 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKubrick: Multimodal Agent Collaborations for Synthetic Video Generation
Paper and Code
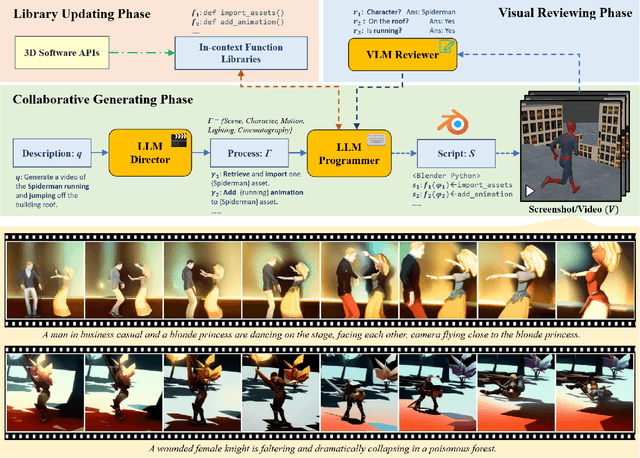
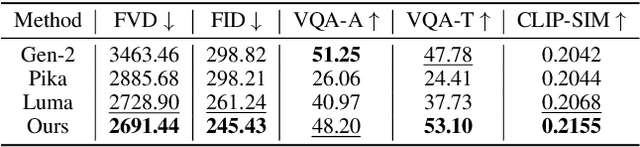

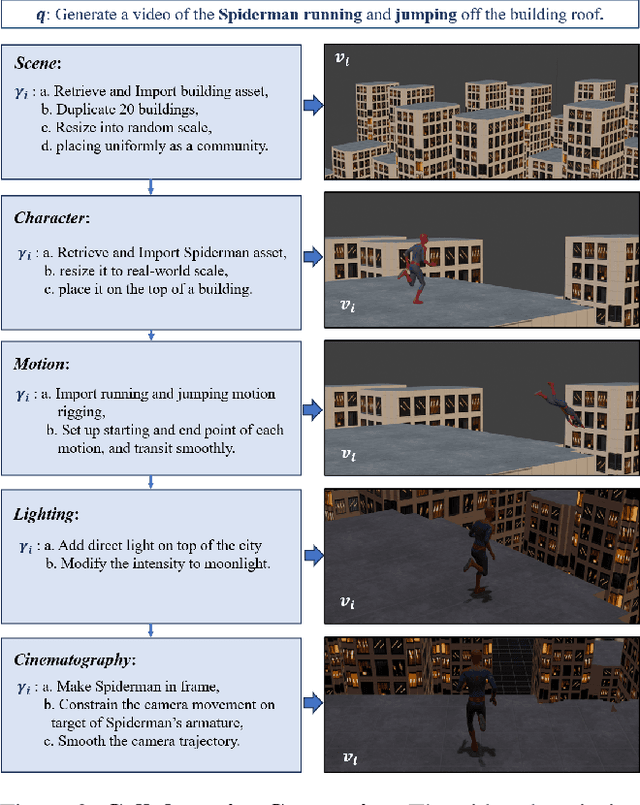
Text-to-video generation has been dominated by end-to-end diffusion-based or autoregressive models. On one hand, those novel models provide plausible versatility, but they are criticized for physical correctness, shading and illumination, camera motion, and temporal consistency. On the other hand, film industry relies on manually-edited Computer-Generated Imagery (CGI) using 3D modeling software. Human-directed 3D synthetic videos and animations address the aforementioned shortcomings, but it is extremely tedious and requires tight collaboration between movie makers and 3D rendering experts. In this paper, we introduce an automatic synthetic video generation pipeline based on Vision Large Language Model (VLM) agent collaborations. Given a natural language description of a video, multiple VLM agents auto-direct various processes of the generation pipeline. They cooperate to create Blender scripts which render a video that best aligns with the given description. Based on film making inspiration and augmented with Blender-based movie making knowledge, the Director agent decomposes the input text-based video description into sub-processes. For each sub-process, the Programmer agent produces Python-based Blender scripts based on customized function composing and API calling. Then, the Reviewer agent, augmented with knowledge of video reviewing, character motion coordinates, and intermediate screenshots uses its compositional reasoning ability to provide feedback to the Programmer agent. The Programmer agent iteratively improves the scripts to yield the best overall video outcome. Our generated videos show better quality than commercial video generation models in 5 metrics on video quality and instruction-following performance. Moreover, our framework outperforms other approaches in a comprehensive user study on quality, consistency, and rationality.