 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen to Think and When to Look: Uncertainty-Guided Lookback
Nov 19, 2025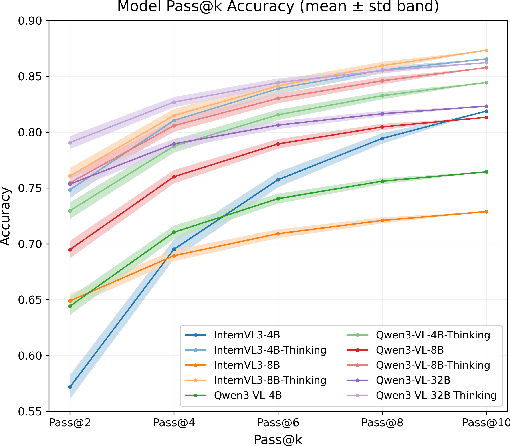

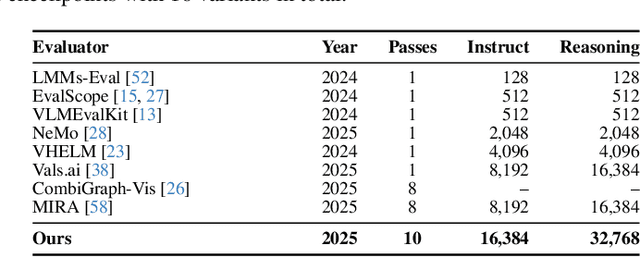
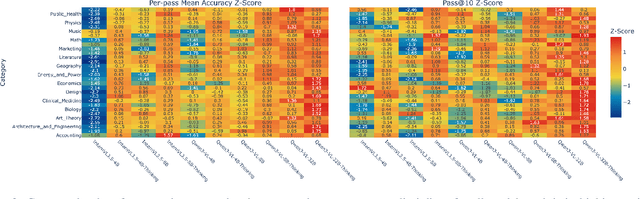
Test-time thinking (that is, generating explicit intermediate reasoning chains) is known to boost performance in large language models and has recently shown strong gains for large vision language models (LVLMs). However, despite these promising results, there is still no systematic analysis of how thinking actually affects visual reasoning. We provide the first such analysis with a large scale, controlled comparison of thinking for LVLMs, evaluating ten variants from the InternVL3.5 and Qwen3-VL families on MMMU-val under generous token budgets and multi pass decoding. We show that more thinking is not always better; long chains often yield long wrong trajectories that ignore the image and underperform the same models run in standard instruct mode. A deeper analysis reveals that certain short lookback phrases, which explicitly refer back to the image, are strongly enriched in successful trajectories and correlate with better visual grounding. Building on this insight, we propose uncertainty guided lookback, a training free decoding strategy that combines an uncertainty signal with adaptive lookback prompts and breadth search. Our method improves overall MMMU performance, delivers the largest gains in categories where standard thinking is weak, and outperforms several strong decoding baselines, setting a new state of the art under fixed model families and token budgets. We further show that this decoding strategy generalizes, yielding consistent improvements on five additional benchmarks, including two broad multimodal suites and math focused visual reasoning datasets.
Video-LMM Post-Training: A Deep Dive into Video Reasoning with Large Multimodal Models
Oct 06, 2025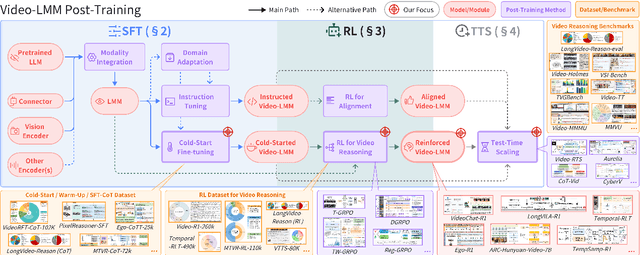
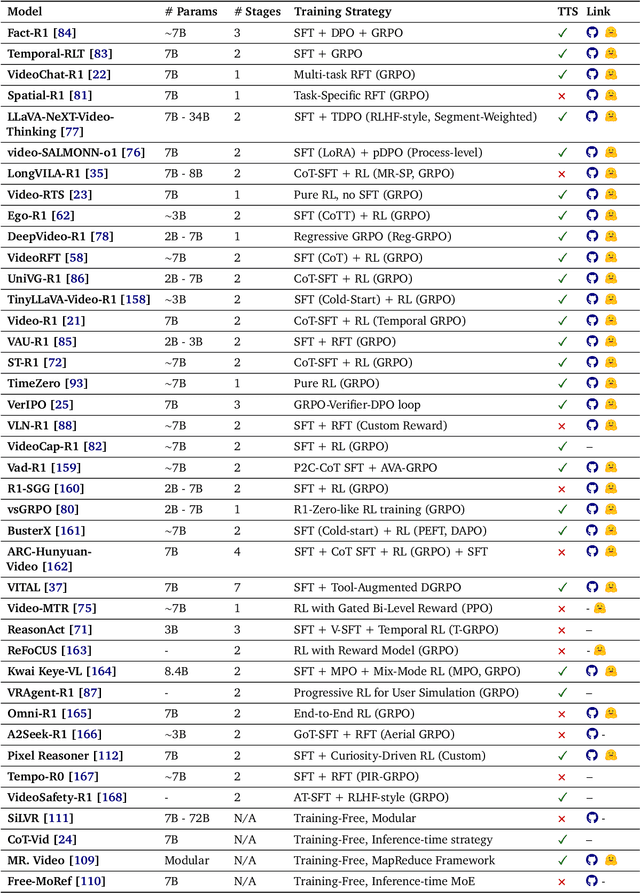
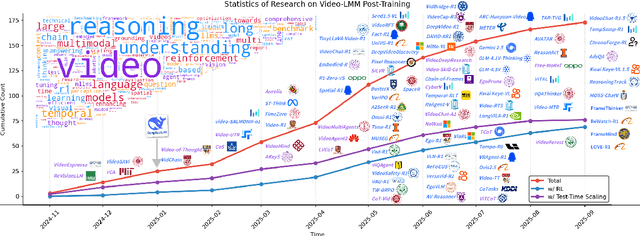
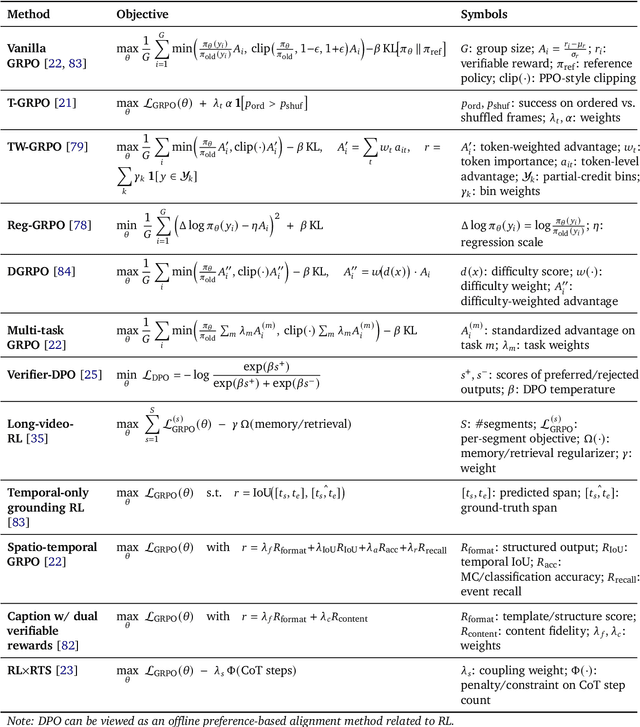
Video understanding represents the most challenging frontier in computer vision, requiring models to reason about complex spatiotemporal relationships, long-term dependencies, and multimodal evidence. The recent emergence of Video-Large Multimodal Models (Video-LMMs), which integrate visual encoders with powerful decoder-based language models, has demonstrated remarkable capabilities in video understanding tasks. However, the critical phase that transforms these models from basic perception systems into sophisticated reasoning engines, post-training, remains fragmented across the literature. This survey provides the first comprehensive examination of post-training methodologies for Video-LMMs, encompassing three fundamental pillars: supervised fine-tuning (SFT) with chain-of-thought, reinforcement learning (RL) from verifiable objectives, and test-time scaling (TTS) through enhanced inference computation. We present a structured taxonomy that clarifies the roles, interconnections, and video-specific adaptations of these techniques, addressing unique challenges such as temporal localization, spatiotemporal grounding, long video efficiency, and multimodal evidence integration. Through systematic analysis of representative methods, we synthesize key design principles, insights, and evaluation protocols while identifying critical open challenges in reward design, scalability, and cost-performance optimization. We further curate essential benchmarks, datasets, and metrics to facilitate rigorous assessment of post-training effectiveness. This survey aims to provide researchers and practitioners with a unified framework for advancing Video-LMM capabilities. Additional resources and updates are maintained at: https://github.com/yunlong10/Awesome-Video-LMM-Post-Training
Caption Anything in Video: Fine-grained Object-centric Captioning via Spatiotemporal Multimodal Prompting
Apr 09, 2025We present CAT-V (Caption AnyThing in Video), a training-free framework for fine-grained object-centric video captioning that enables detailed descriptions of user-selected objects through time. CAT-V integrates three key components: a Segmenter based on SAMURAI for precise object segmentation across frames, a Temporal Analyzer powered by TRACE-Uni for accurate event boundary detection and temporal analysis, and a Captioner using InternVL-2.5 for generating detailed object-centric descriptions. Through spatiotemporal visual prompts and chain-of-thought reasoning, our framework generates detailed, temporally-aware descriptions of objects' attributes, actions, statuses, interactions, and environmental contexts without requiring additional training data. CAT-V supports flexible user interactions through various visual prompts (points, bounding boxes, and irregular regions) and maintains temporal sensitivity by tracking object states and interactions across different time segments. Our approach addresses limitations of existing video captioning methods, which either produce overly abstract descriptions or lack object-level precision, enabling fine-grained, object-specific descriptions while maintaining temporal coherence and spatial accuracy. The GitHub repository for this project is available at https://github.com/yunlong10/CAT-V
Why Reasoning Matters? A Survey of Advancements in Multimodal Reasoning (v1)
Apr 04, 2025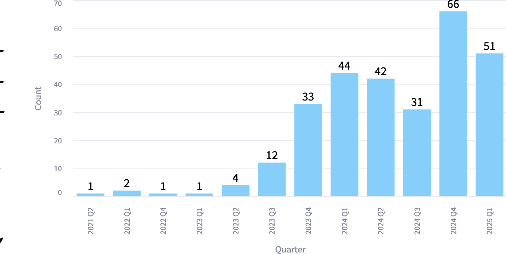
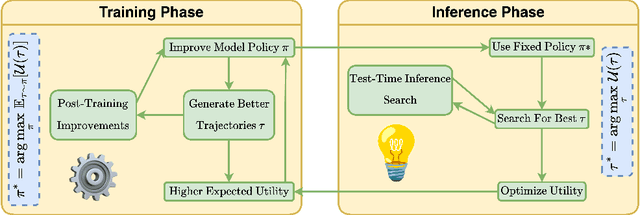
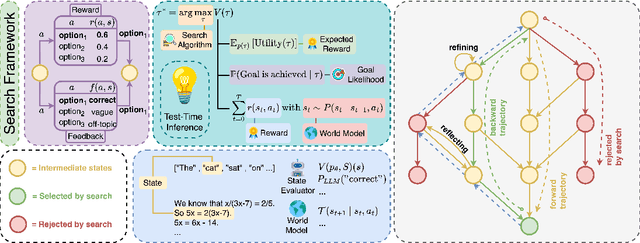
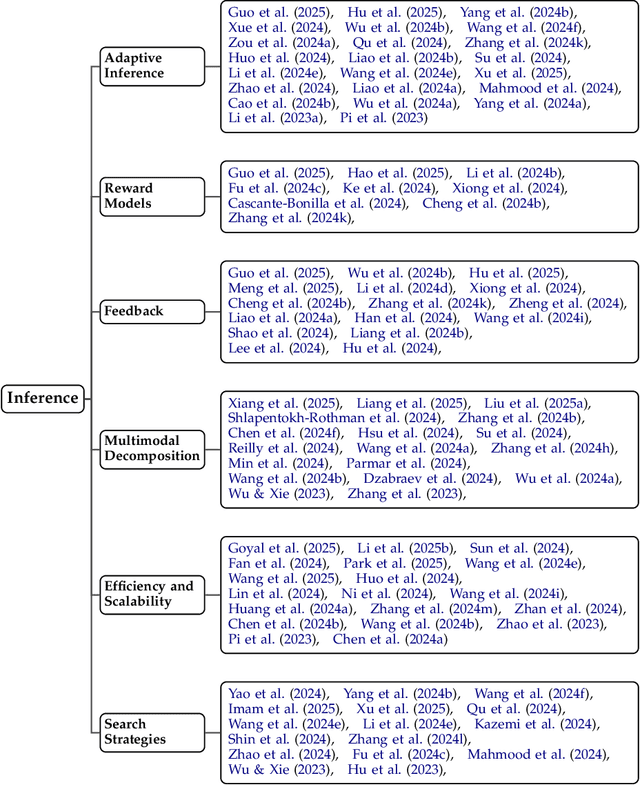
Reasoning is central to human intelligence, enabling structured problem-solving across diverse tasks. Recent advances in large language models (LLMs) have greatly enhanced their reasoning abilities in arithmetic, commonsense, and symbolic domains. However, effectively extending these capabilities into multimodal contexts-where models must integrate both visual and textual inputs-continues to be a significant challenge. Multimodal reasoning introduces complexities, such as handling conflicting information across modalities, which require models to adopt advanced interpretative strategies. Addressing these challenges involves not only sophisticated algorithms but also robust methodologies for evaluating reasoning accuracy and coherence. This paper offers a concise yet insightful overview of reasoning techniques in both textual and multimodal LLMs. Through a thorough and up-to-date comparison, we clearly formulate core reasoning challenges and opportunities, highlighting practical methods for post-training optimization and test-time inference. Our work provides valuable insights and guidance, bridging theoretical frameworks and practical implementations, and sets clear directions for future research.
VERIFY: A Benchmark of Visual Explanation and Reasoning for Investigating Multimodal Reasoning Fidelity
Mar 14, 2025Visual reasoning is central to human cognition, enabling individuals to interpret and abstractly understand their environment. Although recent Multimodal Large Language Models (MLLMs) have demonstrated impressive performance across language and vision-language tasks, existing benchmarks primarily measure recognition-based skills and inadequately assess true visual reasoning capabilities. To bridge this critical gap, we introduce VERIFY, a benchmark explicitly designed to isolate and rigorously evaluate the visual reasoning capabilities of state-of-the-art MLLMs. VERIFY compels models to reason primarily from visual information, providing minimal textual context to reduce reliance on domain-specific knowledge and linguistic biases. Each problem is accompanied by a human-annotated reasoning path, making it the first to provide in-depth evaluation of model decision-making processes. Additionally, we propose novel metrics that assess visual reasoning fidelity beyond mere accuracy, highlighting critical imbalances in current model reasoning patterns. Our comprehensive benchmarking of leading MLLMs uncovers significant limitations, underscoring the need for a balanced and holistic approach to both perception and reasoning. For more teaser and testing, visit our project page (https://verify-eqh.pages.dev/).
Generative AI for Cel-Animation: A Survey
Jan 08, 2025



Traditional Celluloid (Cel) Animation production pipeline encompasses multiple essential steps, including storyboarding, layout design, keyframe animation, inbetweening, and colorization, which demand substantial manual effort, technical expertise, and significant time investment. These challenges have historically impeded the efficiency and scalability of Cel-Animation production. The rise of generative artificial intelligence (GenAI), encompassing large language models, multimodal models, and diffusion models, offers innovative solutions by automating tasks such as inbetween frame generation, colorization, and storyboard creation. This survey explores how GenAI integration is revolutionizing traditional animation workflows by lowering technical barriers, broadening accessibility for a wider range of creators through tools like AniDoc, ToonCrafter, and AniSora, and enabling artists to focus more on creative expression and artistic innovation. Despite its potential, issues such as maintaining visual consistency, ensuring stylistic coherence, and addressing ethical considerations continue to pose challenges. Furthermore, this paper discusses future directions and explores potential advancements in AI-assisted animation. For further exploration and resources, please visit our GitHub repository: https://github.com/yunlong10/Awesome-AI4Animation
Unveiling Visual Perception in Language Models: An Attention Head Analysis Approach
Dec 24, 2024
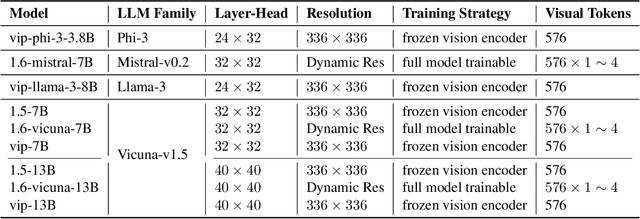

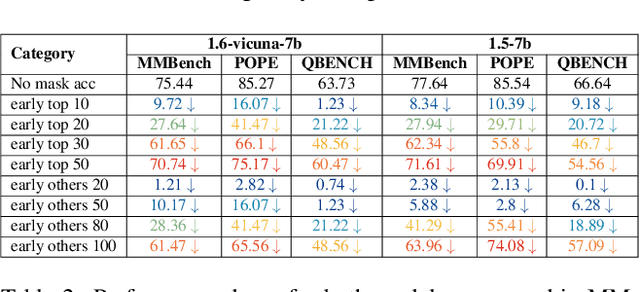
Recent advancements in Multimodal Large Language Models (MLLMs) have demonstrated remarkable progress in visual understanding. This impressive leap raises a compelling question: how can language models, initially trained solely on linguistic data, effectively interpret and process visual content? This paper aims to address this question with systematic investigation across 4 model families and 4 model scales, uncovering a unique class of attention heads that focus specifically on visual content. Our analysis reveals a strong correlation between the behavior of these attention heads, the distribution of attention weights, and their concentration on visual tokens within the input. These findings enhance our understanding of how LLMs adapt to multimodal tasks, demonstrating their potential to bridge the gap between textual and visual understanding. This work paves the way for the development of AI systems capable of engaging with diverse modalities.
VidComposition: Can MLLMs Analyze Compositions in Compiled Videos?
Nov 19, 2024



The advancement of Multimodal Large Language Models (MLLMs) has enabled significant progress in multimodal understanding, expanding their capacity to analyze video content. However, existing evaluation benchmarks for MLLMs primarily focus on abstract video comprehension, lacking a detailed assessment of their ability to understand video compositions, the nuanced interpretation of how visual elements combine and interact within highly compiled video contexts. We introduce VidComposition, a new benchmark specifically designed to evaluate the video composition understanding capabilities of MLLMs using carefully curated compiled videos and cinematic-level annotations. VidComposition includes 982 videos with 1706 multiple-choice questions, covering various compositional aspects such as camera movement, angle, shot size, narrative structure, character actions and emotions, etc. Our comprehensive evaluation of 33 open-source and proprietary MLLMs reveals a significant performance gap between human and model capabilities. This highlights the limitations of current MLLMs in understanding complex, compiled video compositions and offers insights into areas for further improvement. The leaderboard and evaluation code are available at https://yunlong10.github.io/VidComposition/.