 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoSTA: Cognitive-State-Conditioned TTS Data Augmentation Using ASR Transcripts for Alzheimer's Disease Detection
Jun 04, 2026Speech-based Alzheimer's Disease (AD) detection is constrained by scarce pathological speech data. To address this, we propose CoSTA, a Text-to-Speech (TTS)-based data augmentation framework. Specifically, we first develop two Cognitive-State-Conditioned (CS-Cond) TTS models by adapting CosyVoice2 and F5-TTS to synthesize speech with distinct AD and Healthy Control characteristics. Furthermore, by constructing a transcript pool comprising Manual Transcripts (MT) and 36 Automatic Speech Recognition (ASR) transcripts, we investigate the impact of text sources on TTS-based augmentation. We also perform augmentation-factor analysis and test-time augmentation. Experiments on the ADReSS dataset show that CS-Cond TTS significantly improves synthetic speech utility, and ASR-driven augmentation frequently outperforms MT-driven augmentation. Finally, CoSTA yields a 4.16% gain over the baseline, achieving an audio-only accuracy of 85.83% on the ADReSS test set and outperforming prior methods.
OptiWorld: Optimal Control for Video World Generation under Physical Constraints
May 30, 2026Video generation models are becoming a scalable form of world models, but they mainly generate plausible motion rather than proactively control or optimize the underlying dynamics. As a result, an object in the generated video may follow trajectories that are unsafe, not smooth, inefficient, or physically inconsistent. In this work, we propose \textbf{OptiWorld}, a framework that brings classical optimal control into video generation at inference time. OptiWorld first extracts a compact, task-relevant world state, then plans an optimal trajectory under physical constraints, and finally renders the video conditioned on this trajectory. We formulate planning as a geometric problem on a continuous manifold, which converts 3D geometry and task-dependent physical constraints into a unified planning geometry. By adding this optimal-control layer, OptiWorld generates videos with preferable dynamics, demonstrating strong potential in multiple tasks including goal-conditioned image-to-video generation, video dynamics editing, and counterfactual generation.
PhysAlign: Physics-Coherent Image-to-Video Generation through Feature and 3D Representation Alignment
Mar 14, 2026Video Diffusion Models (VDMs) offer a promising approach for simulating dynamic scenes and environments, with broad applications in robotics and media generation. However, existing models often generate temporally incoherent content that violates basic physical intuition, significantly limiting their practical applicability. We propose PhysAlign, an efficient framework for physics-coherent image-to-video (I2V) generation that explicitly addresses this limitation. To overcome the critical scarcity of physics-annotated videos, we first construct a fully controllable synthetic data generation pipeline based on rigid-body simulation, yielding a highly-curated dataset with accurate, fine-grained physics and 3D annotations. Leveraging this data, PhysAlign constructs a unified physical latent space by coupling explicit 3D geometry constraints with a Gram-based spatio-temporal relational alignment that extracts kinematic priors from video foundation models. Extensive experiments demonstrate that PhysAlign significantly outperforms existing VDMs on tasks requiring complex physical reasoning and temporal stability, without compromising zero-shot visual quality. PhysAlign shows the potential to bridge the gap between raw visual synthesis and rigid-body kinematics, establishing a practical paradigm for genuinely physics-grounded video generation. The project page is available at https://physalign.github.io/PhysAlign.
The Vision Wormhole: Latent-Space Communication in Heterogeneous Multi-Agent Systems
Feb 17, 2026Multi-Agent Systems (MAS) powered by Large Language Models have unlocked advanced collaborative reasoning, yet they remain shackled by the inefficiency of discrete text communication, which imposes significant runtime overhead and information quantization loss. While latent state transfer offers a high-bandwidth alternative, existing approaches either assume homogeneous sender-receiver architectures or rely on pair-specific learned translators, limiting scalability and modularity across diverse model families with disjoint manifolds. In this work, we propose the Vision Wormhole, a novel framework that repurposes the visual interface of Vision-Language Models (VLMs) to enable model-agnostic, text-free communication. By introducing a Universal Visual Codec, we map heterogeneous reasoning traces into a shared continuous latent space and inject them directly into the receiver's visual pathway, effectively treating the vision encoder as a universal port for inter-agent telepathy. Our framework adopts a hub-and-spoke topology to reduce pairwise alignment complexity from O(N^2) to O(N) and leverages a label-free, teacher-student distillation objective to align the high-speed visual channel with the robust reasoning patterns of the text pathway. Extensive experiments across heterogeneous model families (e.g., Qwen-VL, Gemma) demonstrate that the Vision Wormhole reduces end-to-end wall-clock time in controlled comparisons while maintaining reasoning fidelity comparable to standard text-based MAS. Code is available at https://github.com/xz-liu/heterogeneous-latent-mas
Incorporating Cognitive Biases into Reinforcement Learning for Financial Decision-Making
Jan 13, 2026Financial markets are influenced by human behavior that deviates from rationality due to cognitive biases. Traditional reinforcement learning (RL) models for financial decision-making assume rational agents, potentially overlooking the impact of psychological factors. This study integrates cognitive biases into RL frameworks for financial trading, hypothesizing that such models can exhibit human-like trading behavior and achieve better risk-adjusted returns than standard RL agents. We introduce biases, such as overconfidence and loss aversion, into reward structures and decision-making processes and evaluate their performance in simulated and real-world trading environments. Despite its inconclusive or negative results, this study provides insights into the challenges of incorporating human-like biases into RL, offering valuable lessons for developing robust financial AI systems.
Exploring Gender Bias in Alzheimer's Disease Detection: Insights from Mandarin and Greek Speech Perception
Jul 16, 2025
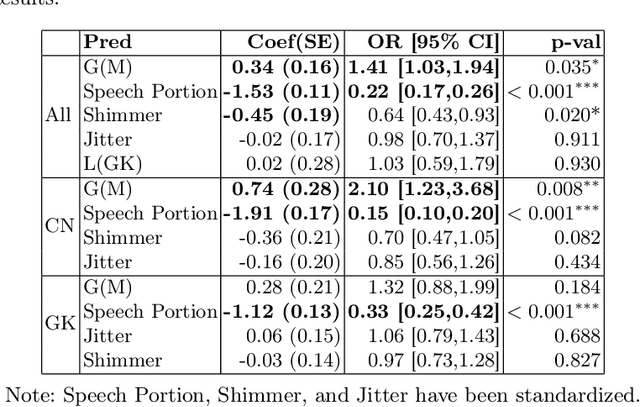
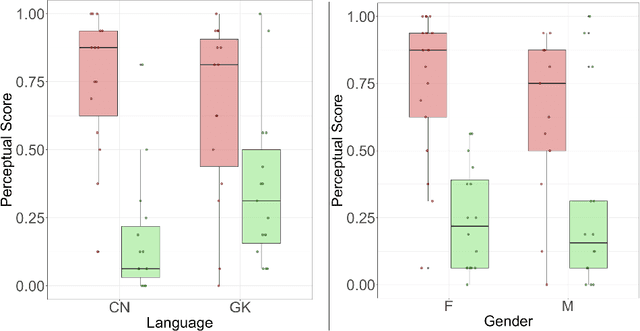
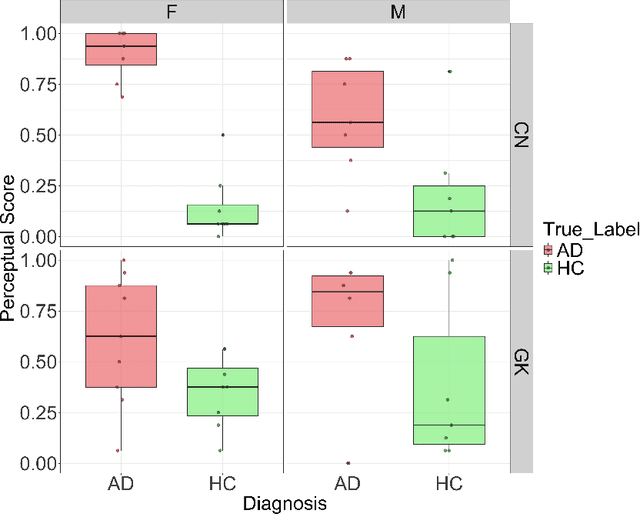
Gender bias has been widely observed in speech perception tasks, influenced by the fundamental voicing differences between genders. This study reveals a gender bias in the perception of Alzheimer's Disease (AD) speech. In a perception experiment involving 16 Chinese listeners evaluating both Chinese and Greek speech, we identified that male speech was more frequently identified as AD, with this bias being particularly pronounced in Chinese speech. Acoustic analysis showed that shimmer values in male speech were significantly associated with AD perception, while speech portion exhibited a significant negative correlation with AD identification. Although language did not have a significant impact on AD perception, our findings underscore the critical role of gender bias in AD speech perception. This work highlights the necessity of addressing gender bias when developing AD detection models and calls for further research to validate model performance across different linguistic contexts.
MMIG-Bench: Towards Comprehensive and Explainable Evaluation of Multi-Modal Image Generation Models
May 26, 2025Recent multimodal image generators such as GPT-4o, Gemini 2.0 Flash, and Gemini 2.5 Pro excel at following complex instructions, editing images and maintaining concept consistency. However, they are still evaluated by disjoint toolkits: text-to-image (T2I) benchmarks that lacks multi-modal conditioning, and customized image generation benchmarks that overlook compositional semantics and common knowledge. We propose MMIG-Bench, a comprehensive Multi-Modal Image Generation Benchmark that unifies these tasks by pairing 4,850 richly annotated text prompts with 1,750 multi-view reference images across 380 subjects, spanning humans, animals, objects, and artistic styles. MMIG-Bench is equipped with a three-level evaluation framework: (1) low-level metrics for visual artifacts and identity preservation of objects; (2) novel Aspect Matching Score (AMS): a VQA-based mid-level metric that delivers fine-grained prompt-image alignment and shows strong correlation with human judgments; and (3) high-level metrics for aesthetics and human preference. Using MMIG-Bench, we benchmark 17 state-of-the-art models, including Gemini 2.5 Pro, FLUX, DreamBooth, and IP-Adapter, and validate our metrics with 32k human ratings, yielding in-depth insights into architecture and data design. We will release the dataset and evaluation code to foster rigorous, unified evaluation and accelerate future innovations in multi-modal image generation.
Leveraging Cascaded Binary Classification and Multimodal Fusion for Dementia Detection through Spontaneous Speech
May 26, 2025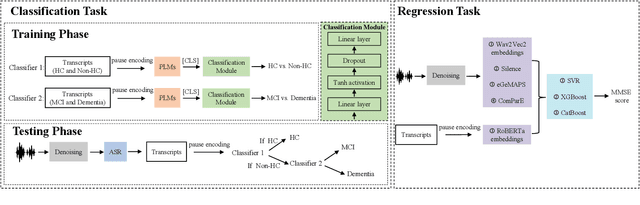
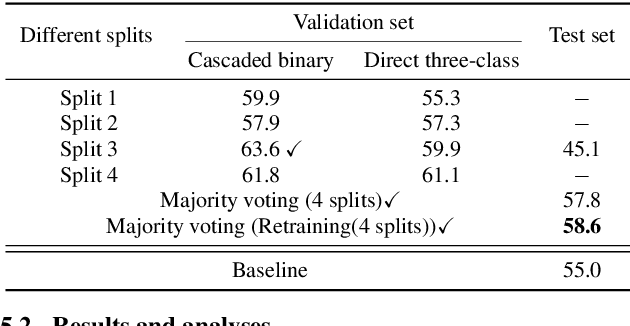
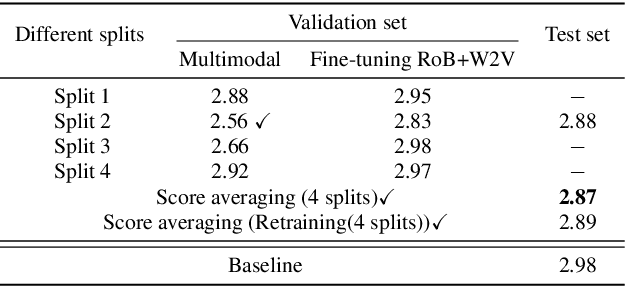
This paper presents our submission to the PROCESS Challenge 2025, focusing on spontaneous speech analysis for early dementia detection. For the three-class classification task (Healthy Control, Mild Cognitive Impairment, and Dementia), we propose a cascaded binary classification framework that fine-tunes pre-trained language models and incorporates pause encoding to better capture disfluencies. This design streamlines multi-class classification and addresses class imbalance by restructuring the decision process. For the Mini-Mental State Examination score regression task, we develop an enhanced multimodal fusion system that combines diverse acoustic and linguistic features. Separate regression models are trained on individual feature sets, with ensemble learning applied through score averaging. Experimental results on the test set outperform the baselines provided by the organizers in both tasks, demonstrating the robustness and effectiveness of our approach.
Building-Block Aware Generative Modeling for 3D Crystals of Metal Organic Frameworks
May 13, 2025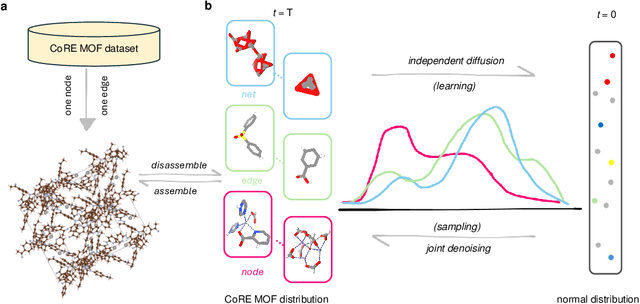
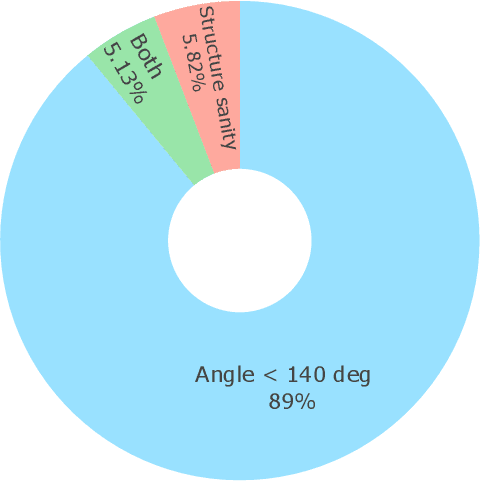
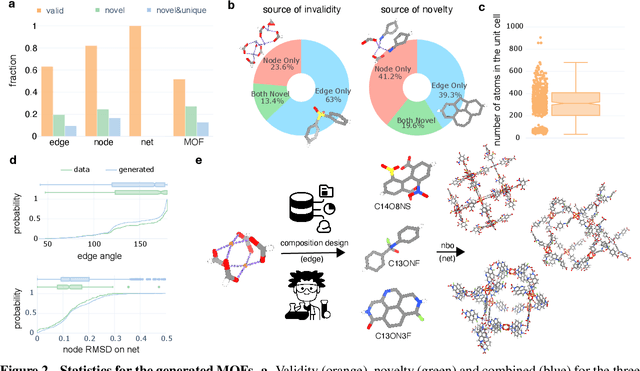
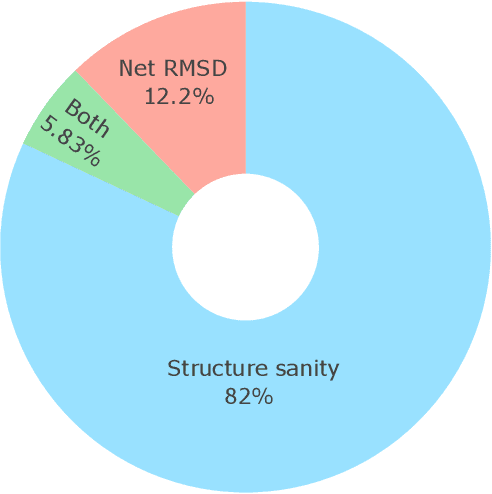
Metal-organic frameworks (MOFs) marry inorganic nodes, organic edges, and topological nets into programmable porous crystals, yet their astronomical design space defies brute-force synthesis. Generative modeling holds ultimate promise, but existing models either recycle known building blocks or are restricted to small unit cells. We introduce Building-Block-Aware MOF Diffusion (BBA MOF Diffusion), an SE(3)-equivariant diffusion model that learns 3D all-atom representations of individual building blocks, encoding crystallographic topological nets explicitly. Trained on the CoRE-MOF database, BBA MOF Diffusion readily samples MOFs with unit cells containing 1000 atoms with great geometric validity, novelty, and diversity mirroring experimental databases. Its native building-block representation produces unprecedented metal nodes and organic edges, expanding accessible chemical space by orders of magnitude. One high-scoring [Zn(1,4-TDC)(EtOH)2] MOF predicted by the model was synthesized, where powder X-ray diffraction, thermogravimetric analysis, and N2 sorption confirm its structural fidelity. BBA-Diff thus furnishes a practical pathway to synthesizable and high-performing MOFs.
LongPerceptualThoughts: Distilling System-2 Reasoning for System-1 Perception
Apr 21, 2025Recent reasoning models through test-time scaling have demonstrated that long chain-of-thoughts can unlock substantial performance boosts in hard reasoning tasks such as math and code. However, the benefit of such long thoughts for system-2 reasoning is relatively less explored in other domains such as perceptual tasks where shallower, system-1 reasoning seems sufficient. In this paper, we introduce LongPerceptualThoughts, a new synthetic dataset with 30K long-thought traces for perceptual tasks. The key challenges in synthesizing elaborate reasoning thoughts for perceptual tasks are that off-the-shelf models are not yet equipped with such thinking behavior and that it is not straightforward to build a reliable process verifier for perceptual tasks. Thus, we propose a novel three-stage data synthesis framework that first synthesizes verifiable multiple-choice questions from dense image descriptions, then extracts simple CoTs from VLMs for those verifiable problems, and finally expands those simple thoughts to elaborate long thoughts via frontier reasoning models. In controlled experiments with a strong instruction-tuned 7B model, we demonstrate notable improvements over existing visual reasoning data-generation methods. Our model, trained on the generated dataset, achieves an average +3.4 points improvement over 5 vision-centric benchmarks, including +11.8 points on V$^*$ Bench. Notably, despite being tuned for vision tasks, it also improves performance on the text reasoning benchmark, MMLU-Pro, by +2 points.