novel method to determine when an adversarial example should be crafted and applied. In the enchanting attack, the adversary aims at luring the agent to a designated target state. This is achieved by combining a generative model and a planning algorithm: while the generative model predicts the future states, the planning algorithm generates a preferred sequence of actions for luring the agent. A sequence of adversarial examples is then crafted to lure the agent to take the preferred sequence of actions. We apply the two tactics to the agents trained by the state-of-the-art deep reinforcement learning algorithm including DQN and A3C. In 5 Atari games, our strategically timed attack reduces as much reward as the uniform attack (i.e., attacking at every time step) does by attacking the agent 4 times less often. Our enchanting attack lures the agent toward designated target states with a more than 70% success rate. Videos are available at http://yclin.me/adversarial_attack_RL/
Leveraging Video Descriptions to Learn Video Question Answering
Dec 19, 2016
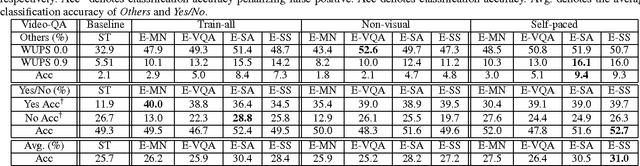

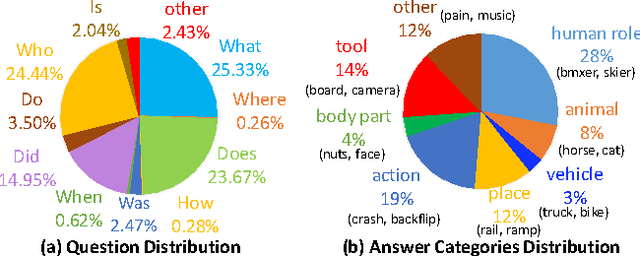
We propose a scalable approach to learn video-based question answering (QA): answer a "free-form natural language question" about a video content. Our approach automatically harvests a large number of videos and descriptions freely available online. Then, a large number of candidate QA pairs are automatically generated from descriptions rather than manually annotated. Next, we use these candidate QA pairs to train a number of video-based QA methods extended fromMN (Sukhbaatar et al. 2015), VQA (Antol et al. 2015), SA (Yao et al. 2015), SS (Venugopalan et al. 2015). In order to handle non-perfect candidate QA pairs, we propose a self-paced learning procedure to iteratively identify them and mitigate their effects in training. Finally, we evaluate performance on manually generated video-based QA pairs. The results show that our self-paced learning procedure is effective, and the extended SS model outperforms various baselines.