 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysAlign: Physics-Coherent Image-to-Video Generation through Feature and 3D Representation Alignment
Mar 14, 2026Video Diffusion Models (VDMs) offer a promising approach for simulating dynamic scenes and environments, with broad applications in robotics and media generation. However, existing models often generate temporally incoherent content that violates basic physical intuition, significantly limiting their practical applicability. We propose PhysAlign, an efficient framework for physics-coherent image-to-video (I2V) generation that explicitly addresses this limitation. To overcome the critical scarcity of physics-annotated videos, we first construct a fully controllable synthetic data generation pipeline based on rigid-body simulation, yielding a highly-curated dataset with accurate, fine-grained physics and 3D annotations. Leveraging this data, PhysAlign constructs a unified physical latent space by coupling explicit 3D geometry constraints with a Gram-based spatio-temporal relational alignment that extracts kinematic priors from video foundation models. Extensive experiments demonstrate that PhysAlign significantly outperforms existing VDMs on tasks requiring complex physical reasoning and temporal stability, without compromising zero-shot visual quality. PhysAlign shows the potential to bridge the gap between raw visual synthesis and rigid-body kinematics, establishing a practical paradigm for genuinely physics-grounded video generation. The project page is available at https://physalign.github.io/PhysAlign.
ThinkRL-Edit: Thinking in Reinforcement Learning for Reasoning-Centric Image Editing
Jan 06, 2026Instruction-driven image editing with unified multimodal generative models has advanced rapidly, yet their underlying visual reasoning remains limited, leading to suboptimal performance on reasoning-centric edits. Reinforcement learning (RL) has been investigated for improving the quality of image editing, but it faces three key challenges: (1) limited reasoning exploration confined to denoising stochasticity, (2) biased reward fusion, and (3) unstable VLM-based instruction rewards. In this work, we propose ThinkRL-Edit, a reasoning-centric RL framework that decouples visual reasoning from image synthesis and expands reasoning exploration beyond denoising. To the end, we introduce Chain-of-Thought (CoT)-based reasoning sampling with planning and reflection stages prior to generation in online sampling, compelling the model to explore multiple semantic hypotheses and validate their plausibility before committing to a visual outcome. To avoid the failures of weighted aggregation, we propose an unbiased chain preference grouping strategy across multiple reward dimensions. Moreover, we replace interval-based VLM scores with a binary checklist, yielding more precise, lower-variance, and interpretable rewards for complex reasoning. Experiments show our method significantly outperforms prior work on reasoning-centric image editing, producing instruction-faithful, visually coherent, and semantically grounded edits.
Video-LMM Post-Training: A Deep Dive into Video Reasoning with Large Multimodal Models
Oct 06, 2025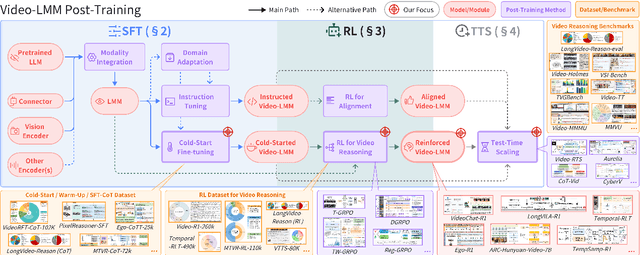
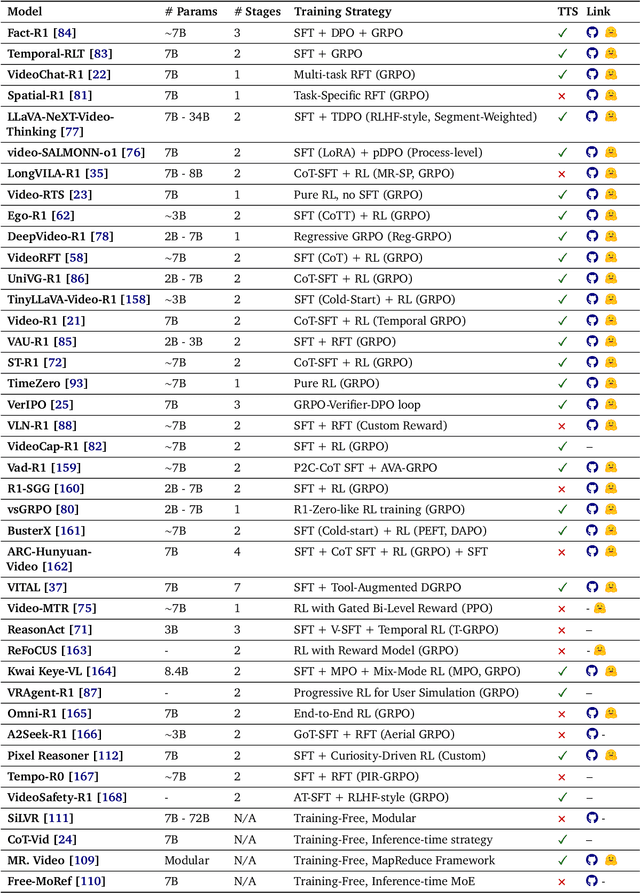
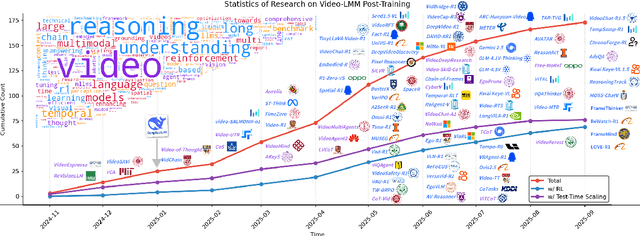
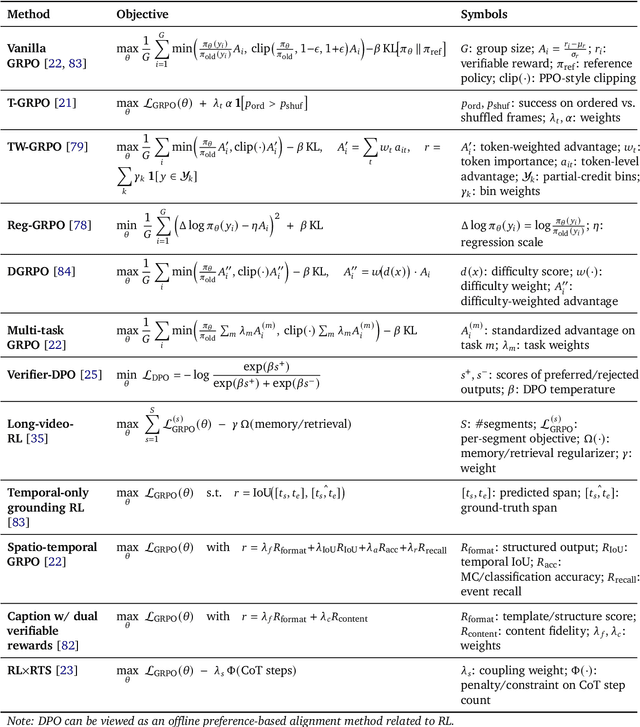
Video understanding represents the most challenging frontier in computer vision, requiring models to reason about complex spatiotemporal relationships, long-term dependencies, and multimodal evidence. The recent emergence of Video-Large Multimodal Models (Video-LMMs), which integrate visual encoders with powerful decoder-based language models, has demonstrated remarkable capabilities in video understanding tasks. However, the critical phase that transforms these models from basic perception systems into sophisticated reasoning engines, post-training, remains fragmented across the literature. This survey provides the first comprehensive examination of post-training methodologies for Video-LMMs, encompassing three fundamental pillars: supervised fine-tuning (SFT) with chain-of-thought, reinforcement learning (RL) from verifiable objectives, and test-time scaling (TTS) through enhanced inference computation. We present a structured taxonomy that clarifies the roles, interconnections, and video-specific adaptations of these techniques, addressing unique challenges such as temporal localization, spatiotemporal grounding, long video efficiency, and multimodal evidence integration. Through systematic analysis of representative methods, we synthesize key design principles, insights, and evaluation protocols while identifying critical open challenges in reward design, scalability, and cost-performance optimization. We further curate essential benchmarks, datasets, and metrics to facilitate rigorous assessment of post-training effectiveness. This survey aims to provide researchers and practitioners with a unified framework for advancing Video-LMM capabilities. Additional resources and updates are maintained at: https://github.com/yunlong10/Awesome-Video-LMM-Post-Training
MMIG-Bench: Towards Comprehensive and Explainable Evaluation of Multi-Modal Image Generation Models
May 26, 2025Recent multimodal image generators such as GPT-4o, Gemini 2.0 Flash, and Gemini 2.5 Pro excel at following complex instructions, editing images and maintaining concept consistency. However, they are still evaluated by disjoint toolkits: text-to-image (T2I) benchmarks that lacks multi-modal conditioning, and customized image generation benchmarks that overlook compositional semantics and common knowledge. We propose MMIG-Bench, a comprehensive Multi-Modal Image Generation Benchmark that unifies these tasks by pairing 4,850 richly annotated text prompts with 1,750 multi-view reference images across 380 subjects, spanning humans, animals, objects, and artistic styles. MMIG-Bench is equipped with a three-level evaluation framework: (1) low-level metrics for visual artifacts and identity preservation of objects; (2) novel Aspect Matching Score (AMS): a VQA-based mid-level metric that delivers fine-grained prompt-image alignment and shows strong correlation with human judgments; and (3) high-level metrics for aesthetics and human preference. Using MMIG-Bench, we benchmark 17 state-of-the-art models, including Gemini 2.5 Pro, FLUX, DreamBooth, and IP-Adapter, and validate our metrics with 32k human ratings, yielding in-depth insights into architecture and data design. We will release the dataset and evaluation code to foster rigorous, unified evaluation and accelerate future innovations in multi-modal image generation.
Caption Anything in Video: Fine-grained Object-centric Captioning via Spatiotemporal Multimodal Prompting
Apr 09, 2025We present CAT-V (Caption AnyThing in Video), a training-free framework for fine-grained object-centric video captioning that enables detailed descriptions of user-selected objects through time. CAT-V integrates three key components: a Segmenter based on SAMURAI for precise object segmentation across frames, a Temporal Analyzer powered by TRACE-Uni for accurate event boundary detection and temporal analysis, and a Captioner using InternVL-2.5 for generating detailed object-centric descriptions. Through spatiotemporal visual prompts and chain-of-thought reasoning, our framework generates detailed, temporally-aware descriptions of objects' attributes, actions, statuses, interactions, and environmental contexts without requiring additional training data. CAT-V supports flexible user interactions through various visual prompts (points, bounding boxes, and irregular regions) and maintains temporal sensitivity by tracking object states and interactions across different time segments. Our approach addresses limitations of existing video captioning methods, which either produce overly abstract descriptions or lack object-level precision, enabling fine-grained, object-specific descriptions while maintaining temporal coherence and spatial accuracy. The GitHub repository for this project is available at https://github.com/yunlong10/CAT-V
Generative AI for Cel-Animation: A Survey
Jan 08, 2025



Traditional Celluloid (Cel) Animation production pipeline encompasses multiple essential steps, including storyboarding, layout design, keyframe animation, inbetweening, and colorization, which demand substantial manual effort, technical expertise, and significant time investment. These challenges have historically impeded the efficiency and scalability of Cel-Animation production. The rise of generative artificial intelligence (GenAI), encompassing large language models, multimodal models, and diffusion models, offers innovative solutions by automating tasks such as inbetween frame generation, colorization, and storyboard creation. This survey explores how GenAI integration is revolutionizing traditional animation workflows by lowering technical barriers, broadening accessibility for a wider range of creators through tools like AniDoc, ToonCrafter, and AniSora, and enabling artists to focus more on creative expression and artistic innovation. Despite its potential, issues such as maintaining visual consistency, ensuring stylistic coherence, and addressing ethical considerations continue to pose challenges. Furthermore, this paper discusses future directions and explores potential advancements in AI-assisted animation. For further exploration and resources, please visit our GitHub repository: https://github.com/yunlong10/Awesome-AI4Animation
Refine-by-Align: Reference-Guided Artifacts Refinement through Semantic Alignment
Nov 30, 2024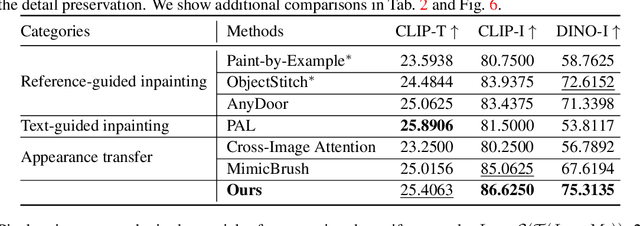

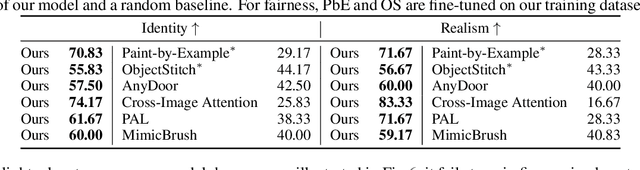
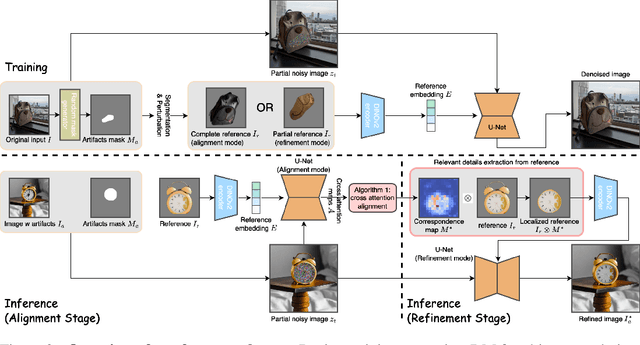
Personalized image generation has emerged from the recent advancements in generative models. However, these generated personalized images often suffer from localized artifacts such as incorrect logos, reducing fidelity and fine-grained identity details of the generated results. Furthermore, there is little prior work tackling this problem. To help improve these identity details in the personalized image generation, we introduce a new task: reference-guided artifacts refinement. We present Refine-by-Align, a first-of-its-kind model that employs a diffusion-based framework to address this challenge. Our model consists of two stages: Alignment Stage and Refinement Stage, which share weights of a unified neural network model. Given a generated image, a masked artifact region, and a reference image, the alignment stage identifies and extracts the corresponding regional features in the reference, which are then used by the refinement stage to fix the artifacts. Our model-agnostic pipeline requires no test-time tuning or optimization. It automatically enhances image fidelity and reference identity in the generated image, generalizing well to existing models on various tasks including but not limited to customization, generative compositing, view synthesis, and virtual try-on. Extensive experiments and comparisons demonstrate that our pipeline greatly pushes the boundary of fine details in the image synthesis models.
GroundingBooth: Grounding Text-to-Image Customization
Sep 13, 2024Recent studies in text-to-image customization show great success in generating personalized object variants given several images of a subject. While existing methods focus more on preserving the identity of the subject, they often fall short of controlling the spatial relationship between objects. In this work, we introduce GroundingBooth, a framework that achieves zero-shot instance-level spatial grounding on both foreground subjects and background objects in the text-to-image customization task. Our proposed text-image grounding module and masked cross-attention layer allow us to generate personalized images with both accurate layout alignment and identity preservation while maintaining text-image coherence. With such layout control, our model inherently enables the customization of multiple subjects at once. Our model is evaluated on both layout-guided image synthesis and reference-based customization tasks, showing strong results compared to existing methods. Our work is the first work to achieve a joint grounding of both subject-driven foreground generation and text-driven background generation.
Thinking Outside the BBox: Unconstrained Generative Object Compositing
Sep 11, 2024Compositing an object into an image involves multiple non-trivial sub-tasks such as object placement and scaling, color/lighting harmonization, viewpoint/geometry adjustment, and shadow/reflection generation. Recent generative image compositing methods leverage diffusion models to handle multiple sub-tasks at once. However, existing models face limitations due to their reliance on masking the original object during training, which constrains their generation to the input mask. Furthermore, obtaining an accurate input mask specifying the location and scale of the object in a new image can be highly challenging. To overcome such limitations, we define a novel problem of unconstrained generative object compositing, i.e., the generation is not bounded by the mask, and train a diffusion-based model on a synthesized paired dataset. Our first-of-its-kind model is able to generate object effects such as shadows and reflections that go beyond the mask, enhancing image realism. Additionally, if an empty mask is provided, our model automatically places the object in diverse natural locations and scales, accelerating the compositing workflow. Our model outperforms existing object placement and compositing models in various quality metrics and user studies.
Kubrick: Multimodal Agent Collaborations for Synthetic Video Generation
Aug 19, 2024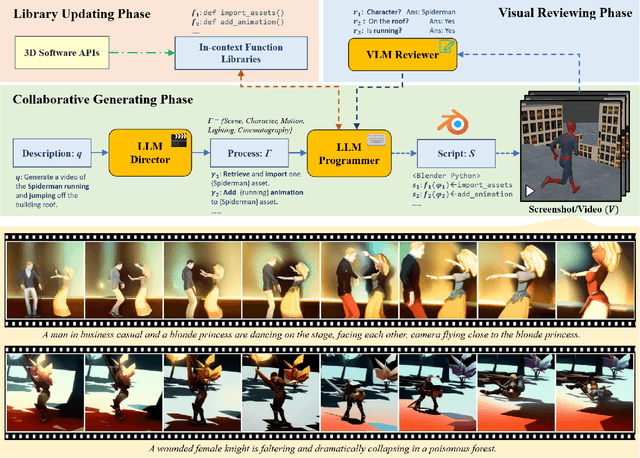
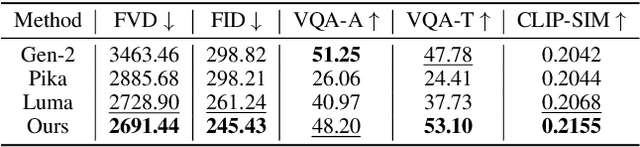

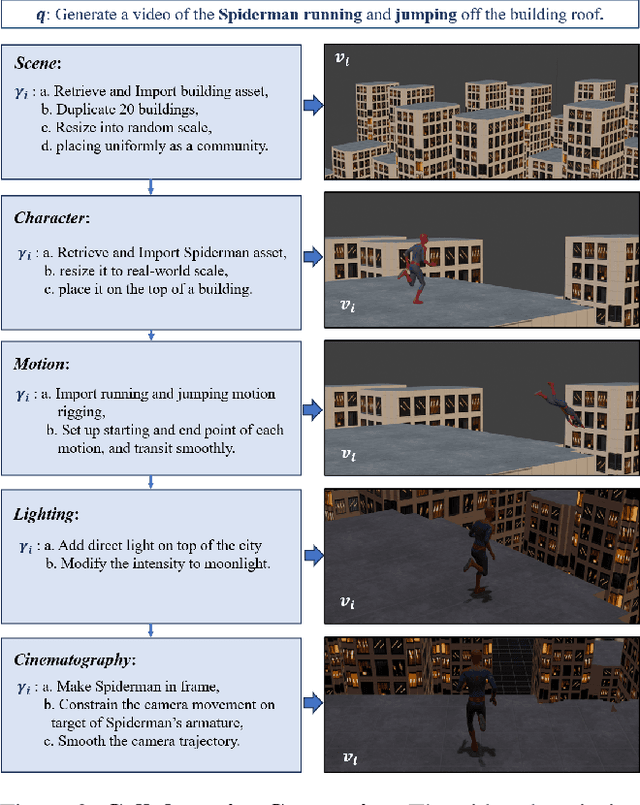
Text-to-video generation has been dominated by end-to-end diffusion-based or autoregressive models. On one hand, those novel models provide plausible versatility, but they are criticized for physical correctness, shading and illumination, camera motion, and temporal consistency. On the other hand, film industry relies on manually-edited Computer-Generated Imagery (CGI) using 3D modeling software. Human-directed 3D synthetic videos and animations address the aforementioned shortcomings, but it is extremely tedious and requires tight collaboration between movie makers and 3D rendering experts. In this paper, we introduce an automatic synthetic video generation pipeline based on Vision Large Language Model (VLM) agent collaborations. Given a natural language description of a video, multiple VLM agents auto-direct various processes of the generation pipeline. They cooperate to create Blender scripts which render a video that best aligns with the given description. Based on film making inspiration and augmented with Blender-based movie making knowledge, the Director agent decomposes the input text-based video description into sub-processes. For each sub-process, the Programmer agent produces Python-based Blender scripts based on customized function composing and API calling. Then, the Reviewer agent, augmented with knowledge of video reviewing, character motion coordinates, and intermediate screenshots uses its compositional reasoning ability to provide feedback to the Programmer agent. The Programmer agent iteratively improves the scripts to yield the best overall video outcome. Our generated videos show better quality than commercial video generation models in 5 metrics on video quality and instruction-following performance. Moreover, our framework outperforms other approaches in a comprehensive user study on quality, consistency, and rationality.